Range: 128kB to system dependent
Specifies the maximum amount of memory to be used by maintenance operations, such as VACUUM,
CREATE INDEX, and
ALTER TABLE ADD FOREIGN KEY. It defaults to 16 megabytes (
16MB). Since only one of these operations can be executed at a time by a database session, and an installation normally doesn't have many of them running concurrently, it's safe to set this value significantly larger than
work_mem. Larger settings might improve performance for vacuuming and for restoring database dumps.
Range: 32kB to system dependent
Increasing checkpoint_timeout to a larger value, such as 15 minutes, can reduce the I/O load on your system, especially when using large values for
shared_buffers.
max_wal_size specifies the maximum size that the WAL will reach between automatic WAL checkpoints. This is a soft limit; WAL size can exceed max_wal_size under special circumstances (when under a heavy load, a failing archive_command, or a high wal_keep_segments setting).
If WAL disk usage stays below the value specified by min_wal_size, old WAL files are recycled for future use at a checkpoint, rather than removed. This ensures that enough WAL space is reserved to handle spikes in WAL usage (like when running large batch jobs). This parameter can only be set in the postgresql.conf file or on the server command line.
The default value is 200 milliseconds (200ms). Note that on many systems, the effective resolution of sleep delays is 10 milliseconds; setting
bgwriter_delay to a value that is not a multiple of 10 might have the same results as setting it to the next higher multiple of 10.
Typically, when tuning bgwriter_delay, it should be reduced from its default value. This parameter is rarely increased, except perhaps to save on power consumption on a system with very low utilization.
Reducing this value relative to seq_page_cost will cause the system to prefer index scans; raising it will make index scans look relatively more expensive. You can raise or lower both values together to change the importance of disk I/O costs relative to CPU costs, which are described by the
cpu_tuple_cost and
cpu_index_tuple_cost parameters.
Although the system will let you do so, never set random_page_cost less than
seq_page_cost. However, setting them equal (or very close to equal) makes sense if the database fits mostly or entirely within memory, since in that case there is no penalty for touching pages out of sequence. Also, in a heavily-cached database you should lower both values relative to the CPU parameters, since the cost of fetching a page already in RAM is much smaller than it would normally be.
Unlike fsync, setting this parameter to off does not create any risk of database inconsistency: an operating system or database crash might result in some recent allegedly-committed transactions being lost, but the database state will be just the same as if those transactions had been aborted cleanly.
So, turning synchronous_commit off can be a useful alternative when performance is more important than exact certainty about the durability of a transaction. See Section 29.3,
Asynchronous Commit in the
PostgreSQL Core Documentation for information.
Use edb_max_spins_per_delay to specify the maximum number of times that a session will 'spin' while waiting for a spin-lock. If a lock is not acquired, the session will sleep. If you do not specify an alternative value for
edb_max_spins_per_delay, the server will enforce the default value of
1000.
If pg_prewarm.autoprewarm is set to on, the
autoprewarm worker is enabled. If the parameter is set to off,
autoprewarm is disabled. The parameter is on by default.
Before autoprewarm can be used, you must add
$libdir/pg_prewarm to the libraries listed in the
shared_preload_libraries configuration parameter of the
postgresql.conf file as shown by the following example:
After modifying the shared_
preload_
libraries parameter, restart the database server after which the
autoprewarm background worker is launched immediately after the server has reached a consistent state.
The autoprewarm process will start loading blocks that were previously recorded in
$PGDATA/autoprewarm.blocks until there is no free buffer space left in the buffer pool. In this manner, any new blocks that were loaded either by the recovery process or by the querying clients, are not replaced.
Once the autoprewarm process has finished loading buffers from disk, it will periodically dump shared buffers to disk at the interval specified by the
pg_prewarm.autoprewarm_interval parameter (see Section
3.1.3.1.17). Upon the next server restart, the
autoprewarm process will prewarm shared buffers with the blocks that were last dumped to disk.
Range: {
none |
every |
sun |
mon |
tue |
wed |
thu |
fri |
sat} ...
Specifies the day of the week on which to rotate the audit files. Valid values are sun,
mon,
tue,
wed,
thu,
fri,
sat,
every, and
none. To disable rotation, set the value to
none. To rotate the file every day, set the
edb_audit_rotation_day value to
every. To rotate the file on a specific day of the week, set the value to the desired day of the week.
Range: {
none |
ddl |
dml |
insert |
update |
delete |
truncate |
select |
error |
create |
drop |
alter |
grant |
revoke |
rollback |
all} ...
This configuration parameter is used to specify auditing of different categories of SQL statements as well as those statements related to specific SQL commands. To log errors, set the parameter value to error. To audit all DDL statements such as
CREATE TABLE,
ALTER TABLE, etc., set the parameter value to
ddl. To audit specific types of DDL statements, the parameter values can include those specific SQL commands (
create,
drop, or
alter). In addition, the object type may be specified following the command such as
create table,
create view,
drop role, etc. All modification statements such as
INSERT,
UPDATE,
DELETE or
TRUNCATE can be audited by setting
edb_audit_statement to
dml. To audit specific types of DML statements, the parameter values can include the specific SQL commands,
insert,
update,
delete, or
truncate. Include parameter values
select,
grant,
revoke, or
rollback to audit statements regarding those SQL commands. Setting the value to
all will audit every statement while
none disables this feature.
Use edb_audit_tag to specify a string value that will be included in the audit log when the
edb_audit parameter is set to
csv or
xml.
Specifies whether the audit log information is to be recorded in the directory as given by the edb_audit_directory parameter or to the directory and file managed by the
syslog process. Set to
file to use the directory specified by
edb_audit_directory (the default setting). Set to
syslog to use the syslog process and its location as configured in the
/etc/syslog.conf file.
Note: In recent Linux versions, syslog has been replaced by
rsyslog and the configuration file is in
/etc/rsyslog.conf.
When DATE appears as the data type of a column in the commands, it is translated to
TIMESTAMP at the time the table definition is stored in the database if the configuration parameter
edb_redwood_date is set to
TRUE. Thus, a time component will also be stored in the column along with the date.
If edb_redwood_date is set to FALSE the column’s data type in a
CREATE TABLE or
ALTER TABLE command remains as a native PostgreSQL
DATE data type and is stored as such in the database. The PostgreSQL
DATE data type stores only the date without a time component in the column.
Regardless of the setting of edb_redwood_date, when
DATE appears as a data type in any other context such as the data type of a variable in an SPL declaration section, or the data type of a formal parameter in an SPL procedure or SPL function, or the return type of an SPL function, it is always internally translated to a
TIMESTAMP and thus, can handle a time component if present.
The GREATEST function returns the parameter with the greatest value from its list of parameters. The
LEAST function returns the parameter with the least value from its list of parameters.
When edb_redwood_greatest_least is set to
TRUE, the
GREATEST and
LEAST functions return null when at least one of the parameters is null.
When edb_redwood_greatest_least is set to
FALSE, null parameters are ignored except when all parameters are null in which case null is returned by the functions.
When edb_redwood_raw_names is set to its default value of
FALSE, database object names such as table names, column names, trigger names, program names, user names, etc. appear in uppercase letters when viewed from Redwood catalogs (that is, system catalogs prefixed by
ALL_,
DBA_, or
USER_). In addition, quotation marks enclose names that were created with enclosing quotation marks.
When edb_redwood_raw_names is set to
TRUE, the database object names are displayed exactly as they are stored in the PostgreSQL system catalogs when viewed from the Redwood catalogs. Thus, names created without enclosing quotation marks appear in lowercase as expected in PostgreSQL. Names created with enclosing quotation marks appear exactly as they were created, but without the quotation marks.
When viewed from the Redwood catalog, USER_TABLES, with
edb_redwood_raw_names set to the default value
FALSE, the names appear in uppercase except for the
Mixed_Case name, which appears as created and also with enclosing quotation marks.
When viewed with edb_redwood_raw_names set to
TRUE, the names appear in lowercase except for the
Mixed_Case name, which appears as created, but now without the enclosing quotation marks.
If the edb_redwood_strings parameter is set to
TRUE, when a string is concatenated with a null variable or null column, the result is the original string. If
edb_redwood_strings is set to
FALSE, the native PostgreSQL behavior is maintained, which is the concatenation of a string with a null variable or null column gives a null result.
The following is the same query executed when edb_redwood_strings is set to
TRUE. Here, the value of a null column is treated as an empty string. The concatenation of an empty string with a non-empty string produces the non-empty string.
The term statement level transaction isolation describes the behavior whereby when a runtime error occurs in a SQL command, all the updates on the database caused by that single command are rolled back. For example, if a single
UPDATE command successfully updates five rows, but an attempt to update a sixth row results in an exception, the updates to all six rows made by this
UPDATE command are rolled back. The effects of prior SQL commands that have not yet been committed or rolled back are pending until a
COMMIT or
ROLLBACK command is executed.
If edb_stmt_level_tx is set to
TRUE, then an exception will not automatically roll back prior uncommitted database updates. If
edb_stmt_level_tx is set to
FALSE, then an exception will roll back uncommitted database updates.
Note: Use
edb_stmt_level_tx set to
TRUE only when absolutely necessary, as this may cause a negative performance impact.
The following example run in PSQL shows that when edb_stmt_level_tx is
FALSE, the abort of the second
INSERT command also rolls back the first
INSERT command. Note that in PSQL, the command
\set AUTOCOMMIT off must be issued, otherwise every statement commits automatically defeating the purpose of this demonstration of the effect of
edb_stmt_level_tx.
In the following example, with edb_stmt_level_tx set to
TRUE, the first
INSERT command has not been rolled back after the error on the second
INSERT command. At this point, the first
INSERT command can either be committed or rolled back.
A ROLLBACK command could have been issued instead of the
COMMIT command in which case the insert of employee number
9001 would have been rolled back as well.
In addition to the native PostgreSQL system catalog, pg_catalog, Advanced Server contains an extended catalog view. This is the
sys catalog for the expanded catalog view. The
db_dialect parameter controls the order in which these catalogs are searched for name resolution.
When set to postgres, the namespace precedence is
pg_catalog then
sys, giving the PostgreSQL catalog the highest precedence. When set to
redwood, the namespace precedence is
sys then
pg_catalog, giving the expanded catalog views the highest precedence.
When set to on, CREATE TABLE includes a
ROWID column in newly created tables, which can then be referenced in SQL commands.
Range: {
choose |
ALL_ROWS |
FIRST_ROWS |
FIRST_ROWS_10 |
FIRST_ROWS_100 |
FIRST_ROWS_1000}
The custom_variable_classes parameter is deprecated in Advanced Server 9.2; parameters that previously depended on this parameter no longer require its support.
Use the SET command to change the parameter setting to control whether or not Index Advisor generates an alternative query plan as shown by the following example:
Range: {
learn |
passive |
active}
The edb_sql_protect.level configuration parameter can be set to one of the following values to use either learn mode, passive mode, or active mode:
|
•
|
learn. Tracks the activities of protected roles and records the relations used by the roles. This is used when initially configuring SQL/Protect so the expected behaviors of the protected applications are learned.
|
|
•
|
passive. Issues warnings if protected roles are breaking the defined rules, but does not stop any SQL statements from executing. This is the next step after SQL/Protect has learned the expected behavior of the protected roles. This essentially behaves in intrusion detection mode and can be run in production when properly monitored.
|
|
•
|
active. Stops all invalid statements for a protected role. This behaves as a SQL firewall preventing dangerous queries from running. This is particularly effective against early penetration testing when the attacker is trying to determine the vulnerability point and the type of database behind the application. Not only does SQL/Protect close those vulnerability points, but it tracks the blocked queries allowing administrators to be alerted before the attacker finds an alternate method of penetrating the system.
|
If the server is started when edb_sql_protect.max_protected_relations is set to a value outside of the valid range (for example, a value of 2,147,483,648), then a warning message is logged in the database server log file:
If the database server is started when edb_sql_protect.max_protected_roles is set to a value outside of the valid range (for example, a value of 2,147,483,648), then a warning message is logged in the database server log file:
If the database server is started when edb_sql_protect.max_queries_to_save is set to a value outside of the valid range (for example, a value of 10), then a warning message is logged in the database server log file:
Range: {
NULL |
empty_string | pgsql}
Use the edbldr.empty_csv_field parameter to specify how EDB*Loader will treat an empty string. The valid values for the
edbldr.empty_csv_field parameter are:
For more information about the edbldr.empty_csv_field parameter in EDB*Loader, see the
Database Compatibility for Oracle Developers Tools and Utilities Guide at the EnterpriseDB website:
When set to TRUE, Advanced Server’s
UTL_ENCODE.UUDECODE function can decode uuencoded data that was created by the Oracle implementation of the
UTL_ENCODE.UUENCODE function.
When set to the default setting of FALSE, Advanced Server’s
UTL_ENCODE.UUDECODE function can decode uuencoded data created by Advanced Server’s
UTL_ENCODE.UUENCODE function.
