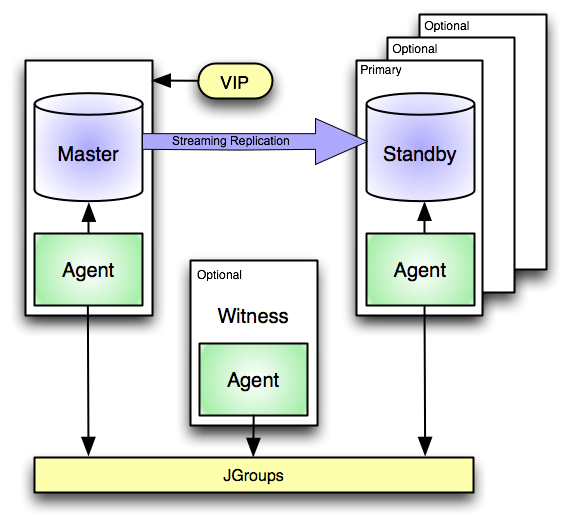
伝統的に、 クラスタ は複数のデータベースを管理するPostgresの単一インスタンスです。このドキュメントでは、クラスタという用語はフェールオーバーマネージャクラスタを指します。 Failover Managerクラスタは、マスターエージェント、1つ以上のスタンバイエージェント、およびクラウド内のサーバー上または従来のネットワーク上に存在し、JGroupsツールキットを使用して通信するオプションのWitnessエージェントから構成されます。
1 はじめに
1.1 新機能
伝統的に、 クラスタ は複数のデータベースを管理するPostgresの単一インスタンスです。このドキュメントでは、クラスタという用語はフェールオーバーマネージャクラスタを指します。 Failover Managerクラスタは、マスターエージェント、1つ以上のスタンバイエージェント、およびクラウド内のサーバー上または従来のネットワーク上に存在し、JGroupsツールキットを使用して通信するオプションのWitnessエージェントから構成されます。
2.2 前提条件
クラスタ _ 名 。 properties ファイルには、Failover Managerクラスタの接続プロパティと動作を指定するパラメータが含まれています。プロパティ設定への変更は、Failover Managerの起動時に適用されます。以下のプロパティのうち1つだけが必要です。サービス名を指定した場合、EFMは 必要に応じ てサービスコマンドを 使用し てデータベースサーバを制御します。 Postgresの bin ディレクトリの 場所を指定した場合 、EFMは データベースサーバを制御 するために pg _ ctl を 使用し ます。EFMは、検索または 回復を 作成するするデータディレクトリ 。 conf ファイル:プロダクションクラスタを設定するときは、システムの設定と使用方法に応じて、次のプロパティが true または falseなります。 EFMテストクラスターを構成している場合は 、両方を true に 設定して 起動を簡単にします。クラスタ _ 名 .nodes fileは起動時に読み込まれ、エージェントにクラスタの残りの部分を見つける方法を指示するか、最初に起動されたノードの場合は後続のノードの認証を単純化するために使用できます。Failover Managerエージェントは efm 内容を確認しません 。 nodes ファイル。エージェントは、ファイル内の一部のアドレスに到達できないことを期待しています(たとえば、別のエージェントがまだ開始されていないなど)。 efm 詳細については 。 nodes ファイル、 3.5.2 項を参照 。efm コピーして efm 。 properties そして efm 。 nodes /etc/edb/efm-3.4 へのファイル サンプルクラスタ内の他のノードのディレクトリ。ファイルをコピーし efm 、ファイルが efm : efm によって所有されるようにファイルの所有権を変更します 。 efm 。 次のプロパティを除いて、 properties ファイルはすべてのノードで同じにすることができます。
Failover Managerをインストールするには、EnterpriseDBリポジトリへのアクセスを許可する認証情報も必要です。リポジトリの認証情報を要求するには、EnterpriseDB Advanced にアクセスしてください。 Downloads ページ:次の手順では、EnterpriseDB aptリポジトリを使用してFailover Managerをインストールする手順を説明します。コマンドを使用するときは、 usernameとpasswordをEnterpriseDBから提供された資格情報に置き換えpassword 。sh -c 'echo "deb https:// username : password @apt.enterprisedb.com/$(lsb_release -cs)-edb/ $(lsb_release -cs) main" > /etc/apt/sources.list.d/edb-$(lsb_release -cs).list'
Failover Managerをインストールするには、EnterpriseDBリポジトリへのアクセスを許可する認証情報も必要です。リポジトリの認証情報を要求するには、 Advanced にアクセスしてください。 Downloads ページ:zypperパッケージマネージャを使用して、SLES 12ホストにFailover Managerエージェントをインストールできます 。 zypperはパッケージをインストールするときにパッケージの依存関係を満たそうとしますが、EnterpriseDBでホストされていない特定のリポジトリにアクセスする必要があります。コマンドは /etc/zypp/repos.dディレクトリにリポジトリ設定ファイルを作成します 。次に、次のコマンドを使用してSLESホスト上のメタデータを更新し、EnterpriseDBリポジトリを含めます。zypper install SUSEConnect
SUSEConnect -r registration_number -e user_id
SUSEConnect -p PackageHub/12/x86_64
SUSEConnect -p sle-sdk/12/x86_64
Failover Managerのインストール中に、インストーラは efm という名前のユーザを作成します 。 efm は、通常データベースの所有者またはオペレーティングシステムのスーパーユーザーに制限されている管理機能を実行するための十分な特権がありません。
