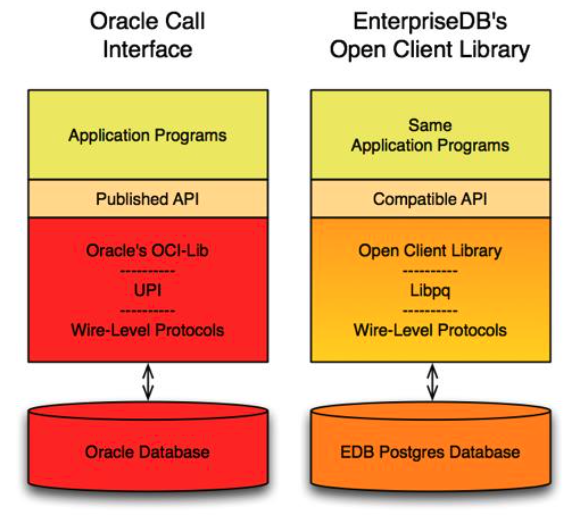
以前は今、アプリケーション・コードを変更せずに、最小限でAdvanced ServerまたはOracleデータベースのいずれかで動作することができ、「固定」されたアプリケーション- オープンクライアントライブラリでは、Oracle Call Interfaceのとアプリケーションの相互運用性を提供します。 Open Client LibraryのEnterpriseDB実装はC言語で記述されています。
1 はじめに
セクション3.3で説明したSQLプロファイラは、アプリケーションで不適切に実行されているSQLクエリを検出して診断します。
セクション4.2で説明した仮想プライベートデータベースは、きめ細かな行レベルのアクセスを提供します。
1.1 新機能
1.2 このガイドで使用される表記規則以下の説明では、 用語は、言語キーワード、ユーザ提供値、リテラルなどの任意の単語または単語群を指す。用語の正確な意味は、それが使用される文脈に依存する。
1.4 このガイドで使用されているサンプルについてどこ xx Advanced Serverのバージョン番号です。さらに、Oracleデータベースと互換性のある構文を使用して作成されたデータベース・オブジェクトを含むスクリプトが、同じディレクトリにあります。このスクリプトファイルは edb-sample.sqlです。
Advanced Serverには、Oracleアプリケーションでサポートされている構文との互換性を提供する拡張機能が含まれています。 Advanced Serverで サポートされているすべての互換性機能の 詳細は、「Oracleデベロッパー・ガイドのデータベース互換性」を参照してください。情報は4つのガイドに分かれています。
2.1 互換機能の有効化
2.2 ストアドプロシージャ言語
2.3 オプティマイザのヒントDELETE 、 INSERT 、 SELECT 、またはUPDATEコマンドを呼び出すと、サーバーは一連の実行計画を生成します。それらの実行計画を分析した後、サーバーは、(最も)最も時間のかかる結果セットを返すプランを選択します。サーバーの計画の選択は、いくつかの要素に依存します。
2.4 データ・ディクショナリ・ビューAdvanced Serverには、Oracleデータ・ディクショナリ・ビューと互換性のある方法でデータベース・オブジェクトに関する情報を提供する一連のビューが含まれています。 Advanced Serverで利用可能なビューの詳細については、次のURLにある「 Oracle Developer Reference Guide」のデータベース互換性 を参照してください 。
2.5 dblink_oradblink _ oraは、Advanced Server内からOracleシステムに格納されたデータのSELECT 、 INSERT 、 UPDATEまたはDELETEを可能にするOCIベースのデータベース・リンクを提供します。 dblink _ ora使用dblinkとサポートされている関数とプロシージャの詳細については、次のURLにある「Oracleデベロッパーズ・ガイド」のデータベース互換性を参照してください。
2.6 プロファイル管理Advanced Serverは、プロファイル管理用の互換SQL構文をサポートしています。プロファイル管理コマンドを使用すると、データベースのスーパーユーザーは、名前付き プロファイル 。各プロファイルは、 passwordとmd5認証を強化するpassword管理のルールを定義しています。プロファイル内のルールは次のことができます。
2.7 組み込みパッケージ
以前は今、アプリケーション・コードを変更せずに、最小限でAdvanced ServerまたはOracleデータベースのいずれかで動作することができ、「固定」されたアプリケーション- オープンクライアントライブラリでは、Oracle Call Interfaceのとアプリケーションの相互運用性を提供します。 Open Client LibraryのEnterpriseDB実装はC言語で記述されています。
2.9 ユーティリティ下記のユーティリティでサポートされている互換構文の詳細については、次の URLにある「Oracle Developer Tools and Utilities Guide」 の データベース互換性を 参照してください 。
2.10 ECPGPlus
2.11 テーブルのパーティション化
3 データベース管理
3.1 構成パラメータ
3.1.1 設定パラメータの設定
3.1.2 構成パラメータの概要
3.1.3 機能別の構成パラメータ
3.1.3.1 上位パフォーマンス関連パラメータ3.1.3.1.1 shared_buffersデフォルト値: 32MB範囲:システムに依存する128kB効果の最小範囲:クラスター有効化に必要な権限: EPASサービスアカウントデータベースサーバが共有メモリバッファに使用するメモリ量を設定します。デフォルトは通常32メガバイト( 32MB ) ですが、( initdb決定されたinitdb )カーネル設定がそれをサポートしていない場合は少なくなります。この設定は少なくとも128キロバイトでなければなりません。 ( BLCKSZデフォルト以外の値では、最小値が変更されます)。ただし、通常、パフォーマンスを向上させるには最小値よりも大幅に高い設定が必要です。1GB以上のRAMを持つ専用のデータベースサーバーを使用している場合、 shared_buffers 適切な開始値はシステムのメモリの25%です。 shared_buffers大きな設定でも有効な作業負荷がありますが、Advanced Serverもオペレーティングシステムのキャッシュに依存しているため、 shared_buffersへのRAMの割り当てが40%を超える場合は、より少ないメモリ量で動作する可能性は低いです。RAMが1GB未満のシステムでは、オペレーティングシステムに十分な領域を確保するために、RAMの割合がより小さくなります(これらの状況では、メモリの15%がより一般的です)。また、Windowsでは、 shared_buffers 値が大きいほど有効ではありません。設定を比較的低く保ち、オペレーティングシステムのキャッシュを使用する方が良い結果が得られます。 Windowsシステム上のshared_buffersの有用な範囲は、通常64MBから512MBです。このパラメータを増やすと、Advanced Serverは、オペレーティングシステムのデフォルト構成で許可されているよりも多くのSystem V共有メモリを要求する可能性があります。必要に応じて、これらのパラメータを調整する方法については、 PostgreSQLコア文書の 第17.4.1項「共有メモリとセマフォ」を参照してください。3.1.3.1.2 work_memデフォルト値: 1MB範囲: 64kB〜2097151kB効果の最小スコープ:セッションごとアクティブ化に必要な承認:セッションユーザー一時ディスクファイルに書き込む前に内部ソート操作およびハッシュテーブルで使用されるメモリ量を指定します。値のデフォルトは1メガバイト( 1MB )です。複雑なクエリの場合、いくつかのソート操作またはハッシュ操作が並行して実行されている可能性があります。各操作では、一時ファイルにデータを書き込む前にこの値で指定された量のメモリーを使用することができます。また、いくつかの実行中のセッションは、そのような操作を同時に行うことができます。したがって、使用されるメモリの総量は、 work_memの値の何倍でもwork_memません。値を選択するときは、この事実を念頭に置いておく必要があります。ソート操作は、 ORDER BY 、 DISTINCT 、およびマージ・ジョインに使用されDISTINCT 。ハッシュ・テーブルは、ハッシュ・ジョイン、ハッシュ・ベースの集計、およびINサブクエリのハッシュ・ベースの処理で使用されます。3.1.3.1.3 maintenance_work_memデフォルト値: 16MB範囲: 1024kB〜2097151kB効果の最小スコープ:セッションごとアクティブ化に必要な承認:セッションユーザーVACUUM 、 CREATE INDEX 、 ALTER TABLE ADD FOREIGN KEY など、メンテナンス操作で使用するメモリの最大量を指定します。デフォルトは16メガバイト( 16MB )です。これらの操作の1つのみがデータベースセッションによって一度に実行され、通常はインストールで同時に実行されていないので、この値をwork_memよりも大幅に大きく設定することは安全work_mem 。設定を大きくすると、バキューム処理やデータベース・ダンプのリストアのパフォーマンスが向上する可能性があります。自動バキュームが実行されているときは、 autovacuum_max_workers回までこのメモリが割り当てられる可能性があるので、デフォルト値を高く設定しないように注意してください。3.1.3.1.4 wal_buffersデフォルト値: 64kB範囲: 32kBからシステムに依存効果の最小範囲:クラスター有効化に必要な権限: EPASサービスアカウントWALデータの共有メモリーで使用されるメモリー量。デフォルトは64キロバイト( 64kB )です。この設定は、1回の通常のトランザクションによって生成されるWALデータの量を保持するのに十分なだけ大きくする必要があります。これは、トランザクションコミットごとにデータがディスクに書き出されるためです。このパラメータを増やすと、Advanced Serverは、オペレーティングシステムのデフォルト構成で許可されているよりも多くのSystem V共有メモリを要求する可能性があります。必要に応じて、これらのパラメータを調整する方法については、 PostgreSQLコア文書の 第17.4.1項「共有メモリとセマフォ」を参照してください。この非常に小さな設定でも問題は必ずしも発生しませんが、余分な fsync呼び出しが発生し、システム全体のスループットが低下する可能性があります。この値を1MB程度に増やすことで、この問題を軽減することができます。非常に忙しいシステムでは、最大約16MBのさらに高い値が必要になることがあります。 shared_buffersと同様に、このパラメータはAdvanced Serverの初期共有メモリ割り当てを増加させるため、Advanced Serverの起動に失敗する場合は、オペレーティングシステムの制限を増やす必要があります。3.1.3.1.5 checkpoint_segments3.1.3.1.6 checkpoint_completion_targetパラメータタイプ:浮動小数点デフォルト値: 0.5範囲: 0〜1効果の最小範囲:クラスター値の変更が反映されるとき:リロード有効化に必要な権限: EPASサービスアカウント3.1.3.1.7 checkpoint_timeoutデフォルト値: 5分範囲: 30〜3600効果の最小範囲:クラスター値の変更が反映されるとき:リロード有効化に必要な権限: EPASサービスアカウント自動WALチェックポイント間の最大時間(秒)。デフォルトは5分( 5min )です。このパラメータを増やすと、クラッシュリカバリに必要な時間が長くなります。前述のチェックポイントパラメータを調整することの欠点は、ご使用のシステムがわずかなディスク容量を使用し、クラッシュが発生した場合に回復に時間がかかることです。ただし、ほとんどのユーザーにとって、これは パフォーマンスの大幅な向上の ために支払う小さな値段 です。3.1.3.1.8 max_wal_sizeパラメータタイプ: 整数デフォルト値: 1 GB範囲: 2〜2147483647効果の最小範囲: クラスター値の変更が反映されるとき: リロードmax_wal_size は、自動WALチェックポイント間でWALが到達する最大サイズを指定します。これはソフトな制限です。 特殊な状況(重い負荷、失敗したarchive_command、または高いwal_keep_segments設定の場合)では、 WALサイズが max_wal_size を超えることがあり ます。このパラメータを増やすと、クラッシュリカバリに必要な時間が長くなります。このパラメータは、 postgresql でのみ設定できます 。 conf ファイルまたはサーバーのコマンドラインで実行します。