Range: Octal digits for umask settings
The utl_file.umask parameter sets the
file mode creation mask or simply, the
mask, in a manner similar to the Linux
umask command. This is for usage only within the Advanced Server
UTL_FILE package.
Note: The
utl_file.umask parameter is not supported on Windows systems.
The value specified for utl_file.umask is a 3 or 4-character octal string that would be valid for the Linux
umask command. The setting determines the permissions on files created by the
UTL_FILE functions and procedures. (Refer to any information source regarding Linux or Unix systems for information on file permissions and the usage of the
umask command.)
The following shows the results of the default utl_file.umask setting of 0077. Note that all permissions are denied on users belonging to the
enterprisedb group as well as all other users. Only user
enterprisedb has read and write permissions on the file.
Index Advisor will attempt to make indexing recommendations on INSERT,
UPDATE,
DELETE and
SELECT statements. When invoking Index Advisor, you supply the workload in the form of a set of queries (if you are providing the command in an SQL file) or an
EXPLAIN statement (if you are specifying the SQL statement at the psql command line). Index Advisor displays the query plan and estimated execution cost for the supplied query, but does not actually execute the query.
Please note that libraries in the libdir directory can only be loaded by a superuser. A database administrator can allow a non-superuser to use Index Advisor by manually copying the Index Advisor file from the
libdir directory into the
libdir/plugins directory (under your Advanced Server home directory). Only a trusted non-superuser should be allowed access to the plugin; this is an unsafe practice in a production environment.
pg_advise_index is a utility program that reads a user-supplied input file containing SQL queries and produces a text file containing
CREATE INDEX statements that can be used to create the indexes recommended by the Index Advisor. The
pg_advise_index program is located in the
bin subdirectory of the Advanced Server home directory.
index_advisor.sql is a script that creates a permanent Index Advisor log table along with a function and view to facilitate reporting of recommendations from the log table. The script is located in the
share/contrib subdirectory of the Advanced Server directory.
The index_advisor.sql script creates the
index_advisor_log table, the
show_index_recommendations() function and the
index_recommendations view. These database objects must be created in a schema that is accessible by, and included in the search path of the role that will invoke Index Advisor.
Index Advisor logs indexing recommendations in the index_advisor_log table. If Index Advisor does not find the
index_advisor_log table in the user's search path, Index Advisor will store any indexing recommendations in a temporary table of the same name. The temporary table exists only for the duration of the current session.
show_index_recommendations() is a PL/pgSQL function that interprets and displays the recommendations made during a specific Index Advisor session (as identified by its backend process ID).
Index Advisor creates the index_recommendations view based on information stored in the
index_advisor_log table during a query analysis. The view produces output in the same format as the
show_index_recommendations() function, but contains Index Advisor recommendations for all stored sessions, while the result set returned by the
show_index_recommendations() function are limited to a specified session.
|
2.
|
Run the index_advisor.sql script to create the database objects. If you are running the psql client, you can use the command:
|
\i full_pathname/index_advisor.sql
|
3.
|
Grant privileges on the index_advisor_log table to all Index Advisor users; this step is not necessary if the Index Advisor user is a superuser, or the owner of these database objects.
|
|
•
|
Grant SELECT and INSERT privileges on the index_advisor_log table to allow a user to invoke Index Advisor.
|
|
•
|
Grant DELETE privileges on the index_advisor_log table to allow the specified user to delete the table contents.
|
|
•
|
Grant SELECT privilege on the index_recommendations view.
|
pgsnmpd is an SNMP agent that can return hierarchical information about the current state of Advanced Server on a Linux system.
pgsnmpd is distributed and installed using the
edb-asxx-pgsnmpd RPM package where
xx is the Advanced Server version number. The
pgsnmpd agent can operate as a stand-alone SNMP agent, as a pass-through sub-agent, or as an AgentX sub-agent.
The pgsnmpd configuration file is named
snmpd.conf. For information about the directives that you can specify in the configuration file, please review the
snmpd.conf man page (
man snmpd.conf).
snmpconf is a menu-driven wizard. Select menu item
1: snmpd.conf to start the configuration wizard. As you select each top-level menu option displayed by
snmpconf, the wizard walks through a series of questions, prompting you for information required to build the configuration file. When you have provided information in each of the category relevant to your system, enter
Finished to generate a configuration file named
snmpd.conf. Copy the file to:
By default, pgsnmpd listens on port
161. If the listener port is already being used by another service, you may receive the following error:
The example instructs pgsnmpd to listen on UDP port
2000, where
$host_address is the IP address of the server (e.g.,
127.0.0.1).
Where POSTGRES_INSTALL_HOME specifies the Advanced Server installation directory.
Include the -b option to specify that
pgsnmpd should run in the background.
Include the -c option, specifying the path and name of the
pgsnmpd configuration file.
Include the --help option when invoking the
pgsnmpd utility to view other
pgsnmpd command line options:
You can use net-snmp commands to query the
pgsnmpd service. For example:
-v 2c option instructs the
snmpgetnext client to send the request in SNMP version 2c format.
localhost indicates the host machine running the
pgsnmpd server.
.1.3.6.1.4.1.5432.1.4.2.1.1.0 is the identity of the requested object. To see a list of all databases, increment the last digit by one (e.g. .1.1, .1.2, .1.3 etc.).
Specifies the day of the week on which to rotate the audit files. Valid values are sun,
mon,
tue,
wed,
thu,
fri,
sat,
every, and
none. To disable rotation, set the value to
none. To rotate the file every day, set the
edb_audit_rotation_day value to
every. To rotate the file on a specific day of the week, set the value to the desired day of the week.
every is the default value.
This configuration parameter is used to specify auditing of different categories of SQL statements. Various combinations of the following values may be specified: none,
dml,
insert,
update,
delete,
truncate,
select,
error,
rollback,
ddl,
create,
drop,
alter,
grant,
revoke, and
all. The default is
ddl and
error. See Section
3.5.2 for information regarding the setting of this parameter.
Specifies whether the audit log information is to be recorded in the directory as given by the edb_audit_directory parameter or to the directory and file managed by the
syslog process. Set to
file to use the directory specified by
edb_audit_directory, which is the default setting. Set to
syslog to use the syslog process and its location as configured in the
/etc/syslog.conf file.
Note: In recent Linux versions, syslog has been replaced by
rsyslog and the configuration file is in
/etc/rsyslog.conf.
The edb_audit_statement permits inclusion of one or more, comma-separated values to control which SQL statements are to be audited. The following is the general format:
|
•
|
all – Results in the auditing and logging of every statement including any error messages on statements.
|
|
•
|
none – Disables all auditing and logging. A value of none overrides any other value included in the list.
|
|
•
|
ddl – Results in the auditing of all data definition language (DDL) statements ( CREATE, ALTER, and DROP) as well as GRANT and REVOKE data control language (DCL) statements.
|
|
•
|
dml – Results in the auditing of all data manipulation language (DML) statements ( INSERT, UPDATE, DELETE, and TRUNCATE).
|
|
•
|
select – Results in the auditing of SELECT statements.
|
|
•
|
rollback – Results in the auditing of ROLLBACK statements.
|
|
•
|
error – Results in the logging of all error messages that occur. Unless the error value is included, no error messages are logged regarding any errors that occur on SQL statements related to any of the other preceding parameter values except when all is used.
|
Section 3.5.2.1 describes additional parameter values for selecting particular DDL or DCL statements for auditing.
Section 3.5.2.2 describes additional parameter values for selecting particular DML statements for auditing.
If an unsupported value is included in the edb_audit_statement parameter, then an error occurs when applying the setting to the database server. See the database server log file for the error such as in the following example where
create materialized vw results in the error. (The correct value is
create materialized view.)
|
•
|
If the edb_audit_statement parameter includes either ddl or all, then all DDL statements are audited. In addition, the DCL statements GRANT and REVOKE are audited as well.
|
|
•
|
If the edb_audit_statement is set to none, then no DDL nor DCL statements are audited.
|
If object_type is omitted from the parameter value, then all of the specified command statements (either
create,
alter, or
drop) are audited.
"connection authorized: user=enterprisedb database=edb",,,,,,,,,"","",""
"statement: CREATE ROLE adminuser;",,,,,,,,,"psql.bin","CREATE ROLE",""
"statement: CREATE DATABASE auditdb;",,,,,,,,,"psql.bin","CREATE DATABASE",""
"statement: ALTER DATABASE auditdb OWNER TO adminuser;",,,,,,,,,"psql.bin","ALTER DATABASE",""
"connection authorized: user=adminuser database=auditdb",,,,,,,,,"","",""
"statement: CREATE SCHEMA edb;",,,,,,,,,"psql.bin","CREATE SCHEMA",""
);",,,,,,,,,"psql.bin","CREATE TABLE",""
);",,,,,,,,,"psql.bin","CREATE TABLE",""
The CREATE and
ALTER statements for the
adminuser role and
auditdb database are audited. The error for the
ALTER ROLE adminuser statement is also logged since error is included in the
edb_audit_statement parameter.
Similarly, the CREATE statements for schema
edb and tables
department and
dept are audited.
Note that the DROP TABLE department statement is not in the audit log since there is no
edb_audit_statement setting that would result in the auditing of successfully processed
DROP statements such as
ddl,
all, or
drop.
"connection authorized: user=adminuser database=auditdb",,,,,,,,,"","",""
SELECT empno, ename, hiredate, sal, comm FROM emp WHERE job = 'SALESMAN';",,,,,,,,,"psql.bin","CREATE VIEW",""
SELECT empno, ename, hiredate, sal, comm FROM emp WHERE job = 'MANAGER';",,,,,,,,,"psql.bin","CREATE MATERIALIZED VIEW",""
"statement: CREATE SEQUENCE next_empno START WITH 8000 INCREMENT BY 1;",,,,,,,,,"psql.bin","CREATE SEQUENCE",""
"statement: GRANT ALL ON dept TO PUBLIC;",,,,,,,,,"psql.bin","GRANT",""
"statement: GRANT ALL ON emp TO PUBLIC;",,,,,,,,,"psql.bin","GRANT",""
The CREATE VIEW and
CREATE MATERIALIZED VIEW statements are audited. Note that the prior
CREATE TABLE emp statement is not audited since none of the values
create,
create table,
ddl, nor
all are included in the
edb_audit_statement parameter.
The CREATE SEQUENCE and
GRANT statements are audited since those values are included in the
edb_audit_statement parameter.
|
•
|
If the edb_audit_statement parameter includes either dml or all, then all DML statements are audited.
|
|
•
|
If the edb_audit_statement is set to none, then no DML statements are audited.
|
"connection authorized: user=adminuser database=auditdb",,,,,,,,,"","",""
"statement: UPDATE dept SET loc = 'BEDFORD' WHERE deptno = 40;",,,,,,,,,"psql.bin","UPDATE",""
"statement: DELETE FROM emp WHERE deptno = 10;",,,,,,,,,"psql.bin","DELETE",""
"relation ""employee"" does not exist",,,,,,"TRUNCATE employee;",,,"psql.bin","",""
2017-07-16 13:46:26.362 EDT,,,4491,,596ba59c.118b,1,,2017-07-16 13:42:52 EDT,,0,LOG,00000,
"database system is shut down",,,,,,,,,"","",""
The UPDATE dept and
DELETE FROM emp statements are audited. Note that all of the prior
INSERT statements are not audited since none of the values
insert,
dml, nor
all are included in the
edb_audit_statement parameter.
The SELECT * FROM dept statement is not audited as well since neither
select nor
all is included in the
edb_audit_statement parameter.
Since error is specified in the
edb_audit_statement parameter, but not the
truncate value, the error on the
TRUNCATE employee statement is logged in the audit file, but not the successful
TRUNCATE emp statement.