# Reserved.
#
# Do not edit this file. Changes to the file may be overwritten
# during an upgrade.
#
# This file assumes you are running your efm cluster as user
# 'efm'. If not, then you will need to copy this file.
# Allow user 'efm' to sudo efm_db_functions as either 'postgres'
# or 'enterprisedb'. If you run your db service under a
# non-default account, you will need to copy this file to grant
# the proper permissions and specify the account in your efm
# cluster properties file by changing the 'db.service.owner'
# property.
efm ALL=(postgres) NOPASSWD: /usr/edb/efm-3.4 /bin/efm_db_functions
efm ALL=(enterprisedb) NOPASSWD: /usr/edb/efm-3.4 /bin/efm_db_functions
# Allow user 'efm' to sudo efm_root_functions as 'root' to
# write/delete the PID file, validate the db.service.owner
# property, etc.
efm ALL=(ALL) NOPASSWD: /usr/edb/efm-3.4 /bin/efm_root_functions
# Allow user 'efm' to sudo efm_address as root for VIP tasks.
efm ALL=(ALL) NOPASSWD: /usr/edb/efm-3.4 /bin/efm_address
# relax tty requirement for user 'efm'
Defaults:efm !requirettyFailover Managerを使用して postgres または enterprisedb 以外のユーザーが所有するクラスターをモニターしている場合 は、 efm-34 ファイルの コピーを作成し 、ユーザーが efm _ functions スクリプトに アクセスし てクラスターを管理 できるように内容を変更します 。デフォルトでは、Failover Managerはsudoを使用してシステム機能へのアクセスを安全に管理します。フェイルオーバーマネージャーをsudoアクセスなしで実行するように設定することを選択した場合、 root アクセスが依然として以下に必要であることに 注意してください 。sudoを使用せずにFailover Managerを実行するには、Failover Managerに代わって管理機能を実行する権限を持つデータベースプロセス所有者を選択する必要があります。ユーザーは、デフォルトのデータベーススーパーユーザー(たとえば、 enterprisedb または postgres )または別の特権ユーザーになります。ユーザーを選択した後:
cp /etc/edb/efm-3.4/efm.properties.in directory / cluster_name .properties
cp /etc/edb/efm-3.4/efm.nodes.in directory / cluster_name .nodes次に、クラスター・プロパティー・ファイルを修正して、 db 内のユーザーの名前を指定します 。 service 。 ownerプロパティ。また、 db確認する必要があります。 service 。 nameプロパティは空白です。 sudoがないと、 rootアクセスなしでサービスを実行することはできません。/usr/edb/efm-3.4/bin/runefm.sh start|stop directory/cluster_name.propertiesどこ directory/cluster_name.propertiesクラスタのプロパティファイルのフルパスと名前を指定します。デフォルト以外のユーザーがエージェントを制御しているとき、またはefmスクリプトを使用しているときは、必ずユーザーがプロパティーファイルへのefmパスを指定する必要があります。Failover Managerは /usr/edb/efm-3.4/bin/secure/にあるmanage - vip という名前のバイナリを使用して、 sudo特権なしでVIP管理操作を実行します。このスクリプトは、setuidを使用して仮想IPアドレスを管理するために必要な特権を取得します。
3.5 フェールオーバーマネージャの設定efm 。 properties ファイルには、それが存在する個々のノードのプロパティが含まれていますが、 efm は含まれています 。 nodes ファイルには、現在のFailover Managerクラスタメンバーのリストが含まれています。デフォルトでは、インストーラはファイルを /etc/edb/efm-3.4 ディレクトリに 配置します 。3.5.1 クラスタプロパティファイルFailover Managerインストーラは、 efm という名前のクラスタプロパティファイル用のファイルテンプレートを作成します 。 properties 。 in で /etc/edb/efm-3.4 ディレクトリ。 Failover Managerのインストールが完了したら、ファイルの内容を変更する前にテンプレートの作業用コピーを作成する必要があります。たとえば、次のコマンドは efm コピーし efm 。 properties 。 in 、ファイル、名前付きプロパティファイルの作成 efm 。 properties :注意してください。デフォルトでは、Failover Managerはクラスタプロパティファイルが efm.properties という名前であることを期待します 。プロパティファイルに efm 以外の名前を付ける場合 。 properties 変更する場合は、サービススクリプトまたはユニットファイルを変更して、Failover Managerに別の名前を使用するように指示する必要があります。プロパティファイルは root が所有しています 。 Failover Managerサービススクリプトは /etc/edb/efm-3.4 ディレクトリに ファイルを見つけることを期待しています 。プロパティファイルを別の場所に移動する場合は、新しい場所を指定するシンボリックリンクを作成する必要があります。3.5.1.1 クラスタプロパティの指定db 。 指定された user は、フェイルオーバーマネージャーに代わって選択されたPostgreSQLコマンドを呼び出すための十分な特権を持っていなければなりません。詳しくはセクション 2.2 をご覧ください 。db 使用してください 。 service 。 Failover Managerによって管理されているクラスタを所有するオペレーティングシステムユーザーの名前を指定する owner プロパティ。このプロパティは、専用の監視ノードでは必要ありません。# This property tells EFM which OS user owns the $PGDATA dir for
# the 'db.database'. By default, the owner is either 'postgres'
# for PostgreSQL or 'enterprisedb' for EDB Postgres Advanced
# Server. However, if you have configured your db to run as a
# different user, you will need to copy the /etc/sudoers.d/efm-XX
# conf file to grant the necessary permissions to your db owner.
#
# This username must have write permission to the
# 'db.recovery.conf.dir' specified below.データベースサービスの名前を db 指定します 。 service 。 service 時または停止時に service または systemctl コマンド を使用する場合は、 name プロパティ 。データベースサービスを起動または停止するたびに 、同じサービス制御メカニズム( pg _ ctl 、 service 、または systemctl )を使用する必要があります。 pg _ ctl プログラムを 使用し てサービスを制御する 場合 は、 db 内 の pg _ ctl プログラムの 場所を指定します 。 bin プロパティdb 使用してください 。 recovery 。 conf 。 クラスターのマスターノード上のリカバリファイルの dir を指定する dir プロパティ。スタンバイ上のトリガーファイルの書き込み先。このプロパティは、専用の監視ノードでは必要ありません。# Use the jdbc.sslmode property to enable ssl for EFM
# connections. Setting this property to anything but 'disable'
# will force the agents to use 'ssl=true' for all JDBC database
# connections (to both local and remote databases).
# Valid values are:
#
# disable - Do not use ssl for connections.
# verify-ca - EFM will perform CA verification before allowing
# the certificate.
# require - Verification will not be performed on the server
# certificate.
jdbc.sslmode=disable通知を 使用してください 。 Failover Managerがユーザー通知を送信する、または通知スクリプトが呼び出されるときの最小の重大度を指定する level プロパティ。通知の完全なリストについては、セクション 7 を参照してください 。script.notification プロパティを 使用し て、通知サービスとして機能するユーザー指定のスクリプトへのパスを指定します。スクリプトにはメッセージの件名とメッセージの本文が渡されます。このスクリプトは、Failover Managerがユーザー通知を生成するたびに呼び出されます。# Absolute path to script run for user notifications.
#
# This is an optional user-supplied script that can be used for
# notifications instead of email. This is required if not using
# email notifications. Either/both can be used. The script will
# be passed two parameters: the message subject and the message
# body.bind 。 address プロパティは、Failover Managerクラスタの現在のノードにあるエージェントのIPアドレスとポート番号を指定します。# This property specifies the ip address and port that jgroups
# will bind to on this node. The value is of the form
# <ip>:<port>.
# Note that the port specified here is used for communicating
# with other nodes, and is not the same as the admin.port below,
# used only to communicate with the local agent to send control
# signals.
# For example, <provide_your_ip_address_here>:7800を設定し is 。 現在のノードがミラーリング監視ノードであることを示すには、 プロパティ witness を true します。場合が is 。 witness は true である、ローカルエージェントはローカルデータベースが実行されているかどうか確認しない。Postgres pg_is_in_recovery() 関数はデータベースの回復状態を報告するブール関数です。 データベースがリカバリ中の場合、 この関数は true 返し true 。データベースがリカバリ中でない場合、 false 返し true 。エージェントが起動すると、ローカルデータベースに接続して pg_is_in_recovery() 関数 を呼び出します 。サーバーが true と 応答した true 、エージェントはスタンバイの役割を引き受けます。サーバーが false と 応答し false 場合、エージェントはマスターの役割を引き受けます。ローカルデータベースがない場合、エージェントはアイドル状態になります。local 。 period プロパティは、データベースサーバへの接続試行の間隔を秒数で指定します。
local 。 timeout プロパティは、エージェントがローカルデータベースサーバーからの肯定的な応答を待つ時間を指定します。
local 。 timeout.final プロパティは、現在のノードのデータベースサーバに最後に接続しようとした後にエージェントが待機する時間を指定します。応答は、で指定した秒数以内にデータベースから受信されていない場合は local 。 timeout.final プロパティは、データベースが失敗したと見なされます。たとえば、これらのプロパティのデフォルト値を指定すると、ローカルデータベースのチェックは10秒ごとに1回行われます。ローカルデータベースへの接続試行が60秒以内に元に戻らない場合、Failover Managerはデータベースへの最後の接続試行を試みます。応答が10秒以内に受信されない場合、Failover Managerはデータベース障害を宣言し、 user リストされている管理者に通知し user 。 email プロパティ。これらのプロパティは、専用の監視ノードには必要ありません。remote 使用してください 。 timeout プロパティ。エージェントがリモートデータベースサーバからの応答を待つ秒数(つまり、フェールオーバーを実行する前に、スタンバイエージェントがマスターデータベースが実際に停止していることを確認するまでの待機時間)を指定します。node 使用してください 。 ノードが失敗したかどうかを判断するときにエージェントがノードからの応答を待つ秒数を指定する timeout プロパティ。 node 。 timeout プロパティ値は、エージェント間通信のタイムアウト値を指定します。クラスター・プロパティー・ファイル内の他のタイムアウト・プロパティーは、エージェントからデータベースへの通信のための値を指定します。# The total amount of time in seconds to wait before determining
# that a node has failed or been disconnected from this node.
#
# The value of this property must be the same across all agents.stop 使用してください 。 isolated 。 masterエージェントが分離されていることをマスターエージェントが検出した場合にフェールオーバーマネージャーにデータベースをシャットダウンするように指示するmasterプロパティ。 true (デフォルト)の場合、Failover Managerはスクリプトで指定されたscriptを呼び出す前にデータベースを停止します。 master.isolatedプロパティ停止を 使用してください 。 失敗しました 。 フェールオーバーマネージャがマスターデータベースにアクセスできない場合にマスターデータベースのシャットダウンを試みるように指示する master プロパティ。 trueの 場合 、フェイルオーバーマネージャーは、データベースを停止しようとした後script.db.failureプロパティで指定されたスクリプトを実行します。master 使い master 。 shutdown ます。 as 。 マスターノード上のFailover Managerエージェントのシャットダウンが失敗として扱われるべきであることを示す failure パラメーター。このパラメーターが true 設定され ていてマスターエージェントが(なんらかの理由で)停止した場合、クラスターはマスターノード上のデータベースが稼働しているかどうかを確認しようとします。master 。 shutdownます。 as 。 failureプロパティは、マスターノードが誤ってシャットダウンされるなど、障害ではなくユーザーエラーを検出するためのものです。ユーザーがマスターFailover Managerエージェントを停止したように、ノードの適切なシャットダウンが残りのクラスターに表示されることがあります(例えば、マスターデータベースの保守を実行するため)。 masterを設定すれば。 shutdownます。 as 。 failureプロパティがtrue場合、メンテナンスを実行するときは注意が必要です。masterデータベースを master メンテナンスする 。 shutdownます。 as 。 failureあるtrue 、あなたはマスターエージェントを停止し、マスターエージェントが失敗したが、データベースがまだ実行されている通知を受信するのを待つ必要があります。それからmasterデータベースを停止しても安全です。あるいは、 efm stop - clusterコマンドを使用して、障害チェックを実行せずにすべてのエージェントを停止することもできます。使用 auto.allow.hosts 中で指定されたアドレスを使用するようにサーバーに指示するプロパティを。 最初のノードの nodes ファイルが許可ホストリストの更新を開始しました。このプロパティを(設定有効にすると auto 。 allow 。 hosts に true )クラスタの起動を簡素化することができます。厩舎を 使用してください 。 ノード 。 ノードがクラスターに参加または離脱したときにノードファイルを書き換えないようにサーバーに指示する file プロパティ。このプロパティは、IPアドレスが変更されていないクラスタで最も役立ちます。db.reuse.connection.count プロパティは倍のフェールオーバーマネージャーの数を指定するには、管理者がデータベースの状態をチェックするために、同じデータベース接続を再利用することができます。デフォルト値は 0 。これは、Failover Managerが毎回新しい接続を作成することを示します。このプロパティは、専用の監視ノードでは必要ありません。auto.failover プロパティは、自動フェイルオーバーを可能にします。デフォルトでは、 auto です。 failover は true 設定されてい true 。# Whether or not failover will happen automatically when the master