3.1.3.1.9 min_wal_sizeパラメータタイプ: 整数デフォルト値: 80 MB範囲: 2〜2147483647効果の最小範囲: クラスター値の変更が反映されるとき: リロードWALディスクの使用量が min_wal_size で 指定された値を下回っている場合 、古いWALファイルは、後でチェックポイントで使用するためにリサイクルされます。これにより、(大きなバッチジョブを実行する場合のように)WAL使用のスパイクを処理するのに十分なWALスペースが確保されます。このパラメータは、postgresql.confファイルまたはサーバのコマンドラインでのみ設定できます。3.1.3.1.10 bgwriter_delayデフォルト値: 200ms範囲: 10ms〜10000ms効果の最小範囲:クラスター値の変更が反映されるとき:リロード有効化に必要な権限: EPASサービスアカウントバックグラウンドライターのアクティビティラウンド間の遅延を指定します。各ラウンドでは、いくつかのダーティバッファ( bgwriter_lru_maxpagesおよびbgwriter_lru_multiplierパラメータで制御可能)の書き込みを書き込みます。その後、 bgwriter_delayミリ秒間スリープして繰り返します。デフォルト値は200ミリ秒(ある 200ms )。多くのシステムでは、スリープ遅延の実効分解能は10ミリ秒であることに注意してください。 bgwriter_delayを10の倍数以外の値に設定すると、10の次の高い倍数に設定する場合と同じ結果になることがあります。通常、 bgwriter_delay チューニングするときは、デフォルト値から減らす必要があります。おそらく、利用率が非常に低いシステムで消費電力を節約することを除いて、このパラメータはほとんど増加しません。3.1.3.1.11 seq_page_costパラメータタイプ:浮動小数点デフォルト値: 1範囲: 0〜1.79769e + 308効果の最小スコープ:セッションごとアクティブ化に必要な承認:セッションユーザーシーケンシャルフェッチの一部であるディスクページフェッチのコストのプランナの見積もりを設定します。デフォルトは1.0です。この値は、同じ名前の表領域パラメータを設定することによって、特定の表領域に対してオーバーライドできます。 ( PostgreSQL Core Documentationの ALTER TABLESPACEコマンドを参照してください )。3.1.3.1.12 random_page_costパラメータタイプ:浮動小数点デフォルト値: 4範囲: 0〜1.79769e + 308効果の最小スコープ:セッションごとアクティブ化に必要な承認:セッションユーザープランナが非シーケンシャルフェッチディスクページのコストの見積もりを設定します。デフォルトは4.0です。この値は、同じ名前の表領域パラメータを設定することによって、特定の表領域に対してオーバーライドできます。 ( PostgreSQL Core Documentationの ALTER TABLESPACEコマンドを参照してください )。この値を seq_page_costと比較して seq_page_costすると、システムは索引スキャンを優先します。索引スキャンを比較的高価に見せることになります。 cpu_tuple_costおよびcpu_index_tuple_costパラメータで記述されているCPUコストに比例したディスクI / Oコストの重要度を変更するには、両方の値を一緒にcpu_index_tuple_costできます。システムはそれを許可しますが、 random_page_costよりもseq_page_cost小さく設定しないでseq_page_cost 。しかし、データベースをメモリ内に大部分または完全に収めると、それらを等しく(または非常に近くに)設定することは理にかなっています。その場合、順不同のページに触れるためのペナルティはないからです。また、大量にキャッシュされたデータベースでは、RAM内のページをフェッチするコストが通常よりもはるかに小さいため、両方の値をCPUパラメータに対して低くする必要があります。3.1.3.1.13 effective_cache_sizeデフォルト値: 128MB範囲: 8kB〜17179869176kB効果の最小スコープ:セッションごとアクティブ化に必要な承認:セッションユーザーこのパラメータがあまりにも低く設定されている場合、計画者は有益な場合でもインデックスを使用しないことを決定する可能性があります。 effective_cache_sizeを物理メモリの50%に設定するのは、通常の保守的な設定です。より積極的な設定は、物理メモリの約75%になります。3.1.3.1.14 synchronous_commitパラメータタイプ:ブール値デフォルト値: true範囲: { true | false }効果の最小スコープ:セッションごとアクティブ化に必要な承認:セッションユーザーコマンドがクライアントに「成功」指示を返す前に、WALレコードがディスクに書き込まれるのをトランザクションコミットが待機するかどうかを指定します。デフォルトの安全な設定はオンです。オフにすると、成功がクライアントに報告されてから、トランザクションが実際にサーバークラッシュに対して安全であることが保証されるまでの間に遅延が生じる可能性があります。 (最大遅延は wal_writer_delay 3倍です)。fsync とは異なり 、このパラメータをoffに設定してもデータベースの矛盾が発生することはありません。オペレーティングシステムやデータベースのクラッシュにより、最近却下されたトランザクションの一部が失われる可能性がありますが、データベースの状態は、きれいに打ち切った。したがって、トランザクションの耐久性について正確な確信度よりもパフォーマンスが重要である場合、 synchronous_commitオフにすることは有用な選択肢になります。詳細については、「 PostgreSQL Core Documentation 」のセクション29.3「 非同期 コミット 」を参照してください。このパラメータはいつでも変更できます。任意の1つのトランザクションの動作は、コミット時に有効な設定によって決まります。したがって、いくつかのトランザクションを同期的にコミットし、他のトランザクションを非同期的にコミットすることが可能であり、有用です。たとえば、単一のマルチステートメント・トランザクションをデフォルトが反対の場合に非同期にコミットするには 、トランザクション内でSET LOCAL synchronous_commit TO OFFます。3.1.3.1.15 edb_max_spins_per_delayデフォルト値: 1000範囲: 10〜1000効果の最小範囲:クラスタごと有効化に必要な権限: EPASサービスアカウントedb_max_spins_per_delayを使用して、スピンロックを待機している間にセッションが「スピンする」最大回数を指定します。ロックが取得されない場合、セッションはスリープ状態になります。 edb_max_spins_per_delay代替値を指定しない場合、サーバーはデフォルト値の1000を適用します。3.1.3.1.16 pg_prewarm.autoprewarmパラメータタイプ:ブール値デフォルト値: true効果の最小範囲:クラスター有効化に必要な権限: EPASサービスアカウントこのパラメータは 、シャットダウン前に自動的に共有バッファをディスクにダンプするバックグラウンドワーカープロセスであるautoprewarmを データベースサーバが実行するかどうかを制御します 。次に、次回のサーバ起動時に共有バッファをプリウォームします。つまり、ディスクからブロックをバッファプールにロードします。場合 pg_prewarm.autoprewarm onに設定されている、 autoprewarm作業員が有効になっています。パラメータがoffに設定されていると、 autoprewarmは無効になります。パラメータはデフォルトでオンになっています。autoprewarmを使用する前に 、次の例に示すように、 postgresql.confファイルのshared_preload_libraries構成パラメータにリストされているライブラリに$libdir/pg_prewarmを追加する必要があります。shared _ preload _ librariesパラメータを変更した後 、データベースサーバを再起動してから、サーバが一貫性のある状態になった直後にautoprewarmバックグラウンドワーカーを起動します。autoprewarmプロセスは、以前に記録したブロックのロードを開始します$PGDATA/autoprewarm.blocksバッファプールに残された空きバッファスペースがなくなるまでに。このようにして、リカバリプロセスまたはクエリクライアントによってロードされた新しいブロックはすべて置換されません。いったん autoprewarmプロセスがディスクからバッファをロードし終えた、それは定期的にで指定した間隔でディスクに共有バッファをダンプしますpg_prewarm.autoprewarm_interval (節参照パラメータ3.1.3.1.17を )。次回のサーバーの再起動時に、 autoprewarmプロセスは最後にディスクにダンプされたブロックで共有バッファを予熱します。3.1.3.1.17 pg_prewarm.autoprewarm_intervalデフォルト値: 300秒範囲: 0〜2147483秒効果の最小範囲:クラスター値の変更が反映されるとき:リロード有効化に必要な権限: EPASサービスアカウントこれは、 autoprewarmバックグラウンドワーカーが共有バッファをディスクにダンプするまでの最小秒数です 。デフォルトは300秒です。 0に設定すると、共有バッファは定期的にダンプされませんが、サーバーがシャットダウンされたときにのみダンプされます。
3.1.3.2 リソース使用量/メモリ3.1.3.2.1 edb_dynatuneデフォルト値: 0範囲: 0〜100効果の最小範囲:クラスター有効化に必要な権限: EPASサービスアカウントAdvanced Serverを最初にインストールすると、 edb_dynatuneパラメータは、それがインストールされているホストマシン(開発マシン、混在マシン、または専用サーバー)の選択された使用状況に従って設定されます。ほとんどの場合、パフォーマンスを向上させるためにデータベース管理者がpostgresql.confファイルのさまざまな設定パラメータを調整する必要はありません。edb_dynatuneパラメータは、0以上100以下の任意の整数値に設定することができます。値0を指定すると、動的チューニング機能がオフになり、データベースサーバのリソース使用量はpostgresql.confファイルの他の設定パラメータの制御下に完全にpostgresql.confます。非ゼロの値が小さければ(例えば、1〜33)、ホスト・マシンのリソースの最小量がデータベース・サーバーに割り当てられます。この設定は、他の多くのアプリケーションが使用されている開発マシンで使用されます。edb_dynatune 値が選択されると、 postgresql.confファイル内の他の設定パラメータを調整することによって、データベースサーバのパフォーマンスをさらに微調整することができます。調整された設定は、 edb_dynatuneによって選択された対応する値を上書きします。パラメーターの値を変更するには、構成パラメーターをコメント解除し、目的の値を指定して、データベース・サーバーを再始動します。3.1.3.2.2 edb_dynatune_profileデフォルト値: oltp効果の最小範囲:クラスター有効化に必要な権限: EPASサービスアカウント
3.1.3.3 リソース使用量/ EDBリソースマネージャ3.1.3.3.1 edb_max_resource_groupsデフォルト値: 16範囲: 0〜65536効果の最小範囲:クラスター有効化に必要な権限: EPASサービスアカウントこのパラメータは、EDB Resource Managerが同時に使用できるリソースグループの最大数を制御します。 edb_max_resource_groupsで指定された値より多くのリソースグループを作成できますが 、これらのグループ内のプロセスがアクティブに使用しているリソースグループの数はこの値を超えることはできません。3.1.3.3.2 edb_resource_groupパラメータタイプ:文字列デフォルト値:なし範囲:該当なし効果の最小スコープ:セッションごとアクティブ化に必要な承認:セッションユーザー設定し edb_resource_group現在のセッションは、グループのリソースタイプの設定に応じてEDBリソースマネージャによって制御されるべきリソース・グループの名前にパラメータを。