The setting of the edb_audit_statement parameter in the configuration file affects the entire database cluster.
|
•
|
The edb_audit_statement parameter can be set as an attribute of a specified database with the ALTER DATABASE dbname SET edb_audit_statement command. This setting overrides the edb_audit_statement parameter in the configuration file for statements executed when connected to database dbname.
|
|
•
|
The edb_audit_statement parameter can be set as an attribute of a specified role with the ALTER ROLE rolename SET edb_audit_statement command. This setting overrides the edb_audit_statement parameter in the configuration file as well as any setting assigned to the database by the previously described ALTER DATABASE command when the specified role is running the current session.
|
|
•
|
The edb_audit_statement parameter can be set as an attribute of a specified role when using a specified database with the ALTER ROLE rolename IN DATABASE dbname SET edb_audit_statement command. This setting overrides the edb_audit_statement parameter in the configuration file as well as any setting assigned to the database by the previously described ALTER DATABASE command as well as any setting assigned to the role with the ALTER ROLE command without the IN DATABASE clause as previously described.
|
|
•
|
Database auditdb with ddl, insert, update, and delete
|
|
•
|
Role admin with select and truncate
|
|
•
|
Role admin in database auditdb with create table, insert, and update
|
Case 1: Changes made in database
auditdb by role
enterprisedb. Only
ddl,
insert,
update, and
delete statements are audited:
"statement: CREATE TABLE audit_tbl (f1 INTEGER PRIMARY KEY, f2 TEXT);",,,,,,,,,
"statement: INSERT INTO audit_tbl VALUES (1, 'Row 1');",,,,,,,,,"psql.bin","INSERT",""
"statement: UPDATE audit_tbl SET f2 = 'Row A' WHERE f1 = 1;",,,,,,,,,"psql.bin","UPDATE",""
Case 2: Changes made in database
edb by role
admin. Only
select and
truncate statements are audited:
"statement: CREATE TABLE audit_tbl (f1 INTEGER PRIMARY KEY, f2 TEXT);",,,,,,,,,
"statement: INSERT INTO audit_tbl VALUES (1, 'Row 1');",,,,,,,,,"psql.bin","INSERT",""
"statement: UPDATE audit_tbl SET f2 = 'Row A' WHERE f1 = 1;",,,,,,,,,"psql.bin","UPDATE",""
"statement: SELECT * FROM edb_tbl;",,,,,,,,,"psql.bin","SELECT",""
"statement: TRUNCATE edb_tbl;",,,,,,,,,"psql.bin","TRUNCATE TABLE",""
Case 3: Changes made in database
auditdb by role
admin. Only
create table,
insert, and
update statements are audited:
"statement: CREATE TABLE audit_tbl (f1 INTEGER PRIMARY KEY, f2 TEXT);",,,,,,,,,
"statement: INSERT INTO audit_tbl VALUES (1, 'Row 1');",,,,,,,,,"psql.bin","INSERT",""
"statement: UPDATE audit_tbl SET f2 = 'Row A' WHERE f1 = 1;",,,,,,,,,"psql.bin","UPDATE",""
"statement: SELECT * FROM edb_tbl;",,,,,,,,,"psql.bin","SELECT",""
"statement: TRUNCATE edb_tbl;",,,,,,,,,"psql.bin","TRUNCATE TABLE",""
"statement: CREATE TABLE audit_tbl_2 (f1 INTEGER PRIMARY KEY, f2 TEXT);",,,,,,,,,
"statement: INSERT INTO audit_tbl_2 VALUES (1, 'Row 1');",,,,,,,,,"psql.bin","INSERT",""
2017-07-13 15:38:42.028 EDT,,,3942,,5967c934.f66,1,,2017-07-13 15:25:40 EDT,,0,LOG,00000,"database system is shut down",,,,,,,,,"","",""
|
•
|
Field. Name of the field as shown in the sample table definition in the PostgreSQL documentation as previously referenced.
|
|
•
|
XML Element/Attribute. For the XML format, name of the XML element and its attribute (if used), referencing the value. Note: n/a indicates that there is no XML representation for this field.
|
|
•
|
Data Type. Data type of the field as given by the PostgreSQL sample table definition.
|
|
•
|
Description. Description of the field. For certain fields, no output is generated in the audit log as those fields are not supported by auditing. Those fields are indicated by “Not supported”.
|
The fields with the Description of “Not supported” appear as consecutive commas (
,,) in the CSV format.
The edb_audit parameter is changed to
xml when generating the XML format.
"connection authorized: user=enterprisedb database=edb",,,,,,,,,"","","edbaudit"
"statement: CREATE SCHEMA edb;",,,,,,,,,"psql.bin","CREATE SCHEMA","edbaudit"
);",,,,,,,,,"psql.bin","CREATE TABLE","edbaudit"
"statement: INSERT INTO dept VALUES (10,'ACCOUNTING','NEW YORK');",,,,,,,,,
"statement: SELECT * FROM dept;",,,,,,,,,"psql.bin","SELECT","edbaudit"
"disconnection: session time: 0:02:01.511 user=enterprisedb database=edb host=[local]",,,,,,,,,"psql.bin","SELECT","edbaudit"
2017-07-17 13:30:53.617 EDT,,,3987,,596cf3b3.f93,1,,2017-07-17 13:28:19 EDT,,0,LOG,00000,
"database system is shut down",,,,,,,,,"","","edbaudit"
Then, use the edb_
filter_
log.
errcodes parameter to specify any error codes you wish to omit from the log files:
Where error_code specifies one or more error codes that you wish to omit from the log file. Provide multiple error codes in a comma-delimited list.
For example, if edb_
filter_
log is enabled, and
edb_
filter_
log.
errcode is set to
'23505,23502,22012', any log entries that return one of the following SQLSTATE errors:
23505 (for violating a unique constraint)
23502 (for violating a not-null constraint)
22012 (for dividing by zero)
"statement: CREATE ROLE newuser WITH LOGIN;",,,,,,,,,"psql.bin","CREATE ROLE",""
"statement: ALTER ROLE newuser WITH SUPERUSER;",,,,,,,,,"psql.bin","ALTER ROLE",""
"statement: DROP ROLE newuser;",,,,,,,,,"psql.bin","DROP ROLE",""
You can use the edb_
filter_
log.
redact_
password_
commands extension to instruct the server to redact stored passwords from the log file. Note that the module only recognizes the following syntax:
{CREATE|ALTER} {USER|ROLE|GROUP} identifier { [WITH] [ENCRYPTED] PASSWORD 'nonempty_string_literal' | IDENTIFIED BY { 'nonempty_string_literal' | bareword } } [ REPLACE { 'nonempty_string_literal' | bareword } ]
Then, set edb_filter_log.redact_password_commands to true:
After modifying the postgresql.conf file, you must restart the server for the changes to take effect.
Collation icu_collate_lowercase forces the lowercase form of a letter to sort before its uppercase counterpart (
CL).
Collation icu_collate_uppercase forces the uppercase form of a letter to sort before its lowercase counterpart (
CU).
Collation icu_collate_ignore_punct causes variable characters (white space and punctuation marks) to be ignored during sorting (
AS).
Collation icu_collate_ignore_white_sp causes white space and other non-visible variable characters to be ignored during sorting, but visible variable characters (punctuation marks) are not ignored (
AS,
T0020).
Note: When creating collations, ICU may generate notice and warning messages when attributes are given to modify the
LROOT collation.
The following query sorts on column c2 using the default collation. Note that variable characters (white space and punctuation marks) with
id column values of
9,
10, and
11 are ignored and sort with the letter
B.
The following query sorts on column c2 using collation
icu_collate_lowercase, which forces the lowercase form of a letter to sort before the uppercase form of the same base letter. Also note that the
AN attribute forces variable characters to be included in the sort order at the same level when comparing base characters so rows with
id values of
9,
10, and
11 appear at the beginning of the sort list before all letters and numbers.
The following query sorts on column c2 using collation
icu_collate_uppercase, which forces the uppercase form of a letter to sort before the lowercase form of the same base letter.
The following query sorts on column c2 using collation
icu_collate_ignore_punct, which causes variable characters to be ignored so rows with
id values of
9,
10, and
11 sort with the letter
B as that is the character immediately following the ignored variable character.
The following query sorts on column c2 using collation
icu_collate_ignore_white_sp. The
AS and
T0020 attributes of the collation cause variable characters with code points less than or equal to hexadecimal
0020 to be ignored while variable characters with code points greater than hexadecimal
0020 are included in the sort.
The row with id value of
11, which starts with a space character (hexadecimal
0020) sorts with the letter
B. The rows with
id values of
9 and
10, which start with visible punctuation marks greater than hexadecimal
0020, appear at the beginning of the sort list as these particular variable characters are included in the sort order at the same level when comparing base characters.
The library file (sqlprotect.so on Linux,
sqlprotect.dll on Windows) necessary to run SQL/Protect should be installed in the
lib subdirectory of your Advanced Server home directory. For Windows, this should be done by the Advanced Server installer. For Linux, install the
edb-asxx-server-sqlprotect RPM package where
xx is the Advanced Server version number.
Step 1: Edit the following configuration parameters in the
postgresql.conf file located in the
data subdirectory of your Advanced Server home directory.
|
•
|
edb_sql_protect.enabled. Controls whether or not SQL/Protect is actively monitoring protected roles by analyzing SQL statements issued by those roles and reacting according to the setting of edb_sql_protect.level. When you are ready to begin monitoring with SQL/Protect set this parameter to on. If this parameter is omitted, the default is off.
|
|
•
|
edb_sql_protect.level. Sets the action taken by SQL/Protect when a SQL statement is issued by a protected role. If this parameter is omitted, the default behavior is passive. Initially, set this parameter to learn. See Section 4.1.2.1.2 for further explanation of this parameter.
|
|
•
|
edb_sql_protect.max_queries_to_save. Sets the maximum number of offending queries to save in the edb_sql_protect_queries view. If this parameter is omitted, the default setting is 5000. If the number of offending queries reaches the limit, additional queries are not saved in the view, but are accessible in the database server log file. Note: The minimum valid value for this parameter is 100. If a value less than 100 is specified, the database server starts using the default setting of 5000. A warning message is recorded in the database server log file. See Section 3.1.3.12.9 for information on the maximum range of this parameter.
|
Step 2: Restart the database server after you have modified the
postgresql.conf file.
On Linux: Invoke the Advanced Server service script with the
restart option:
On Windows: Use the Windows
Services applet to restart the service named
edb-as-11.
Step 3: For each database that you want to protect from SQL injection attacks, connect to the database as a superuser (either
enterprisedb or
postgres, depending upon your installation options) and run the script
sqlprotect.sql located in the
share/contrib subdirectory of your Advanced Server home directory. The script creates the SQL/Protect database objects in a schema named
sqlprotect.
Step 1: Connect as a superuser to a database that you wish to protect using either
psql or Postgres Enterprise Manager Client.
Step 2: Since the SQL/Protect tables, functions, and views are built under the
sqlprotect schema, use the
SET search_path command to include the
sqlprotect schema in your search path. This eliminates the need to schema-qualify any operation or query involving SQL/Protect database objects.
Step 3: Each role that you wish to protect must be added to the protected roles list. This list is maintained in the table
edb_sql_protect.
Configuration parameter edb_sql_protect.level sets the protection level, which defines the behavior of SQL/Protect when a protected role issues a SQL statement.
The defined behavior applies to all roles in the protected roles lists of all databases configured with SQL/Protect in the database server.
In the postgresql.conf file the
edb_sql_protect.level configuration parameter can be set to one of the following values to use either learn mode, passive mode, or active mode:
|
•
|
learn. Tracks the activities of protected roles and records the relations used by the roles. This is used when initially configuring SQL/Protect so the expected behaviors of the protected applications are learned.
|
|
•
|
passive. Issues warnings if protected roles are breaking the defined rules, but does not stop any SQL statements from executing. This is the next step after SQL/Protect has learned the expected behavior of the protected roles. This essentially behaves in intrusion detection mode and can be run in production when properly monitored.
|
|
•
|
active. Stops all invalid statements for a protected role. This behaves as a SQL firewall preventing dangerous queries from running. This is particularly effective against early penetration testing when the attacker is trying to determine the vulnerability point and the type of database behind the application. Not only does SQL/Protect close those vulnerability points, but it tracks the blocked queries allowing administrators to be alerted before the attacker finds an alternate method of penetrating the system.
|
If the edb_sql_protect.level parameter is not set or is omitted from the configuration file, the default behavior of SQL/Protect is passive.
Step 1: To activate SQL/Protect in learn mode, set the following parameters in the
postgresql.conf file as shown below:
Step 2: Reload the
postgresql.conf file.
Note: For an alternative method of reloading the configuration file, use the
pg_reload_conf function. Be sure you are connected to a database as a superuser and execute function
pg_reload_conf as shown by the following example:
Step 3: Allow the protected roles to run their applications.
SQL/Protect generates a NOTICE severity level message indicating the relation has been added to the role’s protected relations list.
Step 4: As a protected role runs applications, the SQL/Protect tables can be queried to observe the addition of relations to the role’s protected relations list.
Query the edb_sql_protect_rel table to see the relations added to the protected relations list:
The view list_protected_rels is provided that gives more comprehensive information along with the object names instead of the OIDs.
Step 1: To activate SQL/Protect in passive mode, set the following parameters in the
postgresql.conf file as shown below:
Step 3: Monitor the statistics for suspicious activity.
By querying the view edb_sql_protect_stats, you can see the number of times SQL statements were executed that referenced relations that were not in a role’s protected relations list, or contained SQL injection attack signatures. See Section
4.1.1.2.2 for more information on view
edb_sql_protect_stats.
Step 4: View information on specific attacks.
By querying the view edb_sql_protect_queries, you can see the SQL statements that were executed that referenced relations that were not in a role’s protected relations list, or contained SQL injection attack signatures. See Section
4.1.1.2.3 for more information on view
edb_sql_protect_queries.