# fails. Set to false if you want to receive the failover notifications
# but not have EFM actually perform the failover steps.
# The value of this property must be the same across all agents.auto 使用してください 。 プライマリスタンバイがマスターに昇格した後、残りのスタンバイサーバーの自動再設定を有効または無効にするようにフェールオーバーマネージャーに指示するためのプロパティを reconfigure ます。プロパティを設定し true 自動再構成(デフォルト)または有効にするために false 自動再構成を無効にします。このプロパティは、専用の監視ノードでは必要ありません。# After a standby is promoted, failover manager will attempt to
# update the remaining standbys to use the new master. Failover
# manager will back up recovery.conf, change the host parameterPlease note: primary_conninfo is a space-delimited list of keyword=value pairs. is a space-delimited list of pairs.Please note: If you are replication slots to manage your WAL segments, automatic reconfiguration is not supported; you should set 使用し Please note: If you are replication slots to manage your WAL segments, automatic reconfiguration is not supported; you should set auto replication slots to manage your WAL segments, automatic reconfiguration is not supported; you should set . false reconfigure to false . For more information, see Section 2.2 . For more information, see Section .promotable プロパティを 使用し て、ノードをプロモートしないように指示します。設定を上書きするには、 実行時に efm set-priority コマンドを使用します。詳細については、 efm set-priority コマンドは、セクションを参照 5.3 。minimum.standbys プロパティを 使用 して、クラスタに保持されるスタンバイノードの最小数を指定します。スタンバイカウントが指定された最小値まで低下すると、マスターノードに障害が発生してもレプリカノードはプロモートされません。auto.resume.period プロパティを 使用し て、エージェントがそのデータベースの監視を再開しようとする秒数(監視対象データベースが失敗し、エージェントがアイドル状態になった後、またはIDLEモードで起動した後)を指定します。Failover Managerは、仮想IPを使用するクラスタをサポートします。クラスタが仮想IPを使用している場合は、 virtualIp プロパティに ホスト名またはIPアドレスを 入力し ます。 virtualIpに 対応するプレフィックスを指定します 。 接頭辞 プロパティ。 virtualIp が空白のままの 場合 、仮想IPサポートは無効になります。指定された仮想IPアドレスは、クラスタのマスターノードにのみ割り当てられます。 virtualIp を指定した場合 single = trueの場合 、フェイルオーバーが発生した場合、新しいVIPに同じVIPアドレスが使用されます。クラスターの各ノードに固有のIPアドレスを指定するには、値falseを指定してください。# These properties specify the IP and prefix length that will be
# remapped during failover. If you do not use a VIP as part of
# your failover solution, leave the virtualIp property blank to
# disable Failover Manager support for VIP processing (assigning,
# releasing, testing reachability, etc).
#
# If you specify a VIP, the interface and prefix are required.
#
# If specify a host name, it will be resolved to an IP address
# when acquiring or releasing the VIP. If the host name resolves
# to more than one IP address, there is no way to predict which
# address Failover Manager will use.
#
# By default, the virtualIp and virtualIp.prefix values must be
# the same across all agents. If you set virtualIp.single to
# false, you can specify unique values for virtualIp and
# virtualIp.prefix on each node.
#
# If you are using an IPv4 address, the virtualIp.interface value
# should not contain a secondary virtual ip id (do not include
# ":1", etc).check 設定して check 。 vip 。 before 。 promotion へのプロパティ false のフェイルオーバーマネージャーは、VIPは障害が発生した場合にAA新しいマスタに割り当てる前に使用されているかどうかをチェックしないことを示すために。これにより、同じVIPアドレスで複数のノードがブロードキャストされる可能性があります。マスターノードが分離されているか、別のプロセスでシャットダウンできる場合を除き、このプロパティを true 設定する必要があり true 。script.load.balancer.attachプロパティーの後にスクリプト名を指定して 、ノードをロードバランサーに接続する必要があるときに呼び出されるスクリプトを識別します。ノードをロードバランサから切り離す必要があるときに呼び出されるスクリプトの名前を指定するには、 script.load.balancer.detachプロパティを使用します。クラスタに接続または削除されているノードのIPアドレスを表すために、 %hプレースホルダを含めます。# Absolute path to load balancer scripts
# The attach script is called when a node should be attached to
# the load balancer, for example after a promotion. The detach
# script is called when a node should be removed, for example
# when a database has failed or is about to be stopped. Use %h to
# represent the IP/hostname of the node that is being
# attached/detached.
#
# Example:
# script.load.balancer.attach=/somepath/attachscript %h# absolute path to fencing script run during promotion
#
# This is an optional user-supplied script that will be run
# during failover on the standby database node. If left blank,
# no action will be taken. If specified, EFM will execute this
# script before promoting the standby.
#
# Parameters can be passed into this script for the failed master
# and new primary node addresses. Use %p for new primary and %f
# for failed master. On a node that has just been promoted, %p
# should be the same as the node's efm binding address.
#
# Example:
# script.fence=/somepath/myscript %p %f
#
# NOTE: FAILOVER WILL NOT OCCUR IF THIS SCRIPT RETURNS A NON-ZERO EXIT CODE.# Absolute path to fencing script run after promotion