3.1.3.4 問合せのチューニング3.1.3.4.1 enable_hintsパラメータタイプ:ブール値デフォルト値: true範囲: { true | false }効果の最小スコープ:セッションごとアクティブ化に必要な承認:セッションユーザーenable_hintsがオンの場合、SQLコマンドに埋め込まれたオプティマイザヒントが利用されます。オプティマイザのヒントは、このパラメータがオフの場合は無視されます。3.1.3.5 クエリのチューニング/プランナ・メソッドの構成3.1.3.5.1 edb_custom_plan_triesパラメータタイプ: 整数デフォルト値: 5範囲: -1〜100効果の最小スコープ: セッションごとアクティブ化に必要な承認: セッションユーザークライアントアプリケーションが準備されたステートメントを繰り返し実行する場合、サーバーは カスタム プランまたは 汎用 プランの 選択を決定する前にいくつかの実行プランを評価することを決定することがあります 。特定のワークロードでは、この余分な計画がパフォーマンスに悪影響を与える可能性があります。 edb_custom_plan_tries 構成パラメーターを 調整して 、一般プランを評価する前に考慮するカスタム計画の数を減らす ことができ ます。customer.salesman 索引が定義されている場合、 オプティマイザーは、順次スキャンを使用してこの照会を実行するか、索引スキャンを使用するかを選択できます。場合によっては、インデックスがシーケンシャルスキャンより高速です。それ以外の場合は、順次スキャンが勝利します。最適な計画は、テーブル内のセールスマン値の分布と検索値($ 1パラメーターに指定された値)によって異なります。クライアント・アプリケーションが custQuery prepared文を 繰り返し実行する と、オプティマイザはいくつかのパラメータ値固有の実行計画(カスタム計画)を生成し、その後に汎用計画(パラメータ値を無視する計画)を生成し、ジェネリックプランに固執するか、実行ごとにカスタムプランを作成し続ける必要があります。決定プロセスでは、計画を実行するコストだけでなく、カスタム計画を作成するコストも考慮されます。3.1.3.5.2 edb_enable_pruningパラメータタイプ:ブール値デフォルト値: true範囲: { true | false }効果の最小スコープ:セッションごとアクティブ化に必要な承認:セッションユーザーTRUEに設定すると 、 edb_enable_pruning使用すると、問合せプランナはパーティション表を早期にプルーニングできます。 早剪定は、クエリプランナは「プルーン」のクエリ・プランを生成する前に 、クエリで検索されないパーティション(すなわち、無視)をできることを意味します。これにより、検索されないパーティションのクエリプランが生成されなくなるため、パフォーマンスの向上に役立ちます。逆に、 遅延プルーニングとは、クエリプランナが各パーティションのクエリプランを生成した後にパーティションをプルーニングすることを意味します。 ( constraint_exclusion設定パラメータは、late-pruningを制御します。)初期プルーニング機能は、 WHERE句でのクエリの性質に依存します 。アーリー・プルーニングは、タイプWHERE column = literal ( WHERE deptno = 10 )の制約を持つ簡単なクエリでのみ利用できます。
3.1.3.6 レポート作成とロギング/ログの内容3.1.3.6.1 trace_hintsパラメータタイプ:ブール値デフォルト値: false範囲: { true | false }効果の最小スコープ:セッションごとアクティブ化に必要な承認:セッションユーザーオプティマイザヒント機能を使用して、ヒントがプランナによって使用されたかどうかに関するより詳細な情報を提供します。設定する client_min_messagesとtrace_hints次のように設定パラメータを:SELECTを使用してコマンドNO_INDEX以下に示すヒントは、上記の設定パラメータが設定されているときに生じる付加的な情報を示しています。3.1.3.6.2 edb_log_every_bulk_valueパラメータタイプ:ブール値デフォルト値: false範囲: { true | false }効果の最小スコープ:セッションごとアクティブ化に必要な権限:スーパーユーザ一括処理は、結果のステートメントをAdvanced ServerログファイルとEDB監査ログファイルの両方に記録します。しかし、一括処理における各ステートメントのロギングにはコストがかかります。これは、 edb_log_every_bulk_value構成パラメーターによって制御することができます。 trueに設定すると、一括処理のすべてのステートメントがログに記録されます。 falseに設定するfalse 、一括処理ごとにログメッセージが1回記録されます。さらに、持続時間は一括処理ごとに1回発行されます。デフォルトはfalse設定されていfalse 。
3.1.3.7 監査設定3.1.3.7.1 edb_auditデフォルト値: none効果の最小範囲:クラスター値の変更が反映されるとき:リロード有効化に必要な権限: EPASサービスアカウントデータベース監査を有効または無効にします。値 xmlまたはcsvは、データベース監査を有効にします。これらの値は、監査情報が取り込まれるファイル形式を表します。 noneはデータベース監査を無効にし、デフォルトでもあります。3.1.3.7.2 edb_audit_directoryパラメータタイプ:文字列デフォルト値: edb_audit範囲:該当なし効果の最小範囲:クラスター値の変更が反映されるとき:リロード有効化に必要な権限: EPASサービスアカウント3.1.3.7.3 edb_audit_filenameパラメータタイプ:文字列デフォルト値: audit-%Y%m%d_%H%M%S範囲:該当なし効果の最小範囲:クラスター値の変更が反映されるとき:リロード有効化に必要な権限: EPASサービスアカウント監査情報が格納される監査ファイルのファイル名を指定します。デフォルトのファイル名は audit-%Y%m%d_%H%M%Sです。エスケープシーケンス%Y 、 %mなどは、システムの日付と時刻に従って適切な現在の値に置き換えられます。3.1.3.7.4 edb_audit_rotation_dayパラメータタイプ:文字列デフォルト値: every効果の最小範囲:クラスター値の変更が反映されるとき:リロード有効化に必要な権限: EPASサービスアカウント監査ファイルをローテーションする曜日を指定します。有効な値は、 sun 、 mon 、 tue 、 wed 、 thu 、 fri 、 sat 、 every 、およびnoneです。回転を無効にするには、値をnone設定します。ファイルを毎日ローテーションするには、 edb_audit_rotation_day値をevery設定しevery 。特定の曜日にファイルを回転するには、値を希望の曜日に設定します。3.1.3.7.5 edb_audit_rotation_sizeデフォルト値: 0MB範囲: 0MB〜5000MB効果の最小範囲:クラスター値の変更が反映されるとき:リロード有効化に必要な権限: EPASサービスアカウント3.1.3.7.6 edb_audit_rotation_secondsデフォルト値: 0範囲: 0〜2147483647s効果の最小範囲:クラスター値の変更が反映されるとき:リロード有効化に必要な権限: EPASサービスアカウント3.1.3.7.7 edb_audit_connectデフォルト値: failed効果の最小範囲:クラスター値の変更が反映されるとき:リロード有効化に必要な権限: EPASサービスアカウントユーザーによるデータベース接続試行の監査を有効にします。すべての接続試行の監査を無効にするには、 edb_audit_connectをnone に設定します。失敗したすべての接続試行を監査するには、値をfailed設定します。すべての接続試行を監査するには、値をall設定します。3.1.3.7.8 edb_audit_disconnectデフォルト値: none効果の最小範囲:クラスター値の変更が反映されるとき:リロード有効化に必要な権限: EPASサービスアカウント3.1.3.7.9 edb_audit_statementパラメータタイプ:文字列デフォルト値: ddl, error範囲: { none | ddl | dml | insert | update | delete | truncate | select | error | create | drop | alter | grant | revoke | rollback | all }} ...効果の最小範囲:クラスター値の変更が反映されるとき:リロード有効化に必要な権限: EPASサービスアカウントこの構成パラメーターは、さまざまなカテゴリーのSQLステートメント、および特定のSQLコマンドに関連するステートメントの監査を指定するために使用されます。エラーを記録するには、パラメータ値を error 設定し error 。 CREATE TABLE 、 ALTER TABLEなどのすべてのDDL文を監査するには、パラメータ値をddl設定します。特定のタイプのDDL文を監査するには、パラメータ値に特定のSQLコマンド( create 、 drop 、またはalter )を含めることができます。また、オブジェクト・タイプは、次のようなコマンドに続く指定することができるcreate table 、 create view 、 drop roleなどのすべての変更文など、 INSERT 、 UPDATE 、 DELETEまたはTRUNCATE設定することにより、監査することができるedb_audit_statementするdml 。特定のタイプのDML文を監査するには、パラメータ値に特定のSQLコマンド、 insert 、 update 、 deleteまたはtruncateを含めることができます。これらのSQLコマンドに関する監査ステートメントには、パラメーター値select 、 grant 、 revoke 、またはrollbackを組み込みます。値をall設定するとall文が監査され、 noneするとこの機能は無効になります。3.1.3.7.10 edb_audit_tagパラメータタイプ:文字列デフォルト値:なし効果の最小範囲:セッションアクティブ化に必要な承認:ユーザー3.1.3.7.11 edb_audit_destinationデフォルト値: file効果の最小範囲:クラスター値の変更が反映されるとき:リロード有効化に必要な権限: EPASサービスアカウント監査ログ情報を edb_audit_directoryパラメータで指定されたディレクトリに記録するか、 syslogプロセスで管理されているディレクトリとファイルにedb_audit_directoryするかを指定します。 edb_audit_directory指定されたedb_audit_directory (デフォルト設定)を使用するようにfileに設定しfile 。設定syslogに設定されたsyslogプロセスとその場所を使用し/etc/syslog.confファイル。 注:最近のLinuxバージョンでは、syslogがrsyslogのに置き換えられていると設定ファイルがである/etc/rsyslog.conf 。3.1.3.7.12 edb_log_every_bulk_valueedb_log_every_bulk_value 、節参照3.1.3.6.2を 。