Note: The
ip_address and
port columns do not return any information if the attack originated on the same host as the database server using the Unix-domain socket (that is,
pg_hba.conf connection type
local).
Step 1: To activate SQL/Protect in active mode, set the following parameters in the
postgresql.conf file as shown below:
Note: The variation of the function using the OID is useful if you remove the role using the
DROP ROLE or
DROP USER SQL statement before removing the role from the protected roles list. If a query on a SQL/Protect relation returns a value such as
unknown (OID=16458) for the user name, use the
unprotect_role(roleoid) form of the function to remove the entry for the deleted role from the protected roles list.
|
•
|
dbid. OID of the database for which you are making the change
|
|
•
|
roleid. OID of the role for which you are changing the Boolean settings
|
If the relation given by relname is not in your current search path, specify the relation’s schema using the second function format.
Note: The variation of the function using the OID is useful if you remove the role using the
DROP ROLE or
DROP USER SQL statement before deleting the role’s statistics using
drop_stats('rolename'). If a query on
edb_sql_protect_stats returns a value such as
unknown (OID=16458) for the user name, use the
drop_stats(roleoid) form of the function to remove the deleted role’s statistics from
edb_sql_protect_stats.
Note: The variation of the function using the OID is useful if you remove the role using the
DROP ROLE or
DROP USER SQL statement before deleting the role’s offending queries using
drop_queries('rolename'). If a query on
edb_sql_protect_queries returns a value such as
unknown (OID=16454) for the user name, use the
drop_queries(roleoid) form of the function to remove the deleted role’s offending queries from
edb_sql_protect_queries.
Step 1: Set the configuration parameter
edb_sql_protect.enabled to
off in the
postgresql.conf file.
The entry for edb_sql_protect.enabled should look like the following:
Step 1: Set the configuration parameter
edb_sql_protect.enabled to
on in the
postgresql.conf file.
The entry for edb_sql_protect.enabled should look like the following:
Note: This section is applicable if your backup and restore procedures result in the re-creation of database objects in the new database with new OIDs such as is the case when using the
pg_dump backup program.
SQL/Protect uses two tables, edb_sql_protect and
edb_sql_protect_rel, to store information on database objects such as databases, roles, and relations. References to these database objects in these tables are done using the objects’ OIDs, and not the objects’ text names. The OID is a numeric data type used by Advanced Server to uniquely identify each database object.
The following sections describe two functions, export_sqlprotect and
import_sqlprotect, that are used specifically for backing up and restoring SQL/Protect tables in order to ensure the OIDs in the SQL/Protect tables reference the correct database objects after the SQL/Protect tables are restored.
Step 1: Create a backup file using
pg_dump.
Step 2: Connect to the database as a superuser and export the SQL/Protect data using the
export_sqlprotect('sqlprotect_file') function where
sqlprotect_file is the fully qualified path to a file where the SQL/Protect data is to be saved.
The enterprisedb operating system account (
postgres if you installed Advanced Server in PostgreSQL compatibility mode) must have read and write access to the directory specified in
sqlprotect_file.
The files /tmp/edb.dmp and
/tmp/sqlprotect.dmp comprise your total database backup.
Step 1: Restore the backup file to the new database.
Step 2: Connect to the new database as a superuser and delete all rows from the
edb_sql_protect_rel table.
This step removes any existing rows in the edb_sql_protect_rel table that were backed up from the original database. These rows do not contain the correct OIDs relative to the database where the backup file has been restored.
Step 3: Delete all rows from the
edb_sql_protect table.
This step removes any existing rows in the edb_sql_protect table that were backed up from the original database. These rows do not contain the correct OIDs relative to the database where the backup file has been restored.
Step 4: Delete any statistics that may exist for the database.
Step 5: Delete any offending queries that may exist for the database.
Step 6: Make sure the role names that were protected by SQL/Protect in the original database exist in the database server where the new database resides.
Step 7: Run the function
import_sqlprotect('sqlprotect_file') where
sqlprotect_file is the fully qualified path to the file you created in Step 2 of Section
4.1.4.2.
Tables edb_sql_protect and
edb_sql_protect_rel are now populated with entries containing the OIDs of the database objects as assigned in the new database. The statistics view
edb_sql_protect_stats also now displays the statistics imported from the original database.
|
•
|
dbid. Matches the value in the oid column from pg_database for newdb
|
|
•
|
roleid. Matches the value in the oid column from pg_roles for appuser
|
Also note that in table edb_sql_protect_rel, the values in the
relid column match the values in the
oid column of
pg_class for relations
dept and
appuser_tab.
Step 8: Verify that the SQL/Protect configuration parameters are set as desired in the
postgresql.conf file for the database server running the new database. Restart the database server or reload the configuration file as appropriate.
Use the CREATE RESOURCE GROUP command to create a new resource group.
The CREATE RESOURCE GROUP command creates a resource group with the specified name. Resource limits can then be defined on the group with the
ALTER RESOURCE GROUP command. The resource group is accessible from all databases in the Advanced Server instance.
To use the CREATE RESOURCE GROUP command you must have superuser privileges.
Use the ALTER RESOURCE GROUP command to change the attributes of an existing resource group. The command syntax comes in three forms.
resource_type { TO | = } { value | DEFAULT };
The ALTER RESOURCE GROUP command changes certain attributes of an existing resource group.
The second form with the SET resource_type TO clause either assigns the specified literal value to a resource type, or resets the resource type when
DEFAULT is specified. Resetting or setting a resource type to
DEFAULT means that the resource group has no defined limit on that resource type.
To use the ALTER RESOURCE GROUP command you must have superuser privileges.
When value is specified, the literal value to be assigned to
resource_type. When
DEFAULT is specified, the assignment of
resource_type is reset for the resource group.
Use the DROP RESOURCE GROUP command to remove a resource group.
The DROP RESOURCE GROUP command removes a resource group with the specified name.
To use the DROP RESOURCE GROUP command you must have superuser privileges.
Use the SET edb_resource_group TO group_name command to assign the current process to a specified resource group as shown by the following.
A change to edb_resource_group in the
postgresql.conf file requires a configuration file reload before it takes effect on the database server instance.
Set edb_resource_group to
DEFAULT or use
RESET edb_resource_group to remove the current process from a resource group as shown by the following.
|
•
|
cpu_rate_limit. The value of the CPU rate limit resource type assigned to the resource group.
|
|
•
|
dirty_rate_limit. The value of the dirty rate limit resource type assigned to the resource group.
|
Note: Columns
per_process_cpu_rate_limit and
per_process_dirty_rate_limit do not show the
actual resource consumption used by the processes, but indicate how EDB Resource Manager sets the resource limit for an individual process based upon the number of active processes in the resource group.
The following shows edb_all_resource_groups when resource group
resgrp_a contains no active processes, resource group
resgrp_b contains two active processes, and resource group
resgrp_c contains one active process.
In the edb_all_resource_groups view, note that the
per_process_cpu_rate_limit and
per_process_dirty_rate_limit values are roughly the corresponding CPU rate limit and dirty rate limit divided by the number of active processes.
Set the cpu_rate_limit parameter to the fraction of CPU time over wall-clock time to which the combined, simultaneous CPU usage of all processes in the group should not exceed. Thus, the value assigned to
cpu_rate_limit should typically be less than or equal to 1.
The valid range of the cpu_rate_limit parameter is 0 to 1.67772e+07. A setting of 0 means no CPU rate limit has been set for the resource group.
EDB Resource Manager utilizes CPU throttling to keep the aggregate CPU usage of all processes in the group within the limit specified by the
cpu_rate_limit parameter. A process in the group may be interrupted and put into sleep mode for a short interval of time to maintain the defined limit. When and how such interruptions occur is defined by a proprietary algorithm used by EDB Resource Manager.
The ALTER RESOURCE GROUP command with the
SET cpu_rate_limit clause is used to set the CPU rate limit for a resource group.
In the following example the CPU usage limit is set to 50% for resgrp_a, 40% for
resgrp_b and 30% for
resgrp_c. This means that the combined CPU usage of all processes assigned to
resgrp_a is maintained at approximately 50%. Similarly, for all processes in
resgrp_b, the combined CPU usage is kept to approximately 40%, etc.
Changing the cpu_rate_limit of a resource group not only affects new processes that are assigned to the group, but any currently running processes that are members of the group are immediately affected by the change. That is, if the
cpu_rate_limit is changed from .5 to .3, currently running processes in the group would be throttled downward so that the aggregate group CPU usage would be near 30% instead of 50%.
In a second session, the Linux top command is used to display the CPU usage as shown under the
%CPU column. The following is a snapshot at an arbitrary point in time as the
top command output periodically changes.
The psql session performing the factorial calculation is shown by the row where
edb-postgres appears under the
COMMAND column. The CPU usage of the session shown under the
%CPU column shows 39.9, which is close to the 40% CPU limit set for resource group
resgrp_b.
By contrast, if the psql session is removed from the resource group and the factorial calculation is performed again, the CPU usage is much higher.
Under the %CPU column for
edb-postgres, the CPU usage is now 93.6, which is significantly higher than the 39.9 when the process was part of the resource group.
The following command sequence displays the sum of all edb-postgres processes sampled over half second time intervals. This shows how the total CPU usage of the processes in the resource group changes over time as EDB Resource Manager throttles the processes to keep the total resource group CPU usage near 40%.
In this example, two additional psql sessions are used along with the previous two sessions. The third and fourth sessions perform the same factorial calculation within resource group
resgrp_c with a
cpu_rate_limit of
.3 (30% CPU usage).
The top command displays the following output.
The second and third edb-postgres processes belonging to the resource group where the CPU usage is limited to 40%, have a total CPU usage of 37.8. However, the first
edb-postgres process has a 58.6% CPU usage as it is not within a resource group, and basically utilizes the remaining, available CPU resources on the system.
Set the dirty_rate_limit parameter to the number of kilobytes per second for the combined rate at which all the processes in the group should write to or “dirty” the shared buffers. An example setting would be 3072 kilobytes per seconds.
The valid range of the dirty_rate_limit parameter is 0 to 1.67772e+07. A setting of 0 means no dirty rate limit has been set for the resource group.
EDB Resource Manager utilizes dirty buffer throttling to keep the aggregate, shared buffer writing rate of all processes in the group near the limit specified by the
dirty_rate_limit parameter. A process in the group may be interrupted and put into sleep mode for a short interval of time to maintain the defined limit. When and how such interruptions occur is defined by a proprietary algorithm used by EDB Resource Manager.
The ALTER RESOURCE GROUP command with the
SET dirty_rate_limit clause is used to set the dirty rate limit for a resource group.
In the following example the dirty rate limit is set to 12288 kilobytes per second for resgrp_a, 6144 kilobytes per second for
resgrp_b and 3072 kilobytes per second for
resgrp_c. This means that the combined writing rate to the shared buffer of all processes assigned to
resgrp_a is maintained at approximately 12288 kilobytes per second. Similarly, for all processes in
resgrp_b, the combined writing rate to the shared buffer is kept to approximately 6144 kilobytes per second, etc.
Changing the dirty_rate_limit of a resource group not only affects new processes that are assigned to the group, but any currently running processes that are members of the group are immediately affected by the change. That is, if the
dirty_rate_limit is changed from 12288 to 3072, currently running processes in the group would be throttled downward so that the aggregate group dirty rate would be near 3072 kilobytes per second instead of 12288 kilobytes per second.
The FILLFACTOR = 10 clause results in
INSERT commands packing rows up to only 10% per page. This results in a larger sampling of dirty shared blocks for the purpose of these examples.
The pg_stat_statements module is used to display the number of shared buffer blocks that are dirtied by a SQL command and the amount of time the command took to execute. This provides the information to calculate the actual kilobytes per second writing rate for the SQL command, and thus compare it to the dirty rate limit set for a resource group.
Step 1: In the
postgresql.conf file, add
$libdir/pg_stat_statements to the
shared_preload_libraries configuration parameter as shown by the following.
Step 2: Restart the database server.
Step 3: Use the
CREATE EXTENSION command to complete the creation of the
pg_stat_statements module.
The pg_stat_statements_reset() function is used to clear out the
pg_stat_statements view for clarity of each example.
Finally, the INSERT command generates a series of integers from 1 to 10,000 to populate the table, and dirty approximately 10,000 blocks.
Note: The
INSERT commands in session 1 and session 2 were started after the
SELECT pg_stat_statements_reset() command in session 2 was run.
In this example, two additional psql sessions are used along with the previous two sessions. The third and fourth sessions perform the same
INSERT command in resource group
resgrp_c with a
dirty_rate_limit of 3072 kilobytes per second.
Note: The
INSERT commands in all four sessions were started after the
SELECT pg_stat_statements_reset() command in session 4 was run.
The following shows the results from the INSERT commands in the four sessions.
RECORD 3 shows the results from session 1.
RECORD 2 shows the results from session 2.
RECORD 4 shows the results from session 3.