#
# This is an optional user-supplied script that will be run after
# failover on the standby node after it has been promoted and
# is no longer in recovery. The exit code from this script has
# no effect on failover manager, but will be included in a
# notification sent after the script executes.
#
# Parameters can be passed into this script for the failed master
# and new primary node addresses. Use %p for new primary and %f
# for failed master. On a node that has just been promoted, %p
# should be the same as the node's efm binding address.
#
# Example:
# script.post.promotion=/somepath/myscript %f %pscript 使用してください 。 db 。 エージェントがモニターするデータベースに failure ことをエージェントが検出した場合にFailover Managerが呼び出すオプションのユーザー提供スクリプトへの絶対パスを指定する failure プロパティー。script 使用してください 。 master 。 マスターデータベースを監視しているエージェントが、マスターがフェールオーバーマネージャークラスターの大部分から分離されていることを検出した場合に、フェールオーバーマネージャーが呼び出すオプションのユーザー指定スクリプトへの絶対パスを指定するための isolated プロパティ このスクリプトは、VIPが解放された直後に呼び出されます(VIPが使用中の場合)。script 使用してください 。 remote 。 pre 。 ノードがデータベースをマスターに昇格させようとしているときに、昇格に関与していないエージェントノードで呼び出されるスクリプトのパスと名前を指定する promotion プロパティ。script 使用してください 。 remote 。 post 。 promotion 促進の発生後にマスター以外のノードで呼び出されるスクリプトのパスと名前を指定する promotion プロパティー。使用 script.custom.monitor 定期的に呼び出されるオプションのスクリプトの名前と場所を提供するプロパティを(で秒単位で指定し custom 。 monitor 。 interval プロパティ)。custom 使用してください 。 monitor 。 スクリプトの実行が許可される最大時間を指定する timeout 。指定された時間内にスクリプトの実行が完了しない場合、Failover Managerは通知を送ります。設定し custom 。 monitor 。 safe です。 フェールオーバーマネージャがスクリプトからゼロ以外の終了コードを報告するように指示し、終了コードの結果としてスタンバイを昇格させないように指示 するには、 mode を true に mode し true 。sudo 使ってください 。 拡張権限を必要とするタスクを実行するときにFailover Managerによって呼び出されるコマンドを指定する command プロパティー。システム認証に固有のコマンドオプションを含めるには、このオプションを使用します。sudo 使ってください 。 user 。 データベース所有者によって実行されるコマンドを実行するときにFailover Managerによって呼び出されるコマンドを指定する command プロパティー。ロックを 使用してください 。 Failover Managerロックファイルの代替場所を指定する dir プロパティ。このファイルは、Failover Managerがノード上の単一のクラスタに対して複数の(孤立している可能性がある)エージェントを起動するのを防ぎます。Failover ManagerホストでUDPまたはTCPプロトコルを有効にした後は、syslogへのロギングを有効にできます。 syslogを 使用してください 。 プロトコルタイプ(UDPまたはTCP)とsyslogを指定するprotocolパラメータ。 syslogホストのリスナーポートを指定するportパラメータ。 syslogです。 facility値は、エントリを作成したプロセスの識別子として使用できます。値はLOCAL0とLOCAL7の間になければなりません。file 使用してください 。 log 。 enabled 、 syslog 。実装したいロギングのタイプを指定するためのenabledなプロパティ。設定file log 。ファイルへのロギングをenabledするにはtrueに有効にします。 UDPプロトコルまたはTCPプロトコルを有効にしてsyslogを設定します。 syslogへのロギングをenabledするには、 trueにenabledしtrue 。ファイルとsyslogの両方へのロギングを有効にできます。
3.5.1.2 データベースパスワードの暗号化Failover Managerでは、データベースのパスワードをクラスタプロパティファイルに含める前に暗号化する必要があります。 efm ユーティリティ( efm ます)を 使用 して /usr/edb/efm-3.4 /bin パスワードを暗号化するためのディレクトリ)。パスワードを暗号化するときは、ユーティリティを起動するときにコマンドラインでパスワードを渡すか、または EFMPASS 環境変数を 使用でき ます。export EFMPASS= password--from-env オプションを 含めない 場合、フェールオーバーマネージャーは、データベースのパスワードを2回入力するように求めてから、クラスターのプロパティファイルに暗号化されたパスワードを生成します。ユーティリティが暗号化パスワードを共有したら、暗号化パスワードをコピーしてクラスタプロパティファイルに貼り付けます。注意してください: 多くのJavaベンダーはフル強度の暗号化を含んだ彼らのバージョンのJavaを出荷しますが、輸出規制のために可能にされません。データベースパスワードを暗号化しようとしたときに不正なキーサイズに関するエラーが発生した場合は、プラットフォームに無制限のポリシーを提供するJava Cryptography Extension(JCE)をダウンロードして有効にする必要があります。# efm encrypt acctg
This utility will generate an encrypted password for you to place in your EFM cluster property file:
/etc/edb/efm-3.4/acctg.properties
Please enter the password and hit enter:
Please enter the password again to confirm:
The encrypted password is: 516b36fb8031da17cfbc010f7d09359c
Please paste this into your acctg.properties file
db.password.encrypted=516b36fb8031da17cfbc010f7d09359c次の例は 、パスワードを暗号化するときに --from-env 環境変数 を使用する方法を示してい ます。 efm を起動する前に encrypt コマンドで、 EFMPASS の値を パスワード( 1safepassword ) に設定します 。暗号化されたパスワード( 7ceecd8965fa7a5c330eaa9e43696f83 )はテキスト値として返されます。スクリプトを使用するときは、コマンドの終了コードを確認して、コマンドが成功したことを確認できます。正常に実行された場合、 0 が返され 0 。
3.5.2 クラスタメンバーファイルFailover Managerクラスタ内の各ノードには、クラスタメンバーファイルがあります。エージェントは起動時に、そのファイルを使用して他のクラスタメンバーを見つけます。 Failover Managerインストーラは、 efm という名前のクラスタメンバーファイル用のファイルテンプレートを作成します 。 nodes.in で /etc/edb/efm-3.4 ディレクトリ。 Failover Managerのインストールが完了したら、テンプレートの作業用コピーを作成する必要があります。デフォルトでは、Failover Managerはクラスタメンバーファイルの名前が efm あると efm ます。 nodes 。クラスタメンバーに efm 以外の efm ます。 nodes がある場合は、Failover Managerサービススクリプトを変更して、Failover Managerに新しい名前を使用するように指示する必要があります。最初に起動したノードのクラスタメンバーファイルは空にすることができます。このノードがメンバーシップコーディネーターになります。後続の各ノードで、クラスタメンバーファイルには、メンバーシップコーディネーターのアドレスとポート番号が含まれている必要があります。クラスタメンバーファイルの各エントリは、 address : port 形式で、複数のエントリを空白で区切って並べてください。メンバーシップコーディネーターが efm の内容を更新し ます。 クラスタの現在のメンバーに一致する nodes ファイル。エージェントがクラスタに参加するか、クラスタから脱退すると、 efm です。 他のエージェントの nodes ファイルは、現在のクラスタメンバーシップを反映するように更新されます。あなたが起動した場合 efm stop-cluster コマンドを、フェイルオーバーマネージャーは、ファイルを変更しません。メンバーシップコーディネーターがクラスターを離れると、別のノードがその役割を引き継ぎます。あなたは efm を使うことができます Membership Coordinatorのアドレスを見つけるための cluster - status コマンド。エージェントの停止中にノードがクラスタに参加またはクラスタから脱退する場合は、ファイルに少なくとも現在のメンバーシップコーディネーターが含まれていることを手動で確認する必要があります。クラスタに参加するノードのIPアドレスとポートがわかっている場合は、いつでもそのアドレスをクラスタメンバーファイルに含めることができます。起動時に、クラスタメンバーを識別しないアドレスは、 auto ない限り無視され ます。 allow ます。 クラスタプロパティファイルの hosts プロパティが true 設定されて true 。詳細はセクション 4.1.2を 参照してください 。