3.1.3.8 クライアント接続のデフォルト/ロケールと書式設定3.1.3.8.1 icu_short_formパラメータタイプ:文字列デフォルト値:なし範囲:該当なし効果の最小範囲:データベース値の変更が有効になった場合:該当なし構成パラメータ icu_short_formは、データベースまたはAdvanced Serverインスタンスに割り当てられたデフォルトのICU短縮形名を含むパラメータです。 ICU短縮形とUnicode照合アルゴリズムの一般的な情報については、 3.6節を参照してください。この構成パラメータは、 CREATE DATABASEコマンドをICU_SHORT_FORMパラメータ( ICU_SHORT_FORM項を参照 )とともに使用する場合に設定されます。この場合、指定された短縮形名が設定され、このデータベースに接続するときにicu_short_form構成パラメータに表示されます。 Advanced Serverインスタンスは、-- --icu_short_form option ( --icu_short_form option項を参照 )で使用されるinitdbコマンドで作成されます。この場合、指定された短縮名が設定され、そのAdvanced Serverインスタンス内のデータベースに接続されたときにicu_short_form構成パラメータに表示されますデータベースは、別の短い形式の独自のICU_SHORT_FORMパラメーターでそれをオーバーライドしません。上記の方法で確立されると、 icu_short_form設定パラメータを変更することはできません。3.1.3.9 クライアント接続のデフォルト/文の動作3.1.3.9.1 default_heap_fillfactorデフォルト値: 100範囲: 10〜100効果の最小スコープ:セッションごとアクティブ化に必要な承認:セッションユーザーテーブルのfillfactorは10〜100のパーセンテージです。100(完全詰め)がデフォルトです。より小さいfillfactorが指定されると、 INSERT操作は表のページを指定されたパーセンテージにのみパックします。各ページの残りのスペースは、そのページの行を更新するために予約されています。これにより、 UPDATEは更新された行のコピーを元のページと同じページに配置することができます。これは、別のページに配置するよりも効率的です。エントリが決して更新されないテーブルでは、完全なパッキングが最適ですが、大きく更新されたテーブルでは、より小さいfillfactorsが適切です。3.1.3.9.2 edb_data_redactionパラメータタイプ:ブール値デフォルト値: true範囲: { true | false }効果の最小スコープ:セッションごとアクティブ化に必要な承認:セッションユーザーデフォルト設定は TRUEなので、スーパーユーザーとテーブル所有者以外のすべてのユーザーにデータの変更が適用されます。
3.1.3.10 クライアント接続のデフォルト/その他のデフォルト3.1.3.10.1 oracle_homeパラメータタイプ:文字列デフォルト値:なし範囲:該当なし効果の最小範囲:クラスター有効化に必要な権限: EPASサービスアカウントOracleサーバーへのOracle Call Interface(OCI)データベース・リンクを作成する前に、Advanced Serverを正しいOracleホーム・ディレクトリに誘導する必要があります。 Linux(またはWindowsの場合はPATH ) の LD_LIBRARY_PATH環境変数をOracleクライアントのインストールディレクトリのlibディレクトリに設定します。Windowsの場合のみ、 oracle_home構成パラメータの値を postgresql.confファイルに設定できます。 oracle_home構成パラメーターで指定された値は、Windows PATH環境変数よりも優先されます。Advanced Serverを起動するたびに、Linux の LD_LIBRARY_PATH環境変数( PATH環境変数またはWindowsのoracle_home構成パラメータ)を正しく設定する必要があります。oracle_home = ' lib_directory 'oracle_home構成パラメータを設定した後は、変更を有効にするためにサーバーを再起動する必要があります。 Windowsサービスコンソールからサーバーを再起動します。3.1.3.10.2 odbc_lib_pathパラメータタイプ:文字列デフォルト値:なし範囲:該当なし効果の最小範囲:クラスター有効化に必要な権限: EPASサービスアカウントodbc_lib_path = ' complete_path_to_libodbc.so '
3.1.3.11 互換性オプション3.1.3.11.1 edb_redwood_dateパラメータタイプ:ブール値デフォルト値: false効果の最小スコープ:セッションごとアクティブ化に必要な承認:セッションユーザー場合 DATEコマンドの列のデータ・タイプとして表示され、それに変換されTIMESTAMP設定パラメータ場合、テーブル定義はデータベースに格納された時点でedb_redwood_dateに設定されているTRUE 。したがって、時間成分も日付とともに列に格納されます。edb_redwood_dateが FALSE 設定されている FALSE 、 CREATE TABLE ALTER TABLEコマンドまたはALTER TABLEコマンドの列のデータ型は、元のPostgreSQL DATEデータ型のままで、そのままデータベースに格納されます。 PostgreSQLのDATEデータ型は、列に時間コンポーネントを含まない日付のみを格納します。edb_redwood_date の設定にかかわらず、 DATEがSPL宣言セクションの変数のデータ型やSPLプロシージャまたはSPL関数の仮パラメータのデータ型などの他のコンテキストのデータ型として表示されるか、 SPL関数の戻り型では、常に内部的にTIMESTAMP変換されるため、存在する場合は時間コンポーネントを処理できTIMESTAMP 。3.1.3.11.2 edb_redwood_greatest_leastパラメータタイプ:ブール値デフォルト値: true効果の最小スコープ:セッションごとアクティブ化に必要な承認:セッションユーザーGREATEST関数は、パラメータのリストから最大の価値を持つパラメータを返します。 LEAST関数は、パラメータのリストから最小の値を持つパラメータを返します。とき edb_redwood_greatest_leastに設定されているFALSE 、NULLのパラメータは、すべてのパラメータが関数によって返される場合はnullではNULLであるとき以外は無視されます。3.1.3.11.3 edb_redwood_raw_namesパラメータタイプ:ブール値デフォルト値: false効果の最小スコープ:セッションごとアクティブ化に必要な承認:セッションユーザー場合 edb_redwood_raw_namesそのデフォルト値に設定されているFALSEレッドウッド・カタログから見たとき、等テーブル名、カラム名、トリガー名、プログラム名、ユーザ名、などのデータベース・オブジェクト名は、すなわち、接頭辞システムカタログである(大文字で表示されますALL_ 、 DBA_ 、またはUSER_ )。さらに、引用符は、囲み引用符で作成された名前を囲みます。場合 edb_redwood_raw_namesに設定されているTRUE 、データベース・オブジェクト名は、レッドウッド・カタログから見たとき、それらはPostgreSQLのシステムカタログに格納されているとおりに表示されています。したがって、引用符を囲まずに作成された名前は、PostgreSQLで期待どおり小文字で表示されます。囲み引用符で作成された名前は、作成されたとおりに正確に表示されますが、引用符は使用しません。reduser としてデータベースに接続すると、次の表が作成されます。レッドウッドのカタログから見た場合、 USER_TABLES 、とedb_redwood_raw_namesデフォルト値に設定FALSE 、名前が以外の大文字で表示されMixed_Case作成とも引用符を囲むと同じように表示される名前、。3.1.3.11.4 edb_redwood_stringsパラメータタイプ:ブール値デフォルト値: false効果の最小スコープ:セッションごとアクティブ化に必要な承認:セッションユーザー場合 edb_redwood_stringsパラメータが設定されているTRUE 、文字列はヌル変数またはnullカラムと連結されている場合、結果は元の文字列です。 edb_redwood_stringsがFALSEに設定されていると、ネイティブのPostgreSQLの動作が維持されFALSE 。これは、文字列とnull変数またはnullカラムを連結するとnullの結果になります。サンプルアプリケーションには従業員のテーブルが含まれています。この表には、ほとんどの従業員にとってNULLであるcommという名前の列があります。次のクエリは、 edb_redwood_stringをFALSE設定して実行しFALSE 。ヌル列と空でない文字列を連結すると、最終的な結果がNULLになるため、コミッションを持つ従業員だけがクエリ結果に表示されます。他のすべての従業員の出力行はNULLです。以下は、 edb_redwood_stringsがTRUE設定されているときに実行される同じクエリです。ここでは、NULL列の値は空の文字列として扱われます。空の文字列を空でない文字列と連結すると、空でない文字列が生成されます。3.1.3.11.5 edb_stmt_level_txパラメータタイプ:ブール値デフォルト値: false効果の最小スコープ:セッションごとアクティブ化に必要な承認:セッションユーザー文レベルのトランザクション分離 という用語は、SQLコマンドで実行時エラーが発生したときに、その単一のコマンドによって引き起こされたデータベース上のすべての更新をロールバックする動作を記述しています。たとえば、1つのUPDATEコマンドが5行を正常に更新するが、6行目を更新しようとすると例外が発生した場合、このUPDATEコマンドによって作成された6行すべての更新がロールバックされます。コミットまたはロールバックされていない以前のSQLコマンドの影響は、 COMMITコマンドまたはROLLBACKコマンドが実行されるまで保留されます。Advanced Serverでは、SQLコマンドの実行中に例外が発生した場合、トランザクションの開始以降、データベース上のすべての更新がロールバックされます。さらに、トランザクションは中止状態のままであり、別のトランザクションを開始する前にCOMMITまたはROLLBACKコマンドを発行する必要があります。edb_stmt_level_txがTRUEに設定されている場合 、例外は未コミットのデータベース更新を自動的にロールバックしません。 edb_stmt_level_txがFALSEに設定されているFALSE 、例外はコミットされていないデータベースの更新をロールバックします。次の例では、 edb_stmt_level_txがFALSE 、2番目のINSERTコマンドのアボートによって最初のINSERTコマンドがロールバックされることがPSQLで示されてい FALSE 。 PSQLでは、コマンド\set AUTOCOMMIT off発行\set AUTOCOMMIT off必要があります。そう\set AUTOCOMMIT offないと、すべての文が自動的にedb_stmt_level_txの効果のデモンストレーションの目的をedb_stmt_level_txます。次の例では、 edb_stmt_level_txをTRUEに設定して、2番目のINSERTコマンドで最初のINSERTコマンドがエラーの後にロールバックされていません。この時点で、最初のINSERTコマンドをコミットまたはロールバックできます。ROLLBACKコマンドが代わりに発行されている可能性がCOMMIT従業員番号の挿入、その場合には、コマンド9001同様にロールバックされていたであろう。3.1.3.11.6 db_dialectデフォルト値: postgres効果の最小スコープ:セッションごとアクティブ化に必要な承認:セッションユーザーネイティブのPostgreSQLシステムカタログ pg_catalogに加えて 、Advanced Serverには拡張カタログビューが含まれています。これは、拡張カタログ・ビューのsysカタログです。 db_dialectパラメーターは、これらのカタログが名前解決のために検索される順序を制御します。postgresに設定すると、名前空間の優先順位はpg_catalog 、次にsysになり、PostgreSQLカタログに最高の優先順位が与えられます。 redwoodに設定すると、名前空間の優先順位はsys 、次にpg_catalogになり、拡張カタログビューに最高の優先順位が与えられます。3.1.3.11.7 default_with_rowidsパラメータタイプ:ブール値デフォルト値: false効果の最小スコープ:セッションごとアクティブ化に必要な承認:セッションユーザー3.1.3.11.8 optimizer_modeデフォルト値: choose効果の最小スコープ:セッションごとアクティブ化に必要な承認:セッションユーザー