RECORD 5 shows the results from session 4.
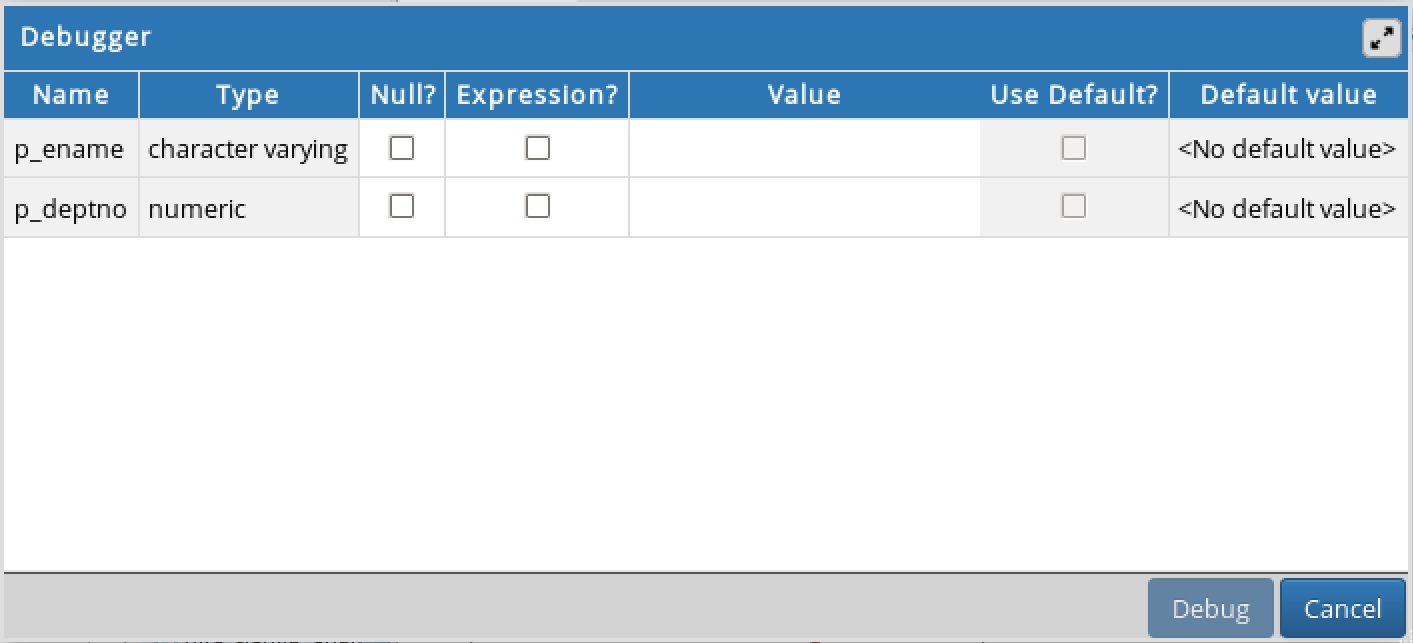
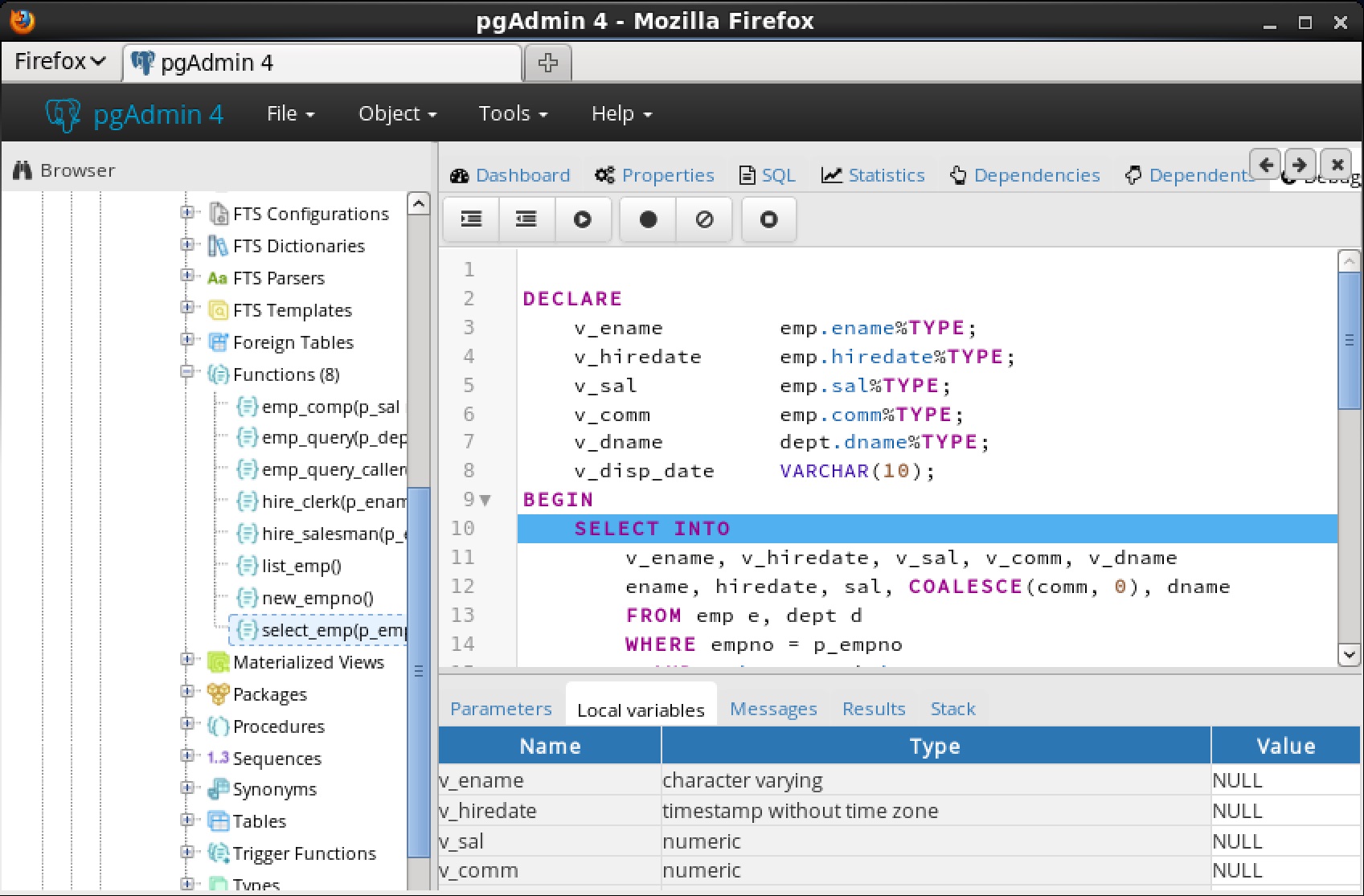
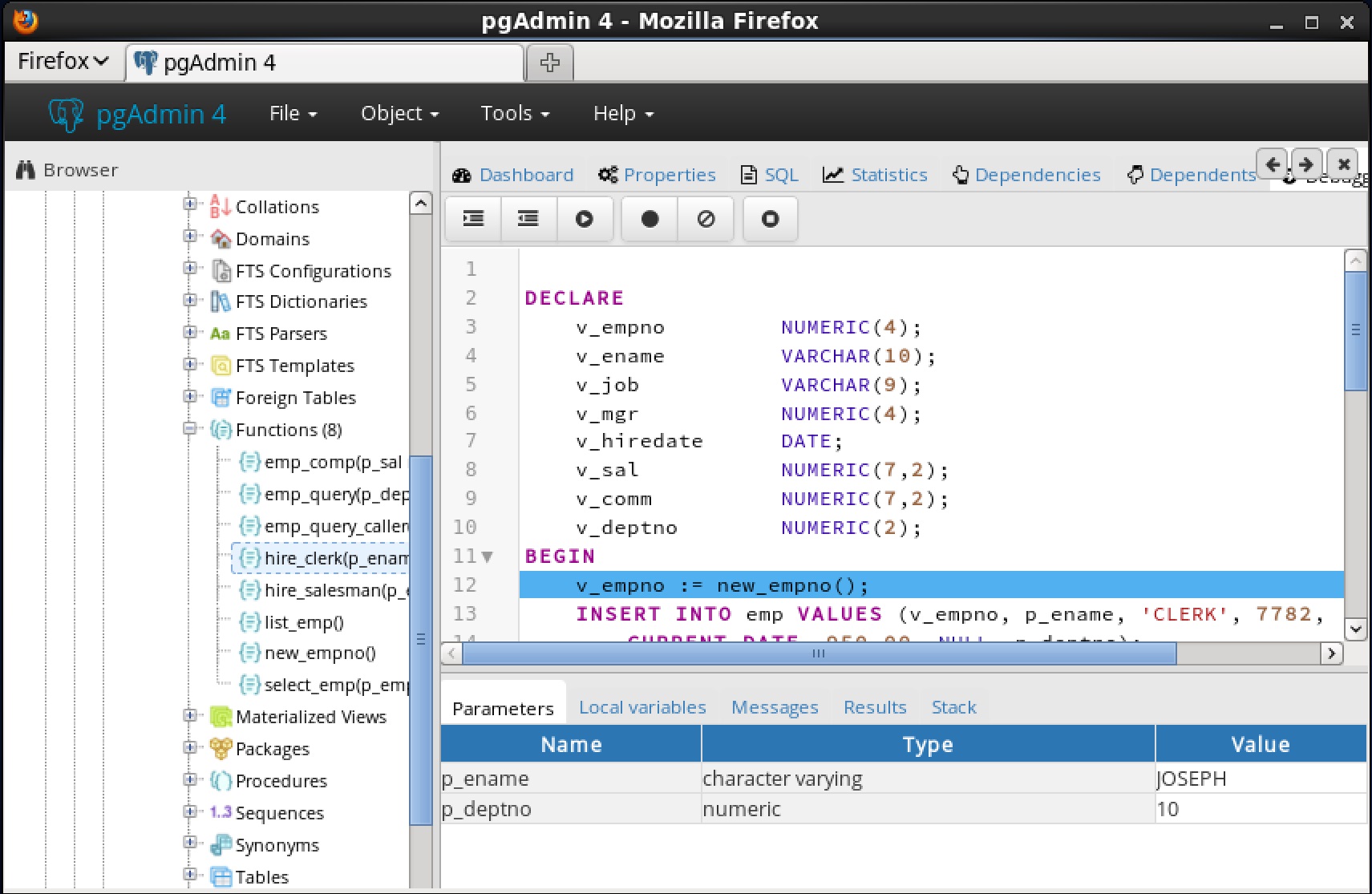
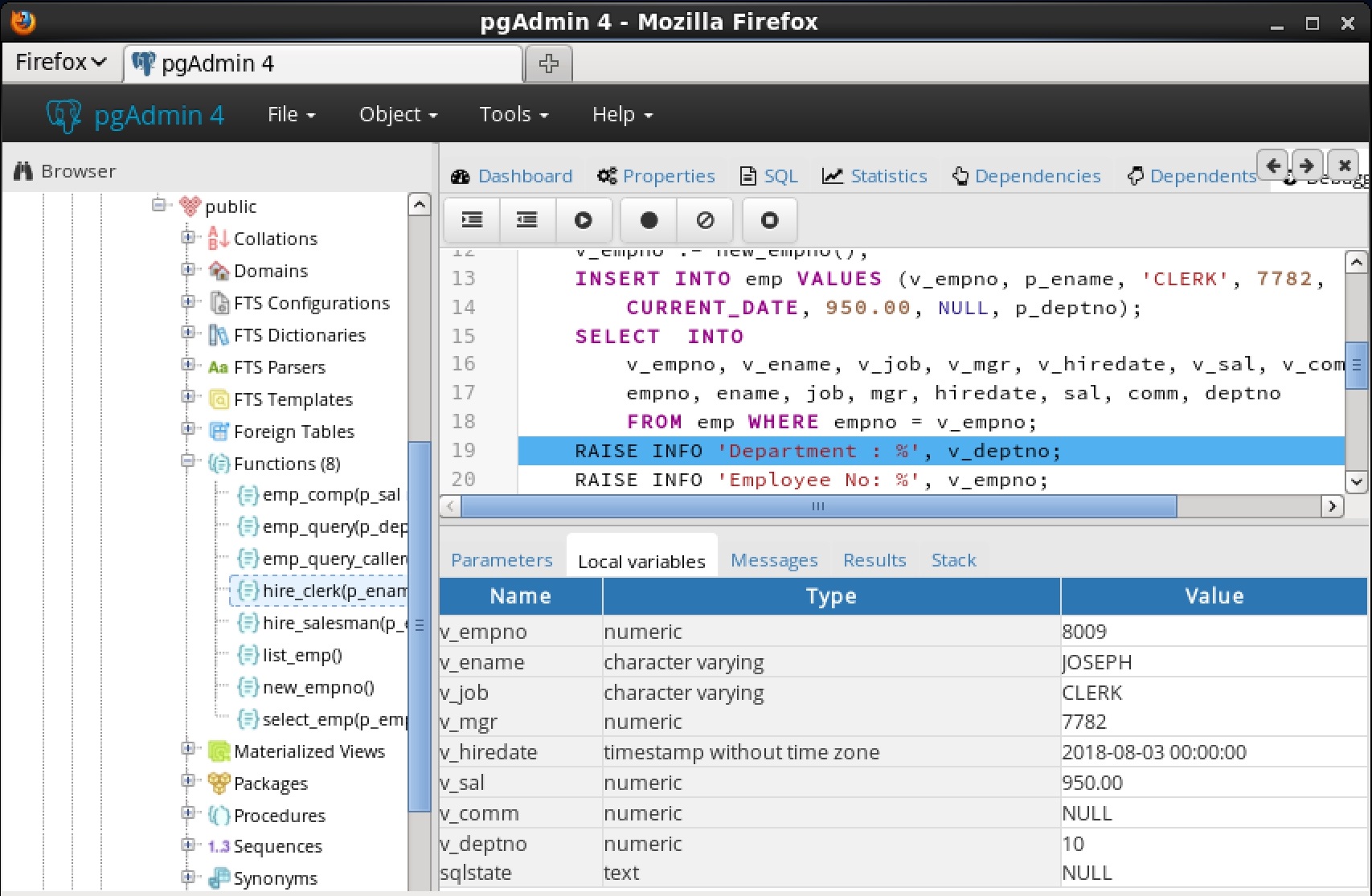
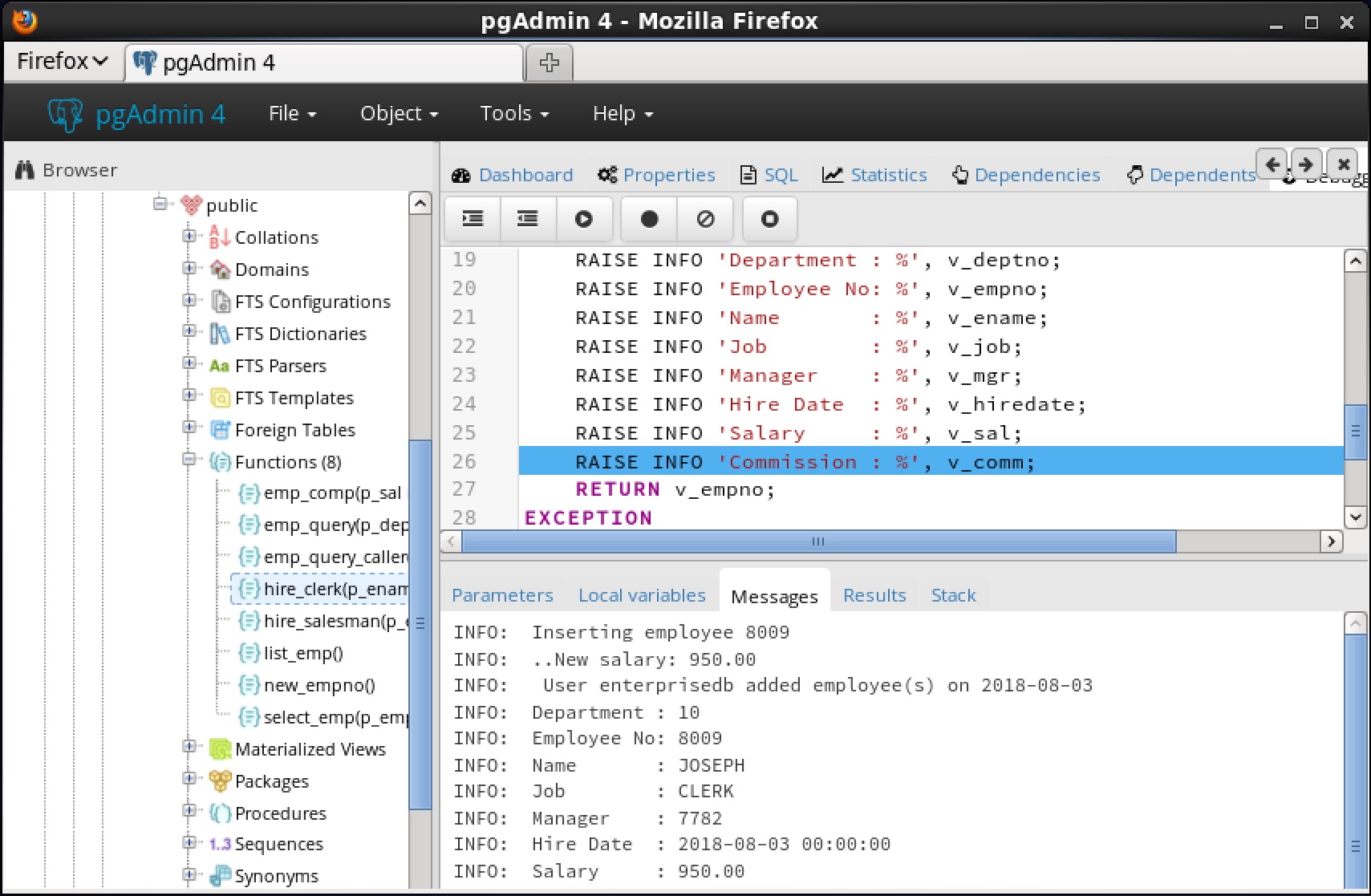
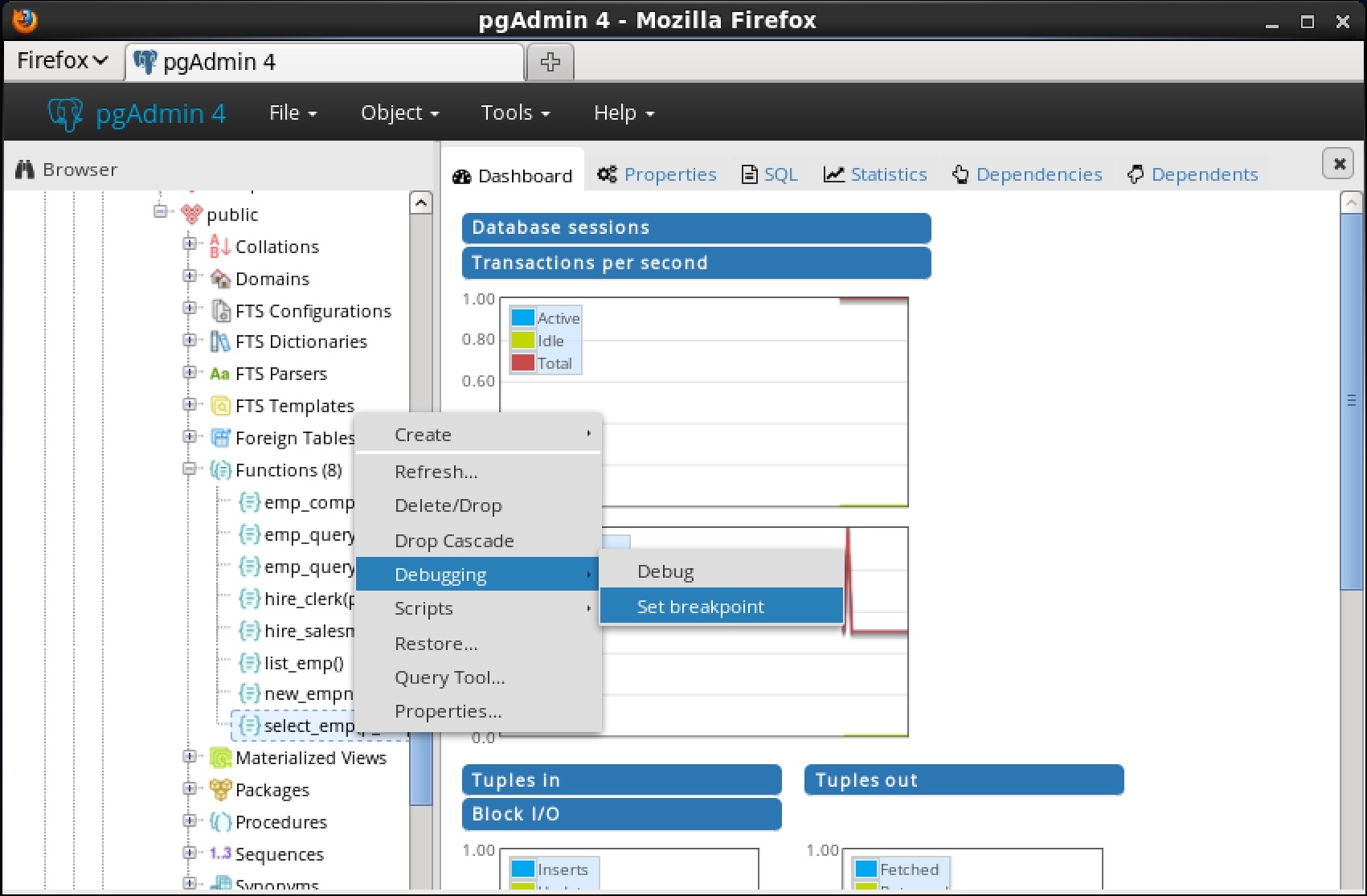
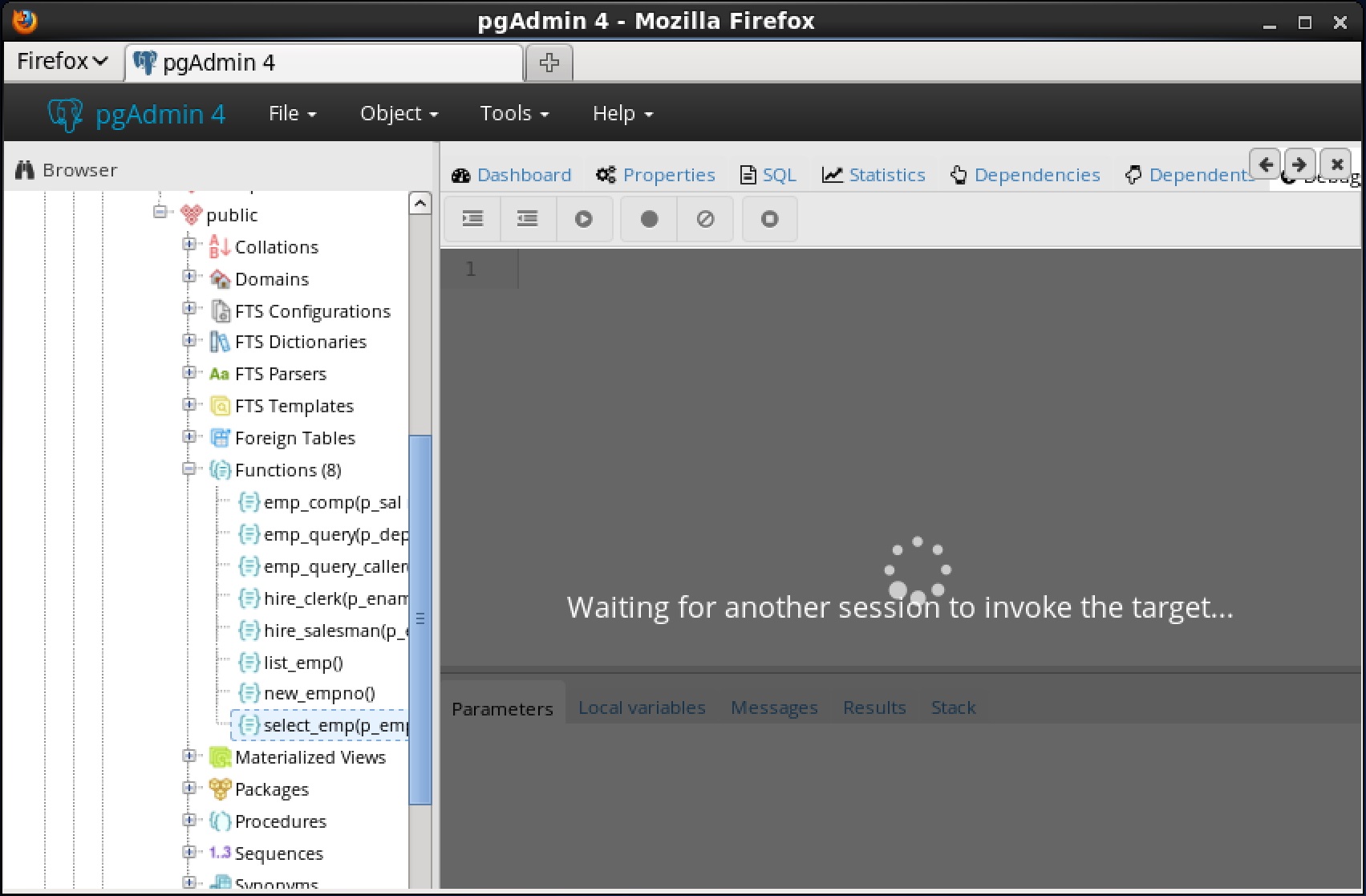
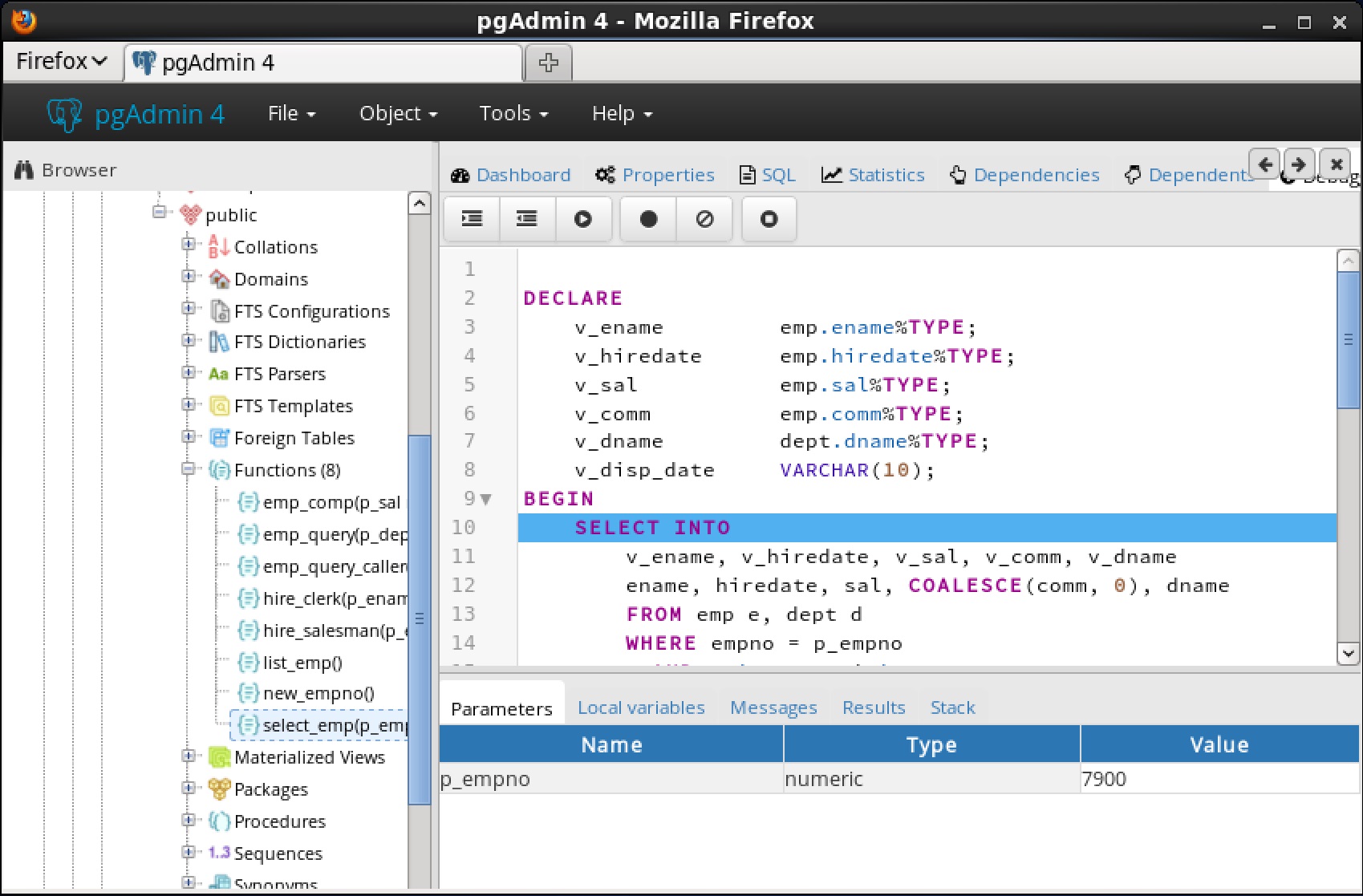
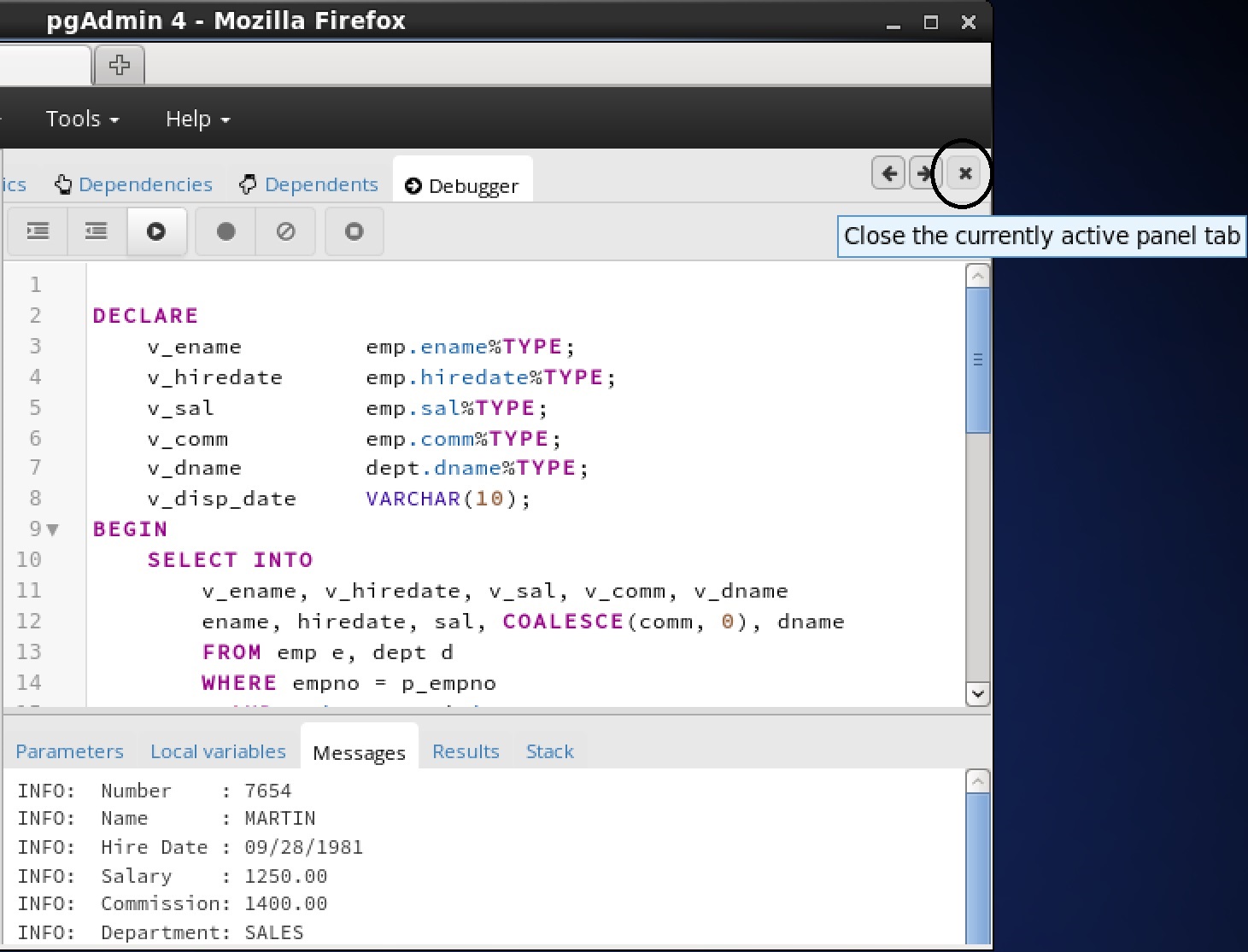
You can use the Debugger window to pass parameter values when you are standalone-debugging a program that expects parameters. When you start the debugger, the
Debugger window opens automatically to display any
IN or
IN OUT parameters expected by the program. If the program declares no
IN or
IN OUT parameters, the
Debugger window does not open.
|
•
|
The Name field contains the formal parameter name.
|
|
•
|
The Type field contains the parameter data type.
|
|
•
|
Check the Null? checkbox to indicate that the parameter is a NULL value.
|
|
•
|
Check the Expression? checkbox if the Value field contains an expression.
|
|
•
|
The Value field contains the parameter value that will be passed to the program.
|
|
•
|
Check the Use Default? checkbox to indicate that the program should use the value in the Default Value field.
|
|
•
|
The Default Value field contains the default value of the parameter.
|
Press the Tab key to select the next parameter in the list for data entry, or click on a
Value field to select the parameter for data entry.
Note: The
Debugger window does not open during in-context debugging. Instead, the application calling the program to be debugged must supply any required input parameter values.
Step 1: The following extensions must be installed on the database:
Ensure that pgAgent is installed before creating the pgagent extension. On Linux, you can use the
edb-asxx-pgagent RPM package where
xx is the Advanced Server version number to install pgAgent. On Windows, use StackBuilder Plus to download and install pgAgent.
Step 2: Modify the
postgresql.conf file.
Modify the postgresql.conf file by adding
$libdir/parallel_clone to the
shared_preload_libraries configuration parameter as shown by the following example:
Step 3: The Perl Procedural Language (PL/Perl) must be installed on the database and the
CREATE TRUSTED LANGUAGE plperl command must be run. For Linux, install PL/Perl using the
edb-asxx-server-plperl RPM package where