root ユーザー として efm _ address スクリプトを 呼び出す必要があり ます。 efm ユーザーは、インストール時に作成され、中に権限が付与された sudoers 実行するファイル efm _ address スクリプトを。 sudoers ファイルの 詳細については 、セクション3.4 、 フェールオーバーマネージャの権限の拡張を 参照してください 。注意:VIPに使用されるネットワークインターフェースは、Failover Managerエージェントの bind 使用されるインターフェースと同じである必要はありません 。 address 値マスターエージェントはフェールオーバー中に必要に応じてVIPをドロップし、フェールオーバーマネージャはスタンバイを昇格させる前にVIPが使用できなくなったことを確認します。バインドアドレスネットワークに障害が発生すると、マスターの分離とフェールオーバーが発生します。VIPが別のインターフェイスを使用している場合は、マスターエージェントがドロップする前に、残りのクラスタが到達可能なVIPをチェックするというタイミング条件が発生する可能性があります。この場合、EFMは node 指定された秒数の間VIPチェックを再試行し node 。 フェイルオーバーが予想どおりに行われるようにするための timeout プロパティ。
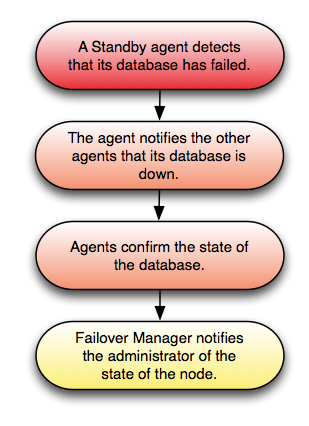
マスターノードが再起動した場合、フェールオーバーマネージャーはデータベースがマスターノードで停止していることを検出し、スタンバイノードをマスターの役割に昇格させます。これが発生した場合、(再起動された)マスターノード上のFailover Managerエージェントは recovery を書き込む機会を得られません 。 conf ファイル再起動したマスターノードは、2番目のマスターノードとしてクラスターに戻ります。これを防ぐには、データベースサーバを起動する前にFailover Managerエージェントを起動します。エージェントはアイドルモードで起動し、クラスタにマスターがすでに存在するかどうかを確認します。マスターノードがある場合、エージェントはその recovery を確認し ます。 conf ファイルが存在し、データベースが2番目のマスターとして起動しません。
デフォルトでは、以下にリストされているコマンドのいくつかは、 efm またはOSスーパーユーザーによって 呼び出される必要があり ます。管理者は、ユーザーを efm グループに 追加することによって、ユーザーにこれらのコマンドの呼び出しを選択的に許可することができます 。コマンドは以下のとおりです。4.1.1 Failover Managerクラスタの起動ノードが専用の pg_is_in_recovery() ノードではない場合、Failover Managerはローカルデータベースに接続して pg_is_in_recovery() 関数 を呼び出し ます。サーバーが false と 応答し false 場合、エージェントはノードをマスターノードと見なし、仮想IPアドレスをノードに割り当てます(該当する場合)。サーバーが true と 応答した true 、Failover Managerエージェントはノードがスタンバイサーバーであると見なします。サーバーが応答しない場合、エージェントはアイドル状態で起動します。4.1.2 クラスタへのノードの追加
Failover Manager efm cluster-status コマンドまたはPEM Clientのグラフィカルインターフェイスを使用して、Failover Managerクラスタの監視対象ノードの現在のステータスを確認できます。4.2.1 クラスタステータスレポートの確認cluster - status コマンドは、フェールオーバーマネージャークラスタのステータスに関する情報を含むレポートを返します。コマンドを呼び出すには、次のように入力します。次のステータスレポートは、クラスタの名前です edb 実行されている4つのノードがあります。efm cluster-status efm
Cluster Status: efm
Agent Type Address Agent DB VIP
-----------------------------------------------------
Witness 172.19.12.170 UP N/A
Master 172.19.13.105 UP UP 172.19.13.107*
Standby 172.19.13.113 UP UP 172.19.13.106
Standby 172.19.14.106 UP UP 172.19.13.108
Allowed node host list:
172.19.12.170 172.19.13.113 172.19.13.105 172.19.14.106
Membership coordinator: 172.19.12.170
Standby priority host list:
172.19.13.113 172.19.14.106
Promote Status:
DB Type Address XLog Loc Info
-------------------------------------------------------
Master 172.19.13.105 0/31000140
Standby 172.19.13.113 0/31000140
Standby 172.19.14.106 0/31000140
Standby database(s) in sync with master. It is safe to promote.Cluster Status セクションには、クラスタの各ノードに存在するエージェントのステータスの概要が表示されます。Cluster Status: efm
Agent Type Address Agent DB VIP
-----------------------------------------------------
Witness 172.19.12.170 UP N/A
Master 172.19.13.105 UP UP 172.19.13.107*
Standby 172.19.13.113 UP UP 172.19.13.106
Standby 172.19.14.106 UP UP 172.19.13.108
Allowed node host list と Standby priority host list 使用すると、どのノードがクラスタに参加できるか、およびノードの昇格順序を簡単に判断できます。 Membership のIPアドレス coordinator もレポートに表示されます。Allowed node host list:
172.19.12.170 172.19.13.113 172.19.13.105 172.19.14.106
Membership coordinator: 172.19.12.170
Standby priority host list:
172.19.13.113 172.19.14.106Promote レポートの Status セクションは、 cluster - status コマンドを 呼び出しているノードから cluster 各データベースへの 直接照会の結果 です。クエリは各データベースのトランザクションログの場所も返します。Promote Status:
DB Type Address XLog Loc Info
-------------------------------------------------------
Master 172.19.13.105 0/31000140
Standby 172.19.13.113 0/31000140
Standby 172.19.14.106 0/31000140
Standby master. in sync with
Standby database(s) master. It is safe to promote.データベースが停止している(またはデータベースが再起動されているのに resume コマンドがまだ呼び出されていない)場合、そのホストに存在するエージェントの状態は Idle ます。エージェントがアイドル状態の場合、クラスタステータスレポートにはアイドルノードの状態の概要が含まれます。Agent Type Address Agent DB VIP
-----------------------------------------------------
Idle 172.19.18.105 UP UP 172.19.13.105
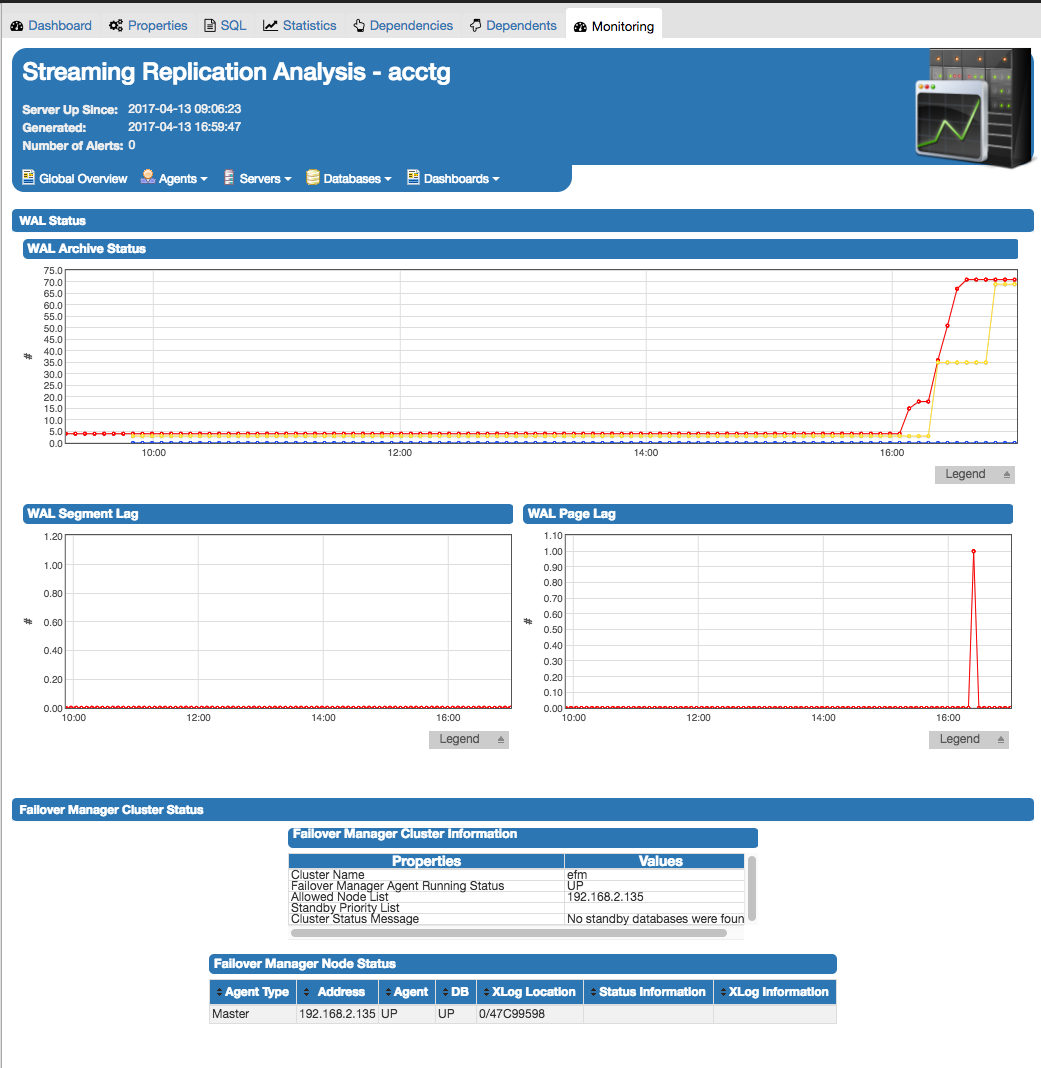 ストリーミングレプリケーション分析ダッシュボード(図4.1に示す)には、ストリーミングレプリケーションが有効になっている監視対象サーバーのアクティビティに関する統計情報が表示されます。ダッシュボードのヘッダを監視サーバのステータスを特定する(いずれかの Replication Master または Replication Slave )、およびサーバは、最後のページが最後に更新された日付と時刻を開始し、サーバーのトリガーアラートの現在のカウントされた日付と時刻を表示します。
ストリーミングレプリケーション分析ダッシュボード(図4.1に示す)には、ストリーミングレプリケーションが有効になっている監視対象サーバーのアクティビティに関する統計情報が表示されます。ダッシュボードのヘッダを監視サーバのステータスを特定する(いずれかの Replication Master または Replication Slave )、およびサーバは、最後のページが最後に更新された日付と時刻を開始し、サーバーのトリガーアラートの現在のカウントされた日付と時刻を表示します。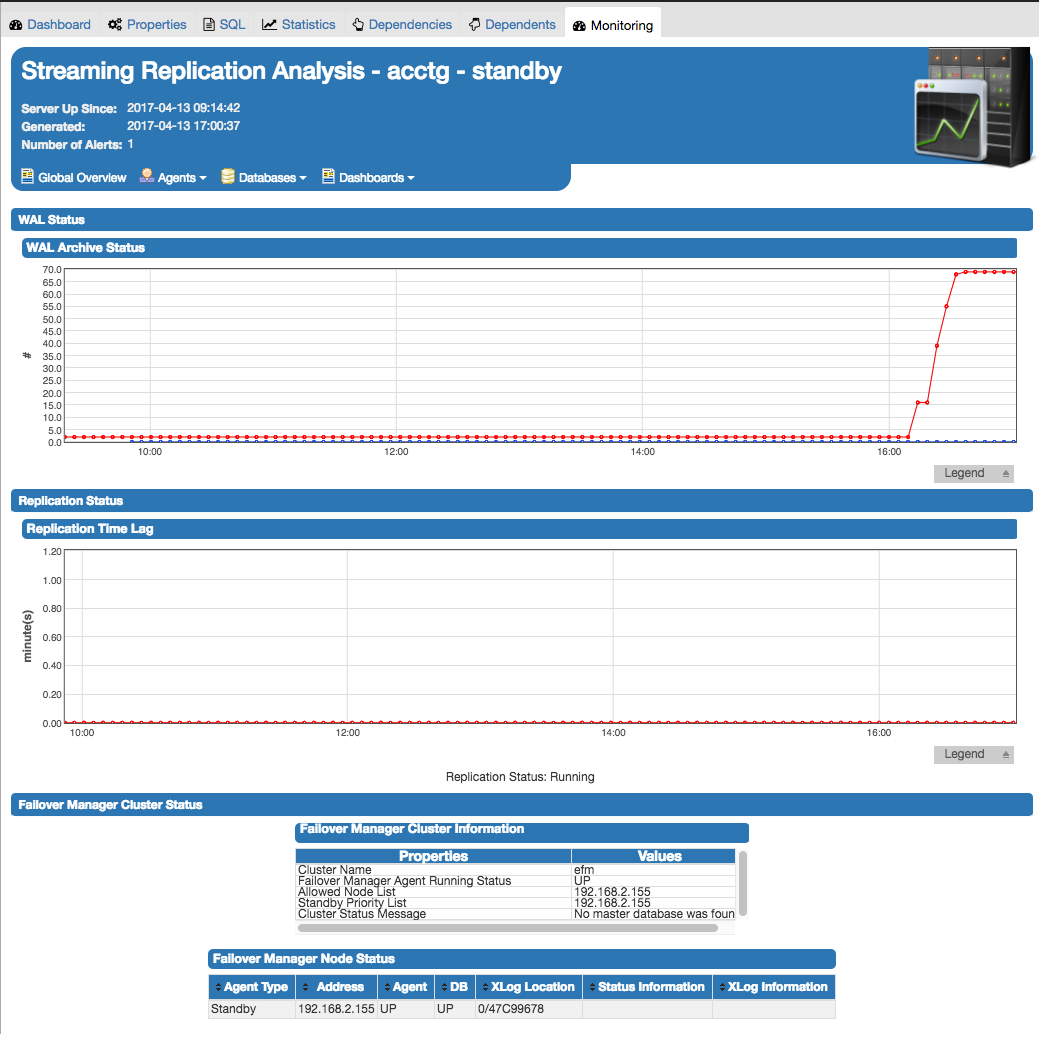
bind.address
db.port
db.recovery.conf.dir
virtualIp (使用されている場合)