3.1.3.12 カスタマイズされたオプションAdvanced Serverの以前のリリースでは、通常、アドオンモジュール(手続き型言語など)によって追加されることが知られていないパラメータによってcustom_variable_classesが必要でした。3.1.3.12.1 custom_variable_classescustom_variable_classesパラメータは、Advanced Serverの9.2では推奨されていません。以前はこのパラメータに依存していたパラメータはもはやそのサポートを必要としません。3.1.3.12.2 dbms_alert.max_alertsデフォルト値: 100範囲: 0〜500効果の最小範囲:クラスター有効化に必要な権限: EPASサービスアカウントDBMS_ALERTSパッケージを使用して、システムで同時に許可されるアラートの最大数を指定します。3.1.3.12.3 dbms_pipe.total_message_bufferパラメータタイプ: 整数デフォルト値: 30 Kb範囲: 30 Kb〜256 Kb効果の最小範囲: クラスター値の変更が有効になった場合: 再起動有効化に必要な権限: EPASサービスアカウント3.1.3.12.4 index_advisor.enabledパラメータタイプ:ブール値デフォルト値: true効果の最小スコープ:セッションごとアクティブ化に必要な承認:セッションユーザーEDB-PSQLセッションまたはPSQLセッションでIndex Advisorを一時的に中断する機能を提供します。 index_advisor.enabled構成パラメーターを使用するには、 索引アドバイザー・プラグイン index_advisor EDB-PSQLまたはPSQLセッションにロードする必要があります。SETコマンドを使用して 、次の例に示すように、インデックスアドバイザが代替クエリプランを生成するかどうかを制御するようにパラメータ設定を変更します。3.1.3.12.5 edb_sql_protect.enabledパラメータタイプ:ブール値デフォルト値: false効果の最小範囲:クラスター値の変更が反映されるとき:リロード有効化に必要な権限: EPASサービスアカウントこれらのロールによって発行されたSQL文を解析し、 edb_sql_protect.level の設定に従って edb_sql_protect.level することによって、SQL / Protectが保護されたロールをアクティブに監視するかどうかを制御します 。 SQL / Protectで監視を開始する準備ができたら、このパラメーターをonに設定します。3.1.3.12.6 edb_sql_protect.levelデフォルト値: passive効果の最小範囲:クラスター値の変更が反映されるとき:リロード有効化に必要な権限: EPASサービスアカウントedb_sql_protect.level構成パラメータは、モード、受動モードまたはアクティブモードを使用するかについては、以下のいずれかの値に設定することができます。
3.1.3.13 グループ化されていない3.1.3.13.1 nls_length_semanticsデフォルト値: byte効果の最小スコープ:セッションごとアクティブ化に必要な権限:スーパーユーザ注意:このパラメータの設定はサーバ環境には影響しないため、システムビューpg_settingsは表示されません。3.1.3.13.2 query_rewrite_enabledデフォルト値: false効果の最小スコープ:セッションごとアクティブ化に必要な承認:セッションユーザーたとえば、次の形式の ALTER SESSIONコマンドは、構文エラーを投げずにAdvanced Serverで受け入れられますが、セッション環境は変更されません。注意:このパラメータの設定はサーバ環境には影響しないため、システムビューpg_settingsは表示されません。3.1.3.13.3 query_rewrite_integrityデフォルト値: enforced効果の最小スコープ:セッションごとアクティブ化に必要な権限:スーパーユーザたとえば、次の形式の ALTER SESSIONコマンドは、構文エラーを投げずにAdvanced Serverで受け入れられますが、セッション環境は変更されません。注意:このパラメータの設定はサーバ環境には影響しないため、システムビューpg_settingsは表示されません。3.1.3.13.4 timed_statisticsパラメータタイプ:ブール値デフォルト値: true効果の最小スコープ:セッションごとアクティブ化に必要な承認:セッションユーザー注意: Advanced Serverがインストールされている場合、 postgresql.confファイルにはtimed_statisticsをoffに設定した明示的なエントリが含まれています。 timed_statisticsをデフォルトに設定してこのエントリをコメントアウトし、設定ファイルをリロードすると、定期的な統計収集が有効になります。
3.2 索引アドバイザーIndex Advisorは、Advanced Serverのクエリプランナと連携して、クエリプランナが実行コストを計算するために使用する 仮 インデックスを作成します。索引アドバイザーは、ワークロードで提供されるSQL照会を分析して索引を識別します。
3.2.3 索引アドバイザーの使用索引アドバイザーを呼び出すときは、ワークロードを提供する必要があります。ワークロードは、クエリ(コマンドラインで指定されたもの)またはクエリのセット( pg_advise_index()関数によって実行されるもの) を含むファイルです 。ワークロードを分析した後、索引アドバイザーは、結果セットを一時表または永続表に保管します。索引アドバイザーによって生成された索引推奨事項を確認し、索引アドバイザーによって生成されたCREATE INDEXステートメントを使用して、推奨索引を作成することができます。次の例では、スーパーユーザー enterprisedbが索引アドバイザー・ユーザーであり、索引アドバイザー・データベース・オブジェクトがスーパーユーザーenterprisedb search_path内のスキーマに作成されていると想定しています 。CREATE TABLE t( a INT, b INT );
INSERT INTO t SELECT s, 99999 - s FROM generate_series(0,99999) AS s;呼び出すとき pg_advise_indexユーティリティを、次の方法で実行されるクエリが含まれるファイルの名前を含める必要がありますpg_advise_index 。クエリは同じ行にあっても、別々の行にあっても構いませんが、各クエリはセミコロンで終了する必要があります。ファイル内の照会は、 EXPLAINキーワードで始めるべきではありません。-sは、索引アドバイザーが推奨する索引の最大サイズを制限するオプションのパラメーターです。索引アドバイザーが結果セットを戻さない場合、 -sが小さすぎる可能性があります。pg_advise_indexプログラムによって表示される情報は、 index_advisor_logテーブルに記録されます。この例に示すコマンドに応答して、索引アドバイザーは次のCREATE INDEXステートメントをadvisory.sql出力ファイルに書き込みます3.2.3.2 psqlコマンドラインでのIndex Advisorの使用
3.2.4 索引アドバイザーの推奨事項の確認
3.3 SQLプロファイラ非効率的なSQLコードは、データベースのパフォーマンス問題の主な原因ではないにしても、その1つです。データベース管理者と開発者の課題は、大規模で複雑なシステムでこのコードを見つけて最適化することです。SQLプロファイラは、実行中のSQLコードを見つけて最適化するのに役立ちます。
3.4 pgsnmpdpgsnmpdは、Linuxシステム上のAdvanced Serverの現在の状態に関する階層情報を返すことができるSNMPエージェントです。 pgsnmpdはedb-as xx -pgsnmpd RPMパッケージを使用して配布され、インストールされます。ここで、 xxはAdvanced Serverのバージョン番号です。 pgsnmpdエージェントは、スタンドアロンSNMPエージェント、パススルーサブエージェント、またはAgentXサブエージェントとして動作できます。このコマンドは、 LD_LIBRARY_PATH の値を永続的に変更しません 。 LD_LIBRARY_PATHの値を永続的に設定する方法については、Linuxディストリビューションのドキュメントを参照してください。以下の例は、 pgsnmpd の最も単純な使い方を pgsnmpd 、読み取り専用アクセスを実装しています。 pgsnmpdはnet-snmpライブラリに基づいています。 net-snmpの詳細については、次のサイトを参照してください。3.4.1 pgsnmpdの設定pgsnmpd設定ファイルの名前はsnmpd.conf 。設定ファイルで指定できるディレクティブについては、 snmpd.conf manページ( man snmpd.conf )を参照してください。設定ファイルは手作業で作成することも、 snmpconf perlスクリプトを使って設定ファイルを作成することもできます。 perlスクリプトはnet-snmpパッケージとともに配布されています。snmpconfはメニュー駆動のウィザードです。メニュー項目1: snmpd.confを選択して設定ウィザードを開始します。 snmpconfで表示される各トップレベルメニューオプションを選択すると、ウィザードで一連の質問が表示され、設定ファイルのビルドに必要な情報が表示されます。ご使用のシステムに関連するカテゴリーごとに情報を入力したら、 Finishedを入力してsnmpd.confという名前の構成ファイルを生成します。ファイルを次の場所にコピーします。3.4.2 リスナー・アドレスの設定snmpd.confファイルに次の行を追加することによって、代替リスナー・ポートを指定することができます 。agentaddress $host_address :20003.4.3 pgsnmpdの呼び出しAdvanced Serverのインスタンスが稼働していることを確認します( pgsnmpdはこのサーバーに接続します)。次の形式のコマンドを使用してpgsnmpdを呼び出す前に、コマンドラインを開いてスーパーユーザー権限を引き受けます。POSTGRES_INSTALL_HOME /bin/pgsnmpd -b-c POSTGRES_INSTALL_HOME /share/snmpd.confどこ POSTGRES_INSTALL_HOME Advanced Serverのインストールディレクトリを指定します。3.4.4 pgsnmpdヘルプの表示3.4.5 pgsnmpdからの情報の要求-v 2cオプションは、SNMPバージョン2c形式で要求を送信するようにsnmpgetnextクライアントに指示します。-c publicコミュニティ名を指定します。localhostは、 pgsnmpdサーバーを実行するホストマシンを示します。.1.3.6.1.4.1.5432.1.4.2.1.1.0は、要求されたオブジェクトの識別情報です。すべてのデータベースのリストを表示するには、最後の数字を1だけ増やします(たとえば、1.1、.1.2、.1.3など)。