xx is the Advanced Server version number. For Windows, use the EDB Postgres Language Pack. For information on EDB Language Pack, see the
EDB Postgres Language Pack Guide available at:
Step 4: Connect to the database as a superuser and run the following command:
|
•
|
work_mem. Specifies the amount of memory to be used by internal sort operations and hash tables before writing to temporary disk files.
|
|
•
|
maintenance_work_mem. Specifies the maximum amount of memory to be used by maintenance operations, such as VACUUM, CREATE INDEX, and ALTER TABLE ADD FOREIGN KEY.
|
|
•
|
checkpoint_flush_after. Whenever more than checkpoint_flush_after bytes have been written while performing a checkpoint, attempt to force the OS to issue these writes to the underlying storage.
|
|
•
|
max_wal_size. Maximum size to let the WAL grow to between automatic WAL checkpoints.
|
|
•
|
max_locks_per_transaction. This parameter controls the average number of object locks allocated for each transaction; individual transactions can lock more objects as long as the locks of all transactions fit in the lock table.
|
Step 1: If you had previously installed an older version of the
edb_cloneschema extension, then you must run the following command:
Step 2: Install the extensions using the following commands:
When using one of the local cloning functions, localcopyschema or
localcopyschema_nb, one of the required parameters includes a single, foreign server for identifying the database server along with its database that is the source and the receiver of the cloned schema.
When using one of the remote cloning functions, remotecopyschema or
remotecopyschema_nb, two of the required parameters include two foreign servers. The foreign server specified as the first parameter identifies the source database server along with its database that is the provider of the cloned schema. The foreign server specified as the second parameter identifies the target database server along with its database that is the receiver of the cloned schema.
For the localcopyschema and
localcopyschema_nb functions, the source and target schemas are both within the same database of the same database server. Thus, only one foreign server must be defined and specified for these functions. This foreign server is also referred to as the
local server.
The following psql commands show the foreign server and user mapping:
When database superuser enterprisedb invokes a cloning function, the database user