virtualIp.interface (使用されている場合)各クラスター・プロパティー・ファイル内で、 db.port パラメーターは各クラスターごとに固有の値を指定しますが、 db はその db.port です。 user と db 。 database パラメータは同じ値または一意の値を持つことができます。たとえば、 acctg です。 properties ファイルは次のように指定します。各クラスターのクラスター・プロパティー・ファイルを作成するときは、 db 。 recovery 。 conf 。 dir パラメータは、それぞれのデータベースクラスタごとに一意の値も指定する必要があります。このパラメータ値は、使用されている仮想IPアドレスによって決定され、両方の acctg 同じ場合も acctg ば、同じでない場合もあります 。 properties と sales 。 properties 。acctg 作成した後 。 properties と sales 。 properties ファイル。クラスタごとに、それぞれのプロパティファイルを指すサービススクリプトまたはユニットファイルを作成します。この手順はプラットフォームによって異なります。 RHEL 6.xまたはCentOS 6.xを使用している場合は、 4.3.1 項を参照してください 。 RHEL 7.xまたはCentOS 7.xを使用している場合は、 4.3.2 項を参照してください 。4.3.1 RHEL 6.xまたはCentOS 6.x4.3.2 RHEL 7.xまたはCentOS 7.xRHEL 7.xまたはCentOS 7.xを使用している場合は、 efm-3.4 ユニットファイルを各クラスタに固有の名前で新しいファイルに コピーする必要 があります。たとえば、2つのクラスタ(名前が acctg と sales )がある場合、ユニットファイル名は次のようになります。
RHEL 6.xおよびCentOS 6.xでは、Failover Manager は /etc/init.d ある efm-3.4 (デフォルト)という名前のLinuxサービスとして動作します 。 Failover Managerによって監視されている各データベースクラスタは、レプリケーションクラスタの各ノードでサービスのコピーを実行します。start コマンドは、現在のノード上のフェールオーバーマネージャー・エージェントを開始します。ローカルFailover Managerエージェントはローカルデータベースを監視し、他のノード上のFailover Managerと通信します。 Failover Managerクラスタ内のノードは任意の順序で起動できます。statusコマンドは、呼び出されたFailover Managerエージェントのステータスを返します。 フェールオーバーマネージャにステータス情報を返すように指示するには、任意のノードで status コマンドを 呼び出し ます。例えば:
RHEL 7.xおよびCentOS 7.xでは、Failover Manager は / usr / lib /systemd/system (デフォルトで) efm-3.4.service という名前のLinuxサービスとして実行されます 。 Failover Managerによって監視されている各データベースクラスタは、レプリケーションクラスタの各ノードでサービスのコピーを実行します。start コマンドは、現在のノード上のフェールオーバーマネージャー・エージェントを開始します。ローカルFailover Managerエージェントはローカルデータベースを監視し、他のノード上のFailover Managerと通信します。 Failover Managerクラスタ内のノードは任意の順序で起動できます。statusコマンドは、呼び出されたFailover Managerエージェントのステータスを返します。 任意のノードで status コマンドを 呼び出して、 ステータスとサーバの起動情報を返すようにFailover Managerに指示 することができ ます。
5.3 efmユーティリティを使うFailover Managerには、 クラスタ管理を支援するため の efm ユーティリティがあります。 Failover Managerをインストールすると、RPMインストーラによって /usr/edb/efm-3.4/binディレクトリにユーティリティが追加されます 。efm allow-node cluster_nameefm cluster-status cluster_nameFailover Managerクラスタのステータスを表示するに は、 efm cluster-status コマンドを 呼び出し ます。クラスタステータスレポートの詳細については、 4.2.1 項を 参照してください 。efm cluster-status-json cluster_nameefm cluster-status-json コマンドを 呼び出して 、Failover Managerクラスタのステータスをjson形式で表示します。表示される情報の形式は efm によって生成される表示とは異なりますが cluster - status コマンド、情報源は同じです。{
"nodes": {
"172.16.144.176": {
"type": "Witness",
"agent": "UP",
"db": "N\/A",
"vip": "",
"vip_active": false
},
"172.16.144.177": {
"type": "Master",
"agent": "UP",
"db": "UP",
"vip": "",
"vip_active": false,
"xlog": "2\/77000220",
"xloginfo": ""
},
"172.16.144.180": {
"type": "Standby",
"agent": "UP",
"db": "UP",
"vip": "",
"vip_active": false,
"xlog": "2\/77000220",
"xloginfo": ""
}
},
"allowednodes": [
"172.16.144.177",
"172.16.144.160",
"172.16.144.180",
"172.16.144.176"
],
"membershipcoordinator": "172.16.144.177",
"failoverpriority": [
"172.16.144.180"
],
"minimumstandbys": 0,
"missingnodes": [],
"messages": []
}efm disallow-node cluster_name ip_addressefm 起動する 指定されたノードを許可ホストリストから削除し、そのノードがクラスタに参加しないようにする disallow-node コマンド。 efm 呼び出すときに、クラスタの名前とノードのIPアドレスを指定します。 disallow - node コマンド。このコマンドは、によって呼び出されなければならない efm のメンバー efm group, 又は root 。パスワードをクラスター・プロパティー・ファイルに含める前に 、 efm encrypt コマンドを 呼び出して データベースのパスワードを暗号化してください。 フェールオーバーマネージャに EFMPASS 環境変数で 指定された値を使用し、 ユーザーの入力なしで実行する ように指示 するには、 - from - env オプションを 含めます 。詳細はセクション 3.5.1.2を 参照してください 。promote コマンドをマスターにスタンバイの手動フェイルオーバーを実行するためにフェイルオーバーマネージャーに指示します。スタンバイノードを昇格させるに は –switchover 句を 含め、 マスターノードをスタンバイノードとして再構成します。 - sourcenode キーワードを 含め、 ノード address を指定して、 recovery するノードを示します 。 conf ファイルは古いマスターノードにコピーされます(スタンバイになります)。 スイッチオーバープロセス中の通知を抑制するに は、 - quiet キーワードを 含めます 。efm resume cluster_nameefm set-priority cluster_name ip_address priorityefm 起動する フェールオーバー優先順位をスタンバイノードに割り当てる set-priority コマンド。値は、フェイルオーバーの際に新しいノードが使用される順序を指定します。このコマンドは、によって呼び出されなければならない efm のメンバー efm group, 又は root 。priority は n 整数値です 。ここで、 n はリスト内のスタンバイノードの数です。値 1 を 指定する と、新しいノードがプライマリスタンバイになり、フェールオーバーの際に最初に昇格されるノードになります。 priority の 0 スタンバイを促進しないためにフェールオーバーマネージャーに指示します。efm stop-cluster cluster_nameefm 起動する すべてのノードでフェールオーバーマネージャーを停止 stop-cluster コマンド。このコマンドは、フェールオーバーマネージャーにクラスター上の各ノードに接続し、既存のメンバーにシャットダウンするように指示します。このコマンドは実行中のデータベースには影響しませんが、コマンドが完了した時点ではフェイルオーバー保護は行われていません。efm upgrade-conf コマンドを 呼び出して 、既存のFailover Managerインストールから設定ファイルをコピーし、Failover Manager 3.4のインストールに必要なパラメータを追加します。ユーティリティを起動するときに、前のクラスタの名前を指定します。このコマンドは root 権限 で呼び出す必要があります 。-あなたはsudoを使用していないフェールオーバーマネージャー構成からアップグレードする場合、含める source フラグをしての名前を指定し directory 呼び出すときにコンフィギュレーション・ファイルが存在する upgrade - conf 。
6 ロギングの制御Failover Managerは、エージェントごとに1つのログファイルとエージェントごとに1つの起動ログを /var/log/ cluster_name -3.4 ( cluster _ name は cluster name 指定します)に 書き込み、保存 します。# Logging levels for JGroups and EFM.