3.5 EDB監査ロギングAdvanced Serverを使用すると、データベース管理者、監査者、およびオペレータは、 EDB監査ログ機能を使用して、データベースアクティビティを追跡および分析できます 。 EDB監査ログは、すべての関連情報を含む監査ログファイルを生成します。監査ログは、次のような情報を記録するように構成できます。3.5.1 監査ログ設定パラメータデータベース監査を制御するには、次の構成パラメータを使用します。 3.1.2 項を参照して、構成パラメータへの変更がすぐに有効になるか、構成を再ロードする必要があるか、またはデータベース・サーバーを再起動する必要があるかどうかを確認してください。データベース監査を有効または無効にします。値 xmlまたはcsvは、データベース監査を有効にします。これらの値は、監査情報が取り込まれるファイル形式を表します。 noneはデータベース監査を無効にし、デフォルトでもあります。ログファイルを作成するディレクトリを指定します。ディレクトリのパスは、データフォルダの相対パスまたは絶対パスにすることができます。デフォルトは、 PGDATA/edb_auditディレクトリです。監査情報が格納される監査ファイルのファイル名を指定します。デフォルトのファイル名は audit-%Y%m%d_%H%M%Sです。エスケープシーケンス%Y 、 %mなどは、システムの日付と時刻に従って適切な現在の値に置き換えられます。監査ファイルをローテーションする曜日を指定します。有効な値は、 sun 、 mon 、 tue 、 wed 、 thu 、 fri 、 sat 、 every 、およびnoneです。回転を無効にするには、値をnone設定します。ファイルを毎日ローテーションするには、 edb_audit_rotation_day値をevery設定しevery 。特定の曜日にファイルを回転するには、値を希望の曜日に設定します。 everyがデフォルト値です。ユーザーによるデータベース接続試行の監査を有効にします。すべての接続試行の監査を無効にするには、 edb_audit_connectをnone に設定します。失敗したすべての接続試行を監査するには、値をfailedに設定します。これがデフォルトです。すべての接続試行を監査するには、値をall設定します。この構成パラメーターは、さまざまなカテゴリーのSQLステートメントの監査を指定するために使用されます。 none 、 dml 、 insert 、 update 、 delete 、 truncate 、 select 、 error 、 rollback 、 ddl 、 create 、 drop 、 alter 、 grant 、 revoke 、およびall さまざまな組み合わせを指定できます 。デフォルトはddlとerrorです。このパラメータの設定については、 3.5.2項を参照してください。一括処理は、結果のステートメントをAdvanced ServerログファイルとEDB監査ログファイルの両方に記録します。しかし、一括処理における各ステートメントのロギングにはコストがかかります。これは、 edb_log_every_bulk_value構成パラメーターによって制御することができます。 trueに設定すると、一括処理のすべてのステートメントがログに記録されます。 falseに設定するfalse 、一括処理ごとにログメッセージが1回記録されます。さらに、持続時間は一括処理ごとに1回発行されます。デフォルトはfalseです。監査ログ情報を edb_audit_directoryパラメータで指定されたディレクトリに記録するか、 syslogプロセスで管理されているディレクトリとファイルにedb_audit_directoryするかを指定します。デフォルトの設定であるedb_audit_directoryで指定されたディレクトリを使用するようにfileに設定しfile 。設定syslogに設定されたsyslogプロセスとその場所を使用し/etc/syslog.confファイル。 注:最近のLinuxバージョンでは、syslogがrsyslogのに置き換えられていると設定ファイルがである/etc/rsyslog.conf 。3.5.2 監査するSQL文の選択edb_audit_statementステートメントが監査されるべきSQLを制御するための1つ以上、カンマ区切り値の包含を可能にします。一般的な形式は次のとおりです。
3.6 Unicode照合アルゴリズムUnicode照合アルゴリズム (UCA)は、照合およびUnicodeデータを比較するカスタマイズ可能な方法を定義する仕様( ユニコードテクニカルレポート#10)です。 照合とは、 SELECT … ORDER BY節のようにデータがどのようにソートされるかを意味します。 比較は、演算子がより小さい、より大きい、または等しい演算子を持つ範囲を使用する検索に関連します。注意:さらに、ICU照合(Unicode照合アルゴリズムの実装)を使用するもう1つの利点は、パフォーマンスのためです。 Bツリーインデックスの作成を含むソートタスクは、ICU以外の照合に要する時間の半分以下で完了することができます。パフォーマンスの向上は、オペレーティングシステムのバージョン、テキストデータの言語、およびその他の要因によって異なります。
3.6.1 基本的なUnicode照合アルゴリズムの概念
3.6.2 Unicodeのための国際コンポーネントUnicode照合アルゴリズムは、 International Components for Unicode (ICU)が提供するオープンソースソフトウェアによって実装されています 。このソフトウェアは、C / C ++およびJavaライブラリのセットです。3.6.2.1 ロケールの照合順序システムカタログ pg_catalog.pg_icu_collate_namesは、ロケールのICU短縮形の名前のリストが含まれています。 ICU短縮形名はicu_short_form列にリストされています。3.6.2.2 照合属性ICU照合を作成する場合、照合の望ましい特性を指定する必要があります。セクション 3.6.2.1で説明したように 、これは通常、目的のロケールのICU短縮形式で実行できます。ただし、より具体的な情報が必要な場合は、 照合属性を使用して照合プロパティの指定を行うことができます 。各照合属性は、大文字で表され、次の箇条書きのポイントにリストされています。各属性の可能な有効値は、カッコ内に示されたコードによって与えられます。コードによっては、すべての属性に一般的な意味があります。 Xは属性をオフにすることを意味します。 Oは属性をオンにすることを意味します。 Dは属性をデフォルト値に設定することを意味します。
3.6.3 ICUの照合順序の作成
3.6.4 照合順序の使用新たに定義されたICUの照合は、 COLLATION " collation_name "句をCREATE TABLEコマンドの列指定などのSQLコマンドで使用したり、 SELECTコマンドのORDER BY句の式に追加することができます。以下は、米国の英語に基づくICU照合の作成と使用の例です( en_US.UTF8 )。注意:照合順序を作成するときに、 LROOT照合を変更する属性が与えられた場合、ICUは通知および警告メッセージを生成することがあります。次の psqlコマンドは、照合をリストします。次のクエリは 、照合icu_collate_lowercaseを使用して列 c2をソートします 。これは、小文字の書式を同じ基本文字の大文字の前にソートするよう強制します。また、ご注意AN持つ行ように、基本文字を比較するとき、同じレベルのソート順に含まれるように力変数の文字属性idの値が9 、 10 、および11 、すべての文字と数字の前にソートリストの先頭に表示されます。カラム上の次のクエリソート c2照合使用icu_collate_ignore_punct持つ行に無視する変数文字を生じ、 id値9 、 10 、および11文字でソートBそれは直ちに無視可変文字の次の文字であるようにします。次の照会は 、照合icu_collate_ignore_white_spを使用して列 c2をソートします 。照合のASおよびT0020属性は、16進数0020以下のコード・ポイントを持つ可変文字を無視し、16進数0020以上のコード・ポイントを持つ可変文字を無視します。空白文字(16進数0020 )で始まるid値が11 の行は 、文字Bソートされます。これらの特定の可変文字は、基本文字の比較時に同じレベルのソート順に含まれるため、ソートリストの先頭には、16進数の0020よりも目に見える句読点で始まる9と10 id値を持つ行がソートリストの先頭に表示されます。
initdbユーティリティー・プログラムを使用してデータベース・クラスターを作成する場合、各WALセグメント・ファイルのデフォルト・サイズは16 MBです。Advanced Server initdbユーティリティーは、新しいデータベース・クラスターを作成するときにWALセグメント・ファイルのサイズを指定するための追加の--wal-segsizeオプションを提供します。sizeはメガバイト単位のWALセグメントファイルサイズで、2の累乗でなければなりません(たとえば、1,2,4,8,16,32など)。 sizeの最小許容値は1、最大許容値は1024です。データベースクラスタはdirectoryに作成されます。
4 セキュリティ
Advanced Serverは、SQLインジェクション攻撃に対する保護機能を提供します。 SQLインジェクション攻撃は、その結果、そのデータベースの内容、構造、またはセキュリティに関しては、攻撃者への手がかりを提供するSQL文を実行してデータベースを侵害しようとする試みです。SQL / Protectは、データベース管理者がSQLインジェクション攻撃からデータベースを保護するためのモジュールです。 SQL / Protectは、通常のデータベースセキュリティポリシーに加えて、一般的なSQLインジェクションプロファイルの入力クエリを調べることによって、セキュリティレイヤーを提供します。
4.1.1 SQL /保護の概要4.1.1.1 SQLインジェクション攻撃のタイプSQLインジェクション攻撃を阻止するために使用されるさまざまな手法がいくつかあります。各手法は、特定の シグネチャ によって特徴付けられ ます 。 SQL / Protectは、次のシグネチャの照会を検査します。Advanced Serverでは管理者がリレーション(テーブル、ビューなど)へのアクセスを制限できますが、多くの管理者はこの面倒な作業を実行しません。 SQL / Protectは 、ユーザーがアクセスする関係を追跡する 学習モードを提供します。SQLインジェクション攻撃中に行われる危険なアクションは、無制限のDMLステートメントの実行です。これらは WHERE句のないUPDATE文とDELETE文です。たとえば、攻撃者は、すべてのユーザーのパスワードを既知の値に更新したり、キーテーブル内のすべてのデータを削除してサービス拒否攻撃を開始することがあります。4.1.1.2 SQLインジェクション攻撃の監視4.1.1.2.1 保護されたロールSQLインジェクション攻撃を監視するには、セッションの現在のユーザーが保護された役割であるデータベースセッションで発生したSQLステートメントを分析する必要があります。 保護された役割は、データベース管理者は、保護/ SQLを使用して監視することを選択したAdvanced Serverのユーザーまたはグループです。 (Advanced Serverでは、ユーザーとグループを総称してロールと呼びます 。)注:スーパーユーザー権限を持つロールを保護されたロールにすることはできません。保護されていない非スーパーユーザーロールがその後スーパーユーザーになるように変更された場合、そのスーパーユーザーがコマンドを発行しようとするたびに特定の動作が表示されます。
4.1.2 SQL / Protectの構成ライブラリファイル( sqlprotect.so Linuxでは、上のsqlprotect.dll保護/ SQLを実行するために必要なWindows上では)にインストールする必要がありますlibあなたのAdvanced Serverのホーム・ディレクトリのサブディレクトリ。 Windowsの場合、これはAdvanced Serverインストーラで行う必要があります。 Linuxの場合、 edb-as xx -server-sqlprotect RPMパッケージをインストールします。ここで、 xxはAdvanced Serverのバージョン番号です。
4.1.3 一般的な保守作業4.1.3.1 保護されたロールリストへのロールの追加4.1.3.2 保護されたロールリストからのロールの削除注意:保護ロールリストからロールを削除する前に、 DROP ROLEまたはDROP USER SQL文を使用してロールを削除すると、OIDを使用するファンクションのバリエーションが役立ちます。 SQL / Protectリレーションに対するクエリで、ユーザー名にunknown (OID=16458)などの値が返された場合は、関数のunprotect_role( roleoid )形式を使用して、削除されたロールのエントリを保護ロールリストから削除します。unprotect_role関数の例を次に示します。4.1.3.3 ロールの保護のタイプの設定役割の保護を無効または有効にするSQLインジェクション攻撃の種類に対応するedb_sql_protect の列のブール値を変更します。