enterprisedb with its password is used to connect to
local_server on the
localhost with port
5444 to database
edb.
In this case, the mapped database user, enterprisedb, and the database user,
enterprisedb, used to connect to the local
edb database happen to be the same, identical database user, but that is not an absolute requirement.
For the remotecopyschema and
remotecopyschema_nb functions, the source and target schemas are in different databases of either the same or different database servers. Thus, two foreign servers must be defined and specified for these functions.
The following psql commands show the foreign servers and user mappings:
When database superuser enterprisedb invokes a cloning function, the database user
tgtuser with password
tgtpassword is used to connect to
tgt_server on the
localhost with port
5444 to database
tgtdb.
In addition, database user srcuser with password
srcpassword connects to
src_server on host
192.168.2.28 with port
5444 to database
srcdb.
Note: Be sure the
pg_hba.conf file of the database server running the source database
srcdb has an appropriate entry permitting connection from the target server location (address
192.168.2.27 in the following example) connecting with the database user
srcuser that was included in the user mapping for the foreign server
src_server defining the source server and database.
|
•
|
The edb_util schema is in the search path, or the cloning function is to be invoked with the edb_util prefix.
|
|
•
|
When using the remote copy functions, if the on_tblspace parameter is to be set to true, then the target database cluster contains all tablespaces that are referenced by objects in the source schema, otherwise creation of the DDL statements for those database objects will fail in the target schema. This causes a failure of the cloning process.
|
|
•
|
When using the remote copy functions, if the copy_acls parameter is to be set to true, then all roles that have GRANT privileges on objects in the source schema exist in the target database cluster, otherwise granting of privileges to those roles will fail in the target schema. This causes a failure of the cloning process.
|
The localcopyschema function copies a schema and its database objects within a local database specified within the
source_fdw foreign server from the source schema to the specified target schema within the same database.
A BOOLEAN value is returned by the function. If the function succeeds, then
true is returned. If the function fails, then
false is returned.
The source_fdw,
source_schema,
target_schema, and
log_filename are required parameters while all other parameters are optional.
BOOLEAN value to specify whether or not database objects are to be created within their tablespaces. If
false is specified, then the
TABLESPACE clause is not included in the applicable
CREATE DDL statement when added to the target schema. If
true is specified, then the
TABLESPACE clause is included in the
CREATE DDL statement when added to the target schema. If the
on_tblspace parameter is omitted, the default value is
false.
BOOLEAN value to specify whether or not the DDLs are to be printed in
log_filename when creating objects in the target schema. If
false is specified, then DDLs are not printed. If
true is specified, then DDLs are printed. If omitted, the default value is
false.
BOOLEAN value to specify whether or not the access control list (ACL) is to be included while creating objects in the target schema. The access control list is the set of
GRANT privilege statements. If
false is specified, then the access control list is not included for the target schema. If
true is specified, then the access control list is included for the target schema. If the
copy_acls parameter is omitted, the default value is
false.
|
•
|
Foreign server (local_server) and user mapping (see Section 9.1.4.1) with the information of the preceding bullet points
|
The localcopyschema_nb function copies a schema and its database objects within a local database specified within the
source_fdw foreign server from the source schema to the specified target schema within the same database, but in a non-blocking manner as a job submitted to pgAgent.
An INTEGER value job ID is returned by the function for the job submitted to pgAgent. If the function fails, then null is returned.
The source_fdw,
source,
target, and
log_filename are required parameters while all other parameters are optional.
BOOLEAN value to specify whether or not database objects are to be created within their tablespaces. If
false is specified, then the
TABLESPACE clause is not included in the applicable
CREATE DDL statement when added to the target schema. If
true is specified, then the
TABLESPACE clause is included in the
CREATE DDL statement when added to the target schema. If the
on_tblspace parameter is omitted, the default value is
false.
BOOLEAN value to specify whether or not the DDLs are to be printed in
log_filename when creating objects in the target schema. If
false is specified, then DDLs are not printed. If
true is specified, then DDLs are printed. If omitted, the default value is
false.
BOOLEAN value to specify whether or not the access control list (ACL) is to be included while creating objects in the target schema. The access control list is the set of
GRANT privilege statements. If
false is specified, then the access control list is not included for the target schema. If
true is specified, then the access control list is included for the target schema. If the
copy_acls parameter is omitted, the default value is
false.
Note: the
pgagent -l 2 option starts pgAgent in
DEBUG mode, which logs continuous debugging information into the log file specified with the
-s option. Use a lower value for the
-l option, or omit it entirely to record less information.
The localcopyschema_nb function returns the job ID shown as
4 in the example.
The remotecopyschema function copies a schema and its database objects from a source schema in the remote source database specified within the
source_fdw foreign server to a target schema in the local target database specified within the
target_fdw foreign server.
A BOOLEAN value is returned by the function. If the function succeeds, then
true is returned. If the function fails, then
false is returned.
The source_fdw,
target_fdw,
source_schema,
target_schema, and
log_filename are required parameters while all other parameters are optional.
BOOLEAN value to specify whether or not database objects are to be created within their tablespaces. If
false is specified, then the
TABLESPACE clause is not included in the applicable
CREATE DDL statement when added to the target schema. If
true is specified, then the
TABLESPACE clause is included in the
CREATE DDL statement when added to the target schema. If the
on_tblspace parameter is omitted, the default value is
false.
Note: If
true is specified and a database object has a
TABLESPACE clause, but that tablespace does not exist in the target database cluster, then the cloning function fails.
BOOLEAN value to specify whether or not the DDLs are to be printed in
log_filename when creating objects in the target schema. If
false is specified, then DDLs are not printed. If
true is specified, then DDLs are printed. If omitted, the default value is
false.
BOOLEAN value to specify whether or not the access control list (ACL) is to be included while creating objects in the target schema. The access control list is the set of
GRANT privilege statements. If
false is specified, then the access control list is not included for the target schema. If
true is specified, then the access control list is included for the target schema. If the
copy_acls parameter is omitted, the default value is
false.
Note: If
true is specified and a role with
GRANT privilege does not exist in the target database cluster, then the cloning function fails.
|
•
|
Foreign server (src_server) and user mapping (see Section 9.1.4.2) with the information of the preceding bullet points
|
|
•
|
Foreign server (tgt_server) and user mapping (see Section 9.1.4.2) with the information of the preceding bullet points
|
When the remotecopyschema function was invoked, four background workers were specified.
Note that the DATA-COPY log message includes two, square bracket numbers (for example,
[0][3]).
The remotecopyschema_nb function copies a schema and its database objects from a source schema in the remote source database specified within the
source_fdw foreign server to a target schema in the local target database specified within the
target_fdw foreign server, but in a non-blocking manner as a job submitted to pgAgent.
An INTEGER value job ID is returned by the function for the job submitted to pgAgent. If the function fails, then null is returned.
The source_fdw,
target_fdw,
source,
target, and
log_filename are required parameters while all other parameters are optional.
BOOLEAN value to specify whether or not database objects are to be created within their tablespaces. If
false is specified, then the
TABLESPACE clause is not included in the applicable
CREATE DDL statement when added to the target schema. If
true is specified, then the
TABLESPACE clause is included in the
CREATE DDL statement when added to the target schema. If the
on_tblspace parameter is omitted, the default value is
false.
Note: If
true is specified and a database object has a
TABLESPACE clause, but that tablespace does not exist in the target database cluster, then the cloning function fails.
BOOLEAN value to specify whether or not the DDLs are to be printed in
log_filename when creating objects in the target schema. If
false is specified, then DDLs are not printed. If
true is specified, then DDLs are printed. If omitted, the default value is
false.
BOOLEAN value to specify whether or not the access control list (ACL) is to be included while creating objects in the target schema. The access control list is the set of
GRANT privilege statements. If
false is specified, then the access control list is not included for the target schema. If
true is specified, then the access control list is included for the target schema. If the
copy_acls parameter is omitted, the default value is
false.
Note: If
true is specified and a role with
GRANT privilege does not exist in the target database cluster, then the cloning function fails.
The remotecopyschema_nb function returns the job ID shown as
2 in the example.
The process_status_from_log function provides the status of a cloning function from its log file.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Displays either STARTUP, INITIAL, DDL-COLLECTION, PRE-DATA, DATA-COPY, POST-DATA, or FINAL.
|
|
|
|
The remove_log_file_and_job function performs cleanup tasks by removing the log files created by the schema cloning functions and the jobs created by the non-blocking functions.
|
•
|
If only log_file is specified, then the function will only remove the log file.
|
|
•
|
If only job_id is specified, then the function will only remove the job.
|
COMMENT ON
{
AGGREGATE aggregate_name ( aggregate_signature ) |
CAST (source_type AS target_type) |
COLLATION object_name |
COLUMN relation_name.column_name |
CONSTRAINT constraint_name ON table_name |
CONSTRAINT constraint_name ON DOMAIN domain_name |
CONVERSION object_name |
DATABASE object_name |
DOMAIN object_name |
EXTENSION object_name |
EVENT TRIGGER object_name |
FOREIGN DATA WRAPPER object_name |
FOREIGN TABLE object_name |
FUNCTION func_name ([[argmode] [argname] argtype [, ...]])|
INDEX object_name |
LARGE OBJECT large_object_oid |
MATERIALIZED VIEW object_name |
OPERATOR operator_name (left_type, right_type) |
OPERATOR CLASS object_name USING index_method |
OPERATOR FAMILY object_name USING index_method |
PACKAGE object_name
POLICY policy_name ON table_name |
[ PROCEDURAL ] LANGUAGE object_name |
PROCEDURE proc_name [([[argmode] [argname] argtype [, ...]])]
PUBLIC SYNONYM object_name
ROLE object_name |
RULE rule_name ON table_name |
SCHEMA object_name |
SEQUENCE object_name |
SERVER object_name |
TABLE object_name |
TABLESPACE object_name |
TEXT SEARCH CONFIGURATION object_name |
TEXT SEARCH DICTIONARY object_name |
TEXT SEARCH PARSER object_name |
TEXT SEARCH TEMPLATE object_name |
TRANSFORM FOR type_name LANGUAGE lang_name |
TRIGGER trigger_name ON table_name |
TYPE object_name |
VIEW object_name
} IS 'text'
where aggregate_
signature is:
* |
[ argmode ] [ argname ] argtype [ , ... ] |
[ [ argmode ] [ argname ] argtype [ , ... ] ]
ORDER BY [ argmode ] [ argname ] argtype [ , ... ]
AGGREGATE aggregate_name (aggregate_signature)
Include the AGGREGATE clause to create a comment about an aggregate.
aggregate_name specifies the name of an aggregate, and
aggregate_signature specifies the associated signature in one of the following forms:
* |
[ argmode ] [ argname ] argtype [ , ... ] |
[ [ argmode ] [ argname ] argtype [ , ... ] ]
ORDER BY [ argmode ] [ argname ] argtype [ , ... ]
Where argmode is the mode of a function, procedure, or aggregate argument; argmode may be IN, OUT, INOUT, or VARIADIC. If omitted, the default is IN.
argname is the name of an aggregate argument.
argtype is the data type of an aggregate argument.
CAST (source_type AS target_type)
Include the CAST clause to create a comment about a cast.
When creating a comment about a cast, source_type specifies the source data type of the cast, and target_type specifies the target data type of the cast.
COLUMN relation_name.column_name
Include the COLUMN clause to create a comment about a column.
column_name specifies name of the column to which the comment applies. relation_name is the table, view, composite type, or foreign table in which a column resides.
CONSTRAINT constraint_name ON table_name
CONSTRAINT constraint_name ON DOMAIN domain_name
Include the CONSTRAINT clause to add a comment about a constraint. When creating a comment about a constraint, constraint_name specifies the name of the constraint; table_name or domain_name specifies the name of the table or domain on which the constraint is defined.
FUNCTION func_name ([[argmode] [argname] argtype [, ...]])
Include the FUNCTION clause to add a comment about a function. func_name specifies the name of the function.
argmode specifies the mode of the function; argmode may be IN, OUT, INOUT, or VARIADIC. If omitted, the default is IN. argname specifies the name of a function, procedure, or aggregate argument. argtype specifies the data type of a function, procedure, or aggregate argument.
large_object_oid is the system-assigned OID of the large object about which you are commenting.
OPERATOR operator_name (left_type, right_type)
Include the OPERATOR clause to add a comment about an operator.
operator_name specifies the (optionally schema-qualified) name of an operator on which you are commenting.
left_type and
right_type are the (optionally schema-qualified) data type(s) of the operator's arguments.
Include the OPERATOR CLASS clause to add a comment about an operator class.
object_name specifies the (optionally schema-qualified) name of an operator on which you are commenting.
index_method specifies the associated index method of the operator class.
Include the OPERATOR FAMILY clause to add a comment about an operator family.
object_name specifies the (optionally schema-qualified) name of an operator family on which you are commenting.
index_method specifies the associated index method of the operator family.
POLICY policy_name ON table_name
Include the POLICY clause to add a comment about a policy.
policy_name specifies the name of the policy, and
table_name specifies the table that the policy is associated with.
PROCEDURE proc_name [([[argmode] [argname] argtype [, ...]])]
Include the PROCEDURE clause to add a comment about a procedure. proc_name specifies the name of the procedure. argmode specifies the mode of the procedure; argmode may be IN, OUT, INOUT, or VARIADIC. If omitted, the default is IN. argname specifies the name of a function, procedure, or aggregate argument. argtype specifies the data type of a function, procedure, or aggregate argument.
RULE rule_name ON table_name
Include the RULE clause to specify a COMMENT on a rule
. rule_name specifies the name of the rule, and table_name specifies the name of the table on which the rule is defined.
Include the TRANSFORM FOR clause to specify a COMMENT on a TRANSFORM. type_name specifies the name of the data type of the transform and lang_name specifies the name of the language of the transform.
Include the TRIGGER clause to specify a COMMENT on a trigger
. trigger_name specifies the name of the trigger, and table_name specifies the name of the table on which the trigger is defined.
Names of tables, aggregates, collations, conversions, domains, foreign tables, functions, indexes, operators, operator classes, operator families, packages, procedures, sequences, text search objects, types, and views can be schema-qualified.