# Valid values are: TRACE, DEBUG, INFO, WARN, ERROR
# Default value: INFO
# It is not necessary to increase these values unless debugging a
# specific issue. If nodes are not discovering each other at
# startup, increasing the jgroups level to DEBUG will show
# help
# information about the TCP connection attempts that may help
# diagnose the connection failures.たとえば、 efm を設定したとし efm 。 loglevel パラメータを WARN に 設定すると 、Failover Managerは WARN レベル以上( WARN と ERROR )の メッセージのみをログに記録します 。デフォルトでは、Failover Managerログファイルは毎日ローテーションされ、圧縮され、そして1週間保存されます。ログローテーションファイル( /etc/logrotate.d/efm-3.4 )の 設定を変更して、ファイルローテーションスケジュールを変更できます 。ログローテーションスケジュールの変更の詳細については、 logrotate 参照してください。 man ページ:
syslogへの接続を許可するには、 /etc/rsyslog.confファイルを編集して、使用したいプロトコルのコメントを外します。プロトコルに関連付けられているUDPServerRunまたはTCPServerRunエントリに、ログエントリの送信先となるポート番号が含まれていることも確認する必要があります。Failover Managerホスト上のrsyslog.confファイルを変更した後、ログ記録を有効にするためにFailover Managerのプロパティを変更する必要があります。プロパティファイルを変更するために、エディタの選択を使用してください( /etc/edb/efm-3.4/efm 。 properties 。 in 、実装したいログの種類を指定します):システムのsyslog詳細も指定する必要があります。 syslogを 使用してください 。 プロトコルタイプ(UDPまたはTCP)とsyslogを指定するprotocolパラメータ。 syslogホストのリスナーポートを指定するportパラメータ。 syslog.facility値は、エントリを作成したプロセスの識別子として使用できます。値はLOCAL0とLOCAL7の間になければなりません。syslogの 人
7 通知フェールオーバーマネージャは、クラスタに影響を与える重要なイベントが発生したときに電子メール通知を送信したり、通知スクリプトを呼び出したりします。電子メール通知を送信するようにFailover Managerを設定した場合 は、クラスタの各ノードの ポート 25 で SMTPサーバを実行している必要があり ます。フェールオーバーマネージャの通知動作を設定するには、次のパラメータを使用します。EFM node: 10.0.1.11
Cluster name: acctg
Database name: postgres
VIP: ip _ address (Active|Inactive)
Database health is not being monitored.VIP ノードのために実装されている場合、フィールドには、仮想IPのIPアドレスと状態を表示します。INFO はエージェントに関する情報メッセージを示し、手動操作を必要としません(たとえば、Failover Managerが起動または停止したなど)。WARNING は、管理者にシステムのチェックを要求するイベントが発生したことを示します(たとえば、フェイルオーバーが発生したなど)。SEVERE は、重大なイベントが発生したことを示し、管理者の即時対応が必要です(たとえば、フェイルオーバーが試行されましたが完了できませんでした)。重大度は通知の緊急度を示します。重大度レベルが SEVERE の通知はすぐにユーザーの注意を必要としますが、重大度レベルが INFO 通知 はユーザーの操作を必要としないクラスターに関する運用情報に注意を向けます。通知の重大度はログレベルとは関係ありません。設定ファイルで指定されたログレベルの詳細に関係なく、すべての通知が送信されます。
This error is returned if the server encounters an error when invoking replay during the promotion of a standby.
Output: script_results
Exit Value: exit_code
Results: script_results
Exit Value: exit_code
Results: script_results
Exit Value: exit_code
Results: script_results
The agent will stop monitoring the local database.Script output: script_results
Exit Value: exit_code
Results: script_results
Exit Value: exit_code
Results: script_results
Failover Managerは noを サポートします。 自動 - あなたはフェイルオーバーマネージャーは、監視およびフェイルオーバー条件を検出しますが、スタンバイへの自動フェイルオーバーを実行しないようにしたいような状況のための フェールオーバー モード。このモードでは、フェイルオーバー条件が満たされると通知が管理者に送信されます。自動フェイルオーバーを無効にするには、クラスタプロパティファイルを修正して auto 設定します 。 failover パラメータを false 設定し false ( 3.5.1.1項を参照 )。
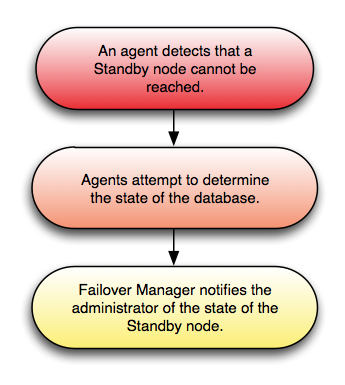
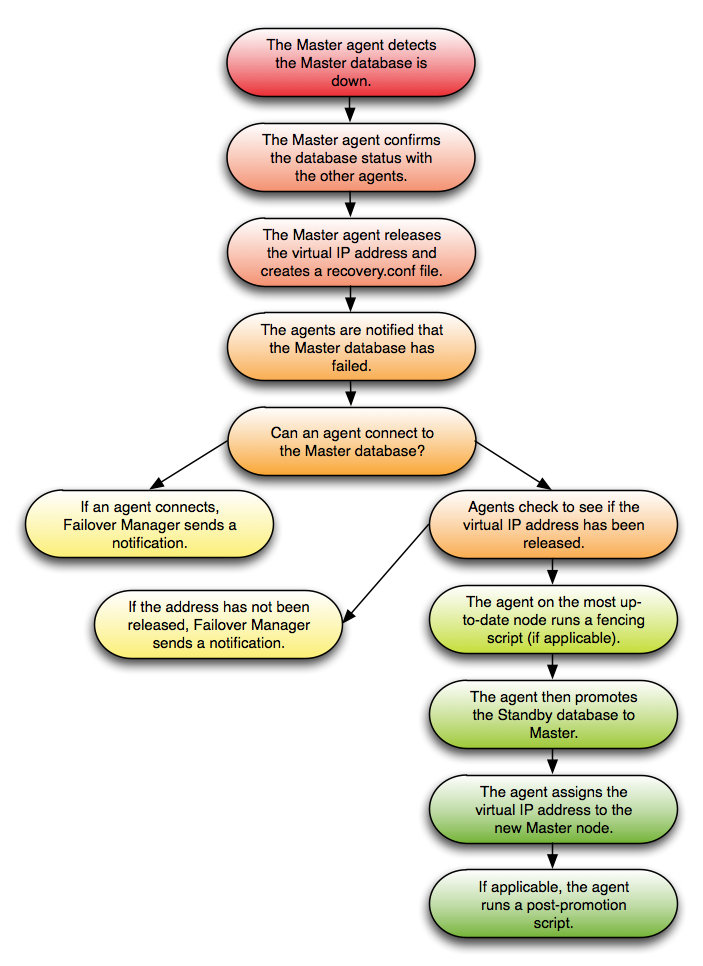 どのエージェントも仮想IPアドレスまたはデータベースサーバーにアクセスできない場合、Failover Managerはフェイルオーバープロセスを開始します。最新のノード上のスタンバイエージェントは、フェンシングスクリプトを実行し(該当する場合)、スタンバイデータベースをマスターデータベースに昇格させ、仮想IPアドレスをスタンバイノードに割り当てます。 auto ない限り、追加のスタンバイノードはすべて新しいマスターから複製するように構成されます 。 reconfigure は false 設定されてい false 。該当する場合、エージェントは販売促進スクリプトを実行します。
どのエージェントも仮想IPアドレスまたはデータベースサーバーにアクセスできない場合、Failover Managerはフェイルオーバープロセスを開始します。最新のノード上のスタンバイエージェントは、フェンシングスクリプトを実行し(該当する場合)、スタンバイデータベースをマスターデータベースに昇格させ、仮想IPアドレスをスタンバイノードに割り当てます。 auto ない限り、追加のスタンバイノードはすべて新しいマスターから複製するように構成されます 。 reconfigure は false 設定されてい false 。該当する場合、エージェントは販売促進スクリプトを実行します。
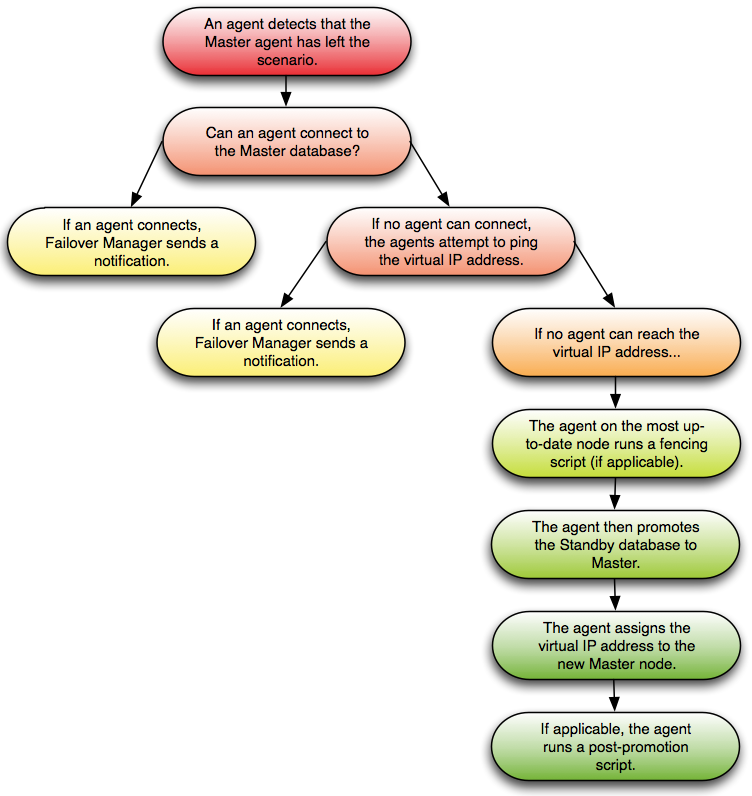 どのエージェントも仮想IPアドレスまたはデータベースサーバーにアクセスできない場合、Failover Managerはフェイルオーバープロセスを開始します。最新のノード上のスタンバイエージェントは、フェンシングスクリプトを実行し(該当する場合)、スタンバイデータベースをマスターデータベースに昇格させ、仮想IPアドレスをスタンバイノードに割り当てます。該当する場合、エージェントは販売促進スクリプトを実行します。 auto ない限り、追加のスタンバイノードはすべて新しいマスターから複製するように構成されます 。 reconfigure は false 設定されてい false 。マスターがネットワークから分離されているためにこのシナリオが発生した場合、マスターエージェントはその分離を検出して仮想IPアドレスを解放し、 recovery を作成します 。 conf ファイルFailover Managerは、クラスタの残りのノードで上記の手順を実行します。
どのエージェントも仮想IPアドレスまたはデータベースサーバーにアクセスできない場合、Failover Managerはフェイルオーバープロセスを開始します。最新のノード上のスタンバイエージェントは、フェンシングスクリプトを実行し(該当する場合)、スタンバイデータベースをマスターデータベースに昇格させ、仮想IPアドレスをスタンバイノードに割り当てます。該当する場合、エージェントは販売促進スクリプトを実行します。 auto ない限り、追加のスタンバイノードはすべて新しいマスターから複製するように構成されます 。 reconfigure は false 設定されてい false 。マスターがネットワークから分離されているためにこのシナリオが発生した場合、マスターエージェントはその分離を検出して仮想IPアドレスを解放し、 recovery を作成します 。 conf ファイルFailover Managerは、クラスタの残りのノードで上記の手順を実行します。
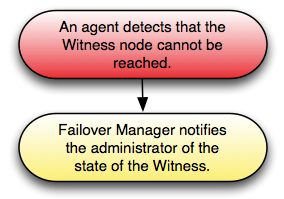 注 :1つのマスターと1つのスタンバイしか残っていない場合、マスターノードに障害が発生してもフェイルオーバー保護はありません。 Masterデータベースに障害が発生した場合、MasterエージェントとStandbyエージェントはデータベースに障害が発生したことに同意し、フェールオーバーを続行できます。
注 :1つのマスターと1つのスタンバイしか残っていない場合、マスターノードに障害が発生してもフェイルオーバー保護はありません。 Masterデータベースに障害が発生した場合、MasterエージェントとStandbyエージェントはデータベースに障害が発生したことに同意し、フェールオーバーを続行できます。
8.6 ノードがクラスタから切り離される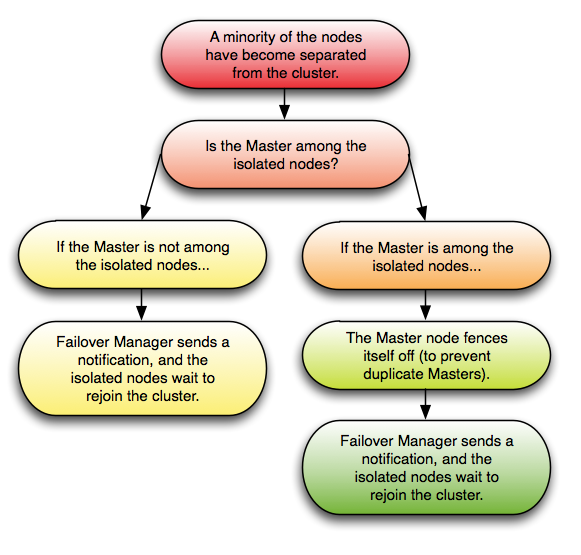
10 トラブルシューティング予期しないエラーメッセージに関する通知メッセージを受け取った場合は、フェールオーバーマネージャのログファイル(セクション 6を 参照 )でOutOfMemoryメッセージを確認します。 Failover Managerは、このプロパティで設定されたデフォルトのメモリ値で動作します。
次の例では、を使用します。 レプリケーションユーザーに対して md5 認証 を有効にするための pgpass ファイル - これはあなたの環境にとって最も安全な認証方法かもしれません。サポートされている認証オプションの詳細については、以下のPostgreSQLコアドキュメントを参照してください。
./pg_basebackup –R –D /opt/edb/as10/data
--host=146.148.46.44 –-port=5444
--username=edbrepuser --passwordpg_basebackup の呼び出し は、マスターノードのIPアドレスとマスターノード上に作成されたレプリケーションユーザーの名前を指定します。 pg_basebackupユーティリティで利用可能なオプションの詳細については、以下のPostgreSQLコアドキュメントを参照してください。standby_mode = on
primary_conninfo = 'host=146.148.46.44 port=5444 user=edbrepuser sslmode=prefer sslcompression=1 krbsrvname=postgres'
trigger_file = '/opt/edb/as10/data/mytrigger'
restore_command = '/bin/true'
recovery_target_timeline = 'latest'primary_conninfo パラメータは、レプリケーションシナリオのマスターノード上の複製ユーザーの接続情報を指定します。
13 お問い合わせ