注意:このセクションは、バックアップおよびリストア手順によって、 pg_dumpバックアッププログラムを使用する場合のように、新しいOIDを使用して新しいデータベースにデータベースオブジェクトを再作成する場合に適用されます。4.1.4.1 SQL / Protectテーブルのオブジェクト識別番号SQL / Protectは2つのテーブル edb_sql_protectとedb_sql_protect_relを使用して、データベース、ロール、リレーションなどのデータベースオブジェクトに関する情報を格納します。これらのテーブル内のこれらのデータベースオブジェクトへの参照は、オブジェクトのテキスト名ではなく、オブジェクトのOIDを使用して行われます。 OIDは、Advanced Serverが各データベースオブジェクトを一意に識別するために使用する数値データ型です。データベース・オブジェクトが作成されると、Advanced ServerはオブジェクトにOIDを割り当てます.OIDは、データベース・カタログ内のオブジェクトへの参照が必要な場合に使用されます。 2つのデータベース(同じ CREATE TABLEステートメントを持つテーブルなど)に同じデータベースオブジェクトを作成すると 、各テーブルには各データベースの異なるOIDが割り当てられます。バックアップおよびリストア操作で、バックアップされたデータベースオブジェクトが再作成されると、復元されたオブジェクトは元のデータベースで割り当てられたものとは異なる新しいOIDで新しいデータベースに格納されます。その結果、に保存されているデータベース、役割、および関係参照のOID edb_sql_protectとedb_sql_protect_relこれらのテーブルは、単にバックアップファイルにダンプし、新しいデータベースに復元されたときに、テーブルは、もはや有効ではありません。以下のセクションでは、 export_sqlprotectとimport_sqlprotect 2つの関数について説明します。 export_sqlprotect 関数は、 SQL / ProtectテーブルのOIDがSQL / Protectテーブルの復元後に正しいデータベースオブジェクトを参照するように、SQL / Protectテーブルのバックアップと復元に使用されます。4.1.4.2 データベースのバックアップステップ1: pg_dumpを使用してバックアップファイルを作成します。手順2:スーパーユーザーとしてデータベースに接続し、 export_sqlprotect(' sqlprotect_file ')関数を使用してSQL / Protectデータをエクスポートします。ここでsqlprotect_fileは、SQL / Protectデータを保存するファイルの完全修飾パスです。enterprisedb 、オペレーティング・システム・アカウント( postgresあなたは、PostgreSQLの互換モードでAdvanced Serverをインストールした場合)読みとで指定されたディレクトリへのアクセスの書き込みしている必要がありますsqlprotect_file 。4.1.4.3 バックアップファイルからの復元手順1:バックアップファイルを新しいデータベースに復元します。次の例では、 psqlユーティリティー・プログラムを使用して 、プレーン・テキスト・バックアップ・ファイル/tmp/edb.dmpをnewdbという名前の新しく作成されたデータベースにリストアします。ステップ2:新しいデータベースにスーパーユーザーとして接続し、 edb_sql_protect_relテーブルからすべての行を削除します。この手順は 、元のデータベースからバックアップされた edb_sql_protect_relテーブル内の既存の行をすべて削除します。これらの行には、バックアップ・ファイルがリストアされたデータベースに対する正しいOIDは含まれていません。ステップ3: edb_sql_protectテーブルからすべての行を削除します。この手順では 、元のデータベースからバックアップされた edb_sql_protectテーブル内の既存の行がすべて削除されます。これらの行には、バックアップ・ファイルがリストアされたデータベースに対する正しいOIDは含まれていません。ステップ4:データベースに存在する可能性のある統計情報をすべて削除します。手順5:データベースに存在する可能性のある問題のあるクエリをすべて削除します。手順6:元のデータベースのSQL / Protectで保護されていた役割名が、新しいデータベースが存在するデータベースサーバーに存在することを確認します。手順7:関数import_sqlprotect(' sqlprotect_file ')ここで、 sqlprotect_fileは、 4.1.4.2項の手順2で作成したファイルへの完全修飾パスです 。テーブル edb_sql_protectおよびedb_sql_protect_relに、新しいデータベースに割り当てられたデータベースオブジェクトのOIDを含むエントリが入力されるようになりました。統計ビューedb_sql_protect_statsも元のデータベースからインポートされた統計が表示されるようになりました。
4.2 仮想プライベートデータベース仮想プライベート・データベースは、セキュリティ・ポリシーを使用したファイングレイン・アクセス制御の一種です。バーチャルプライベートデータベースでのきめ細かなアクセス制御とは、データへのアクセスをセキュリティポリシーで定義されている特定の行まで制御できることを意味します。セキュリティポリシーをエンコードするルールは、特定の入力パラメータと戻り値を持つSPL関数であるポリシー関数で定義されます。 セキュリティポリシーは、特定のデータベースオブジェクト(通常はテーブル)に対するポリシー関数の名前付きの関連付けです。注意: Advanced Serverでは、SPLに加えてSQLやPL / pgSQLなどのAdvanced Serverでサポートされている言語でポリシー機能を記述できます。注意: Advanced Server Virtual Private Databaseで現在サポートされているデータベースオブジェクトはテーブルです。ポリシーをビューまたは同義語に適用することはできません。
4.3 sslutilssslutilsは、EDB Postgres Enterprise Managerサーバで使用するためにSSL証明書生成機能をAdvanced Serverに提供するPostgres拡張sslutilsです。 sslutils使用してインストールされるedb-as xx -server-sslutils RPMパッケージxx Advanced Serverのバージョン番号です。sslutilsパッケージには、以下のセクションに示す機能を提供します。これらのセクションでは、関数のパラメータリスト内の各パラメータによって記述される parameter n パラメータ項の下でn指すn関数のパラメータリスト内の順序位置番目(例えば、第一、第二、第三、等)。4.3.1 openssl_rsa_generate_keyopenssl_rsa_generate_key機能は、RSA秘密鍵を生成します。関数のシグネチャは次のとおりです。4.3.2 openssl_rsa_key_to_csropenssl_rsa_key_to_csr機能は、証明書署名要求(CSR)を生成します。署名は次のとおりです。署名要求を使用するエージェントの共通名( agentN )。4.3.3 openssl_csr_to_crtopenssl_csr_to_crt機能は、自己署名証明書または認証局の証明書を生成します。署名は次のとおりです。認証局証明書へのパス 。認証局証明書を生成する場合はNULL 。4.3.4 openssl_rsa_generate_crlopenssl_rsa_generate_crl機能は、デフォルトの証明書失効リストを生成します。署名は次のとおりです。
4.4 データの改ざんデータの改ざんは、特定のユーザーに対して表示されるデータを動的に変更することによって機密データの暴露を制限する手法です。たとえば、社会保障番号(SSN)は 021-23-9567 として格納され 021-23-9567 。特権ユーザーには完全なSSNが表示され、他のユーザーには最後の4桁のxxx-xx-9567しか表示されxxx-xx-9567 。これらの関数は、 CREATE REDACTION POLICYコマンドを使用して、変更ポリシーに組み込まれます。このコマンドは、ポリシーが適用されるテーブル、指定された編集機能によって影響を受けるテーブルの列、影響を受けるセッションユーザーを決定する式、およびその他のオプションを指定します。
4.4.1 リセッション・ポリシーの作成CREATE REDACTION POLICYは、テーブルの新しいデータ変更ポリシーを定義します。[ FOR ( expression ) ]ここで、 redaction_optionは次のとおりです。CREATE REDACTION POLICYコマンドが改訂関数を使用して列データをredactingによってテーブルの新しい列レベルのセキュリティポリシーを定義します。新しく作成されたデータ変更ポリシーは、デフォルトで有効になります。ポリシーは、 ALTER REDACTION POLICY ... DISABLEを使用して無効にすることができます。このオプションのフォームは、テーブルの列をデータ編集ポリシーに追加します。 USING改訂の関数式を指定します。複数のADD [ COLUMN ]フォームを使用して、テーブルの複数の列を作成するデータ書き換えポリシーに追加することができます。オプションのWITH OPTIONS ( ... )句は、適用されるデータ変更ポリシーの有効範囲および/または例外を指定します。スコープおよび/または例外を指定しない場合、スコープおよび例外のデフォルト値はそれぞれqueryおよびnoneなりquery 。スコープでは、列に適用される編集が行われるクエリ部分が特定されました。スコープ値は、 query 、 top_tlistまたはtop_tlist_or_errorです。スコープがquery場合、 queryに表示される場所に関係なく、列に適用されます。スコープがtop_tlist場合は、クエリの最上位のターゲットリストに表示されたときにのみ、列に適用されます。スコープがある場合top_tlist_or_error動作と同じになりますtop_tlistが、カラムは、クエリのどこにも表示されたときにエラーがスローされます。例外は、除外されるべき編集部分を特定した。例外値は、 none 、 equalまたはleakproofです。例外がnone場合、免除はありません。例外がequal場合は、等価テストで使用されたときには列は編集されません。例外がleakproof場合、漏れ防止機能が適用されても列は編集されません。employeesに対して、デフォルトのスコープと例外を使用して等価条件とsalaryでアクセス可能である列ssnを編集するためのデータ整理ポリシーを作成します。 redactionポリシーは、 hrユーザーには適用されません。hrユーザーの表示可能なデータは次のとおりです。
4.4.2 ALTER REDACTION POLICYALTER REDACTION POLICYは、表のデータ変更ポリシーの定義を変更します。[ WITH OPTIONS ( [ redaction_option ][, redaction_option ] )MODIFY [ COLUMN ] column_name[ USING funcname_clause ][ WITH OPTIONS ( [ redaction_option ][, redaction_option ] )DROP [ COLUMN ] column_nameここで、 redaction_optionは次のとおりです。ALTER REDACTION POLICYは、既存のデータ修正ポリシーの定義を変更します。ALTER REDACTION POLICY を使用するには、データ変更ポリシーが適用されるテーブルを所有している必要があります。このフォームは、表の列に対するデータ変更ポリシーを変更します。列のredaction function節および/またはredactionオプションを更新できます。 USING句は、改訂の関数式を更新する指定し、 WITH OPTIONS ( ... )句は、適用範囲および/または例外を指定します。 redaction関数節、redactionスコープ、およびredaction例外の詳細については、「 CREATE REDACTION POLICY 」を参照してください。列のデータ修正関数式。詳細については、 CREATE REDACTION POLICYを参照してください。ALTER REDACTION POLICYは、EnterpriseDBの拡張機能です。
4.4.3 ドロップ・リセッション・ポリシーDROP REDACTION POLICYは、テーブルからデータ変更ポリシーを削除します。DROP REDACTION POLICYは、指定されたデータ変更ポリシーをテーブルから削除します。DROP REDACTION POLICY を使用するには、変更ポリシーが適用されるテーブルを所有している必要があります。employeesという名前のテーブルにredact_policy_personal_info というデータ変更ポリシーをドロップするには、 redact_policy_personal_infoにします。DROP REDACTION POLICYは、EnterpriseDBの拡張機能です。
4.4.4 システムカタログ4.4.4.1 edb_redaction_columnカタログ edb_redaction_columnは、表の列にアタッチされたデータ変更ポリシーの情報が格納されます。
EDBリソースマネージャは、Advanced Serverプロセスで使用されるオペレーティングシステムリソースの使用を制御する機能を提供するAdvanced Server機能です。
5.1 リソースグループの作成と管理5.1.1 リソースグループの作成新しいリソース・グループを作成するには、 CREATE RESOURCE GROUPコマンドを使用します。CREATE RESOURCE GROUPコマンドは、指定された名前を持つリソース・グループを作成します。 ALTER RESOURCE GROUPコマンドを使用して、グループでリソース制限を定義できます。リソースグループは、Advanced Serverインスタンスのすべてのデータベースからアクセスできます。CREATE RESOURCE GROUPコマンドを使用するには、スーパーユーザー権限が必要です。5.1.2 ALTER RESOURCE GROUPALTER RESOURCE GROUPコマンドは、既存のリソース・グループの特定の属性を変更します。RENAME TO句を含む最初の形式は、既存のリソースグループに新しい名前を割り当てます。SET resource_type TO句を使用する2番目の形式は、指定されたリテラル値をリソース・タイプに割り当てるか、またはDEFAULTが指定されたときにリソース・タイプをリセットします。リソースタイプをDEFAULTリセットまたは設定するということは、リソースグループにそのリソースタイプに定義された制限がないことを意味します。ALTER RESOURCE GROUPコマンドを使用するには、スーパーユーザー権限が必要です。value | DEFAULT5.1.3 DROP RESOURCE GROUPDROP RESOURCE GROUPコマンドは、指定した名前のリソース・グループを削除します。DROP RESOURCE GROUPコマンドを使用するには、スーパーユーザー権限が必要です。5.1.4 リソース・グループへのプロセスの割当てプロセスは、デフォルトでは、ロール、データベース、またはデータベースサーバーインスタンス全体にデフォルトのリソースグループを割り当てることによって、リソースグループにデフォルトで含めることができます。ALTER ROLE ... SETコマンドを使用して、デフォルトのリソースグループを役割に割り当てることができます 。 ALTER ROLEコマンドの詳細については、次のURLにあるPostgreSQLのコアドキュメントを参照してください。デフォルトのリソースグループは、 ALTER DATABASE ... SETコマンドによってデータベースに割り当てることができます 。 ALTER DATABASEコマンドの詳細については、次のURLにあるPostgreSQLのコアドキュメントを参照してください。postgresql.confファイルのedb_resource_group構成パラメータをedb_resource_groupように設定すると、 データベース・サーバー・インスタンス全体にデフォルト・リソース・グループを割り当てることができます。5.1.5 リソース・グループからのプロセスの削除デフォルトのリソースグループをデータベースサーバインスタンスから削除するには、 postgresql.confファイルでedb_resource_group設定パラメータを空の文字列に設定し、設定ファイルをリロードします。5.1.6 リソース・グループ内のプロセスの監視edb_all_resource_groups の列は次のとおりです。
5.2 CPU使用量の調整cpu_rate_limitパラメータを、グループ内のすべてのプロセスのCPU同時使用が同時に超過しないように、ウォールクロック時間を超えるCPU時間の割合に設定します。したがって、 cpu_rate_limit割り当てられる値は、通常、1以下である必要があります。cpu_rate_limitパラメータの有効範囲は 0〜1.67772e + 07です。 0に設定すると、リソースグループにCPUレート制限が設定されていないことを意味します。100を掛け合わせると、 cpu_rate_limitはリソースグループのCPU使用率として解釈することもできます。EDBリソースマネージャは 、 cpu_rate_limitパラメータで指定された制限内で、グループ内のすべてのプロセスのCPU使用量を集計するためにCPUスロットルを使用します。グループ内のプロセスは、定義された制限を維持するために中断され、短時間の間スリープモードに入ることがあります。このような中断がいつどのように発生するかは、EDB Resource Managerが使用する独自のアルゴリズムによって定義されます。5.2.1 リソース・グループのCPUレート制限の設定ALTER RESOURCE GROUPでコマンドSET cpu_rate_limit句は、リソースグループのCPUレート制限を設定するために使用されます。次の例では、CPU使用率の上限は resgrp_aでは50%、 resgrp_aでは40%、 resgrp_b 30%にresgrp_cます。これは、 resgrp_a割り当てられたすべてのプロセスのCPU使用率のresgrp_aが約50%に維持されていることを意味します。同様に、 resgrp_bすべてのプロセスで、CPU使用率の合計は約40%に維持されます。リソースグループのcpu_rate_limitを変更すると、そのグループに割り当てられている新しいプロセスに影響するだけでなく、そのグループのメンバーである現在実行中のプロセスは、変更の影響を直ちに受けます。つまり、 cpu_rate_limitが.5から.3に変更された場合、グループ内の現在実行中のプロセスは、グループ全体のCPU使用率が50%ではなく30%近くになるように、下向きに抑制されます。リソースグループのCPUレート制限を設定する効果を説明するために、次の例では、 SELECT 20000!; クエリによって実行される20000階乗(20000 * 19999 * 19998などの乗算)のCPU集約的な計算を使用しています SELECT 20000!; psqlコマンドラインユーティリティで実行します。5.2.2 例 - 単一グループ内の単一プロセス2番目のセッションでは、Linux topコマンドを使用して%CPU列の下に示すようにCPU使用率を表示します。以下は、 topコマンドの出力が定期的に変化するときの任意の時点でのスナップショットです。psql階乗演算を行うセッションは、行によって示されているedb-postgres下に表示されるCOMMANDカラム。 %CPU列の下に表示されるセッションのCPU使用率は39.9です。これはリソースグループresgrp_b設定されている40%CPU制限に近い値resgrp_b 。対照的に、 psqlセッションがリソースグループから削除され、階乗計算が再度実行されると、CPU使用率がはるかに高くなります。5.2.3 例 - 単一グループ内の複数のプロセス次のコマンドシーケンスは、半分の時間間隔でサンプリングされたすべての edb-postgresプロセスの合計を表示します。これは、EDB Resource Managerがプロセスを抑制して、リソースグループ全体のCPU使用率を40%近くに抑えるように、リソースグループ内のプロセスのCPU使用率がどのように変化するかを示しています。5.2.4 例 - 複数のグループの複数のプロセスこの例では、2つの追加の psqlセッションが前の2つのセッションとともに使用されています。 3番目と4番目のセッションでは、リソースグループresgrp_c内でcpu_rate_limitが.3 (CPU使用率が30%)という同じ階乗計算が実行されます。topコマンドは次の出力が表示されます。使用されている2つのリソースグループのCPU使用率は、40%と30%です。最初の2つのedb-postgresプロセスの %CPU列の合計は39.5(約40%、 resgrp_bの制限)、3番目と4番目のedb-postgresプロセスの%CPU列の合計は31.6(約30%、これはresgrp_cの制限です)。CPU使用率が40%に制限されているリソースグループに属している2番目と3番目の edb-postgresプロセスの総CPU使用量は37.8です。しかし、最初のedb-postgresプロセスは、リソースグループ内にないため、58.6%のCPU使用率を持ち、基本的に残りの使用可能なCPUリソースをシステム上で利用します。
5.3 ダーティバッファースロットルdirty_rate_limitパラメータを、グループ内のすべてのプロセスが共有バッファに書き込むか、または「ダーティ」にする結合レートの1秒あたりのキロバイト数に設定します。設定例は3072キロバイト/秒です。dirty_rate_limitパラメータの有効範囲は 0〜1.67772e + 07です。 0に設定すると、リソースグループにダーティレート制限が設定されていないことを意味します。EDBリソース・マネージャは 、 dirty_rate_limitパラメータで指定された限界に近いグループ内のすべてのプロセスの集約された共有バッファ書き込み率を維持するために、 ダーティ・バッファ・スロットルを使用します。グループ内のプロセスは、定義された制限を維持するために中断され、短時間の間スリープモードに入ることがあります。このような中断がいつどのように発生するかは、EDB Resource Managerが使用する独自のアルゴリズムによって定義されます。5.3.1 リソース・グループのダーティ・レート制限の設定ALTER RESOURCE GROUPでコマンドSET dirty_rate_limit句は、リソースグループの汚れたレート制限を設定するために使用されています。次の例では、ダーティレートの制限は resgrp_a 場合は12288キロバイト/秒、 resgrp_a場合は6144キロバイト/秒、 resgrp_b 3072キロバイト/秒にresgrp_cます。これは、 resgrp_a割り当てられたすべてのプロセスの共有バッファへの合計書き込み速度が約12288キロバイト/秒に維持されることをresgrp_aます。同様に、 resgrp_b内のすべてのプロセスについて、共有バッファへの結合書き込み速度は約6144キロバイト/秒に維持されます。リソースグループのdirty_rate_limitを変更すると、そのグループに割り当てられている新しいプロセスに影響するだけでなく、そのグループのメンバーである現在実行中のプロセスは、変更の影響を直ちに受けます。つまり、 dirty_rate_limitが12288から3072に変更された場合、グループ内で現在実行されているプロセスは、グループ全体のダーティレートが1秒当たり12288キロバイトではなく、1秒あたり3072キロバイトになるように、FILLFACTOR = 10で句の結果INSERTコマンドは、1ページあたり10%まで行を梱包します。これは、これらの例の目的のために、ダーティな共有ブロックのより大きなサンプリングをもたらす。pg_stat_statementsモジュールは、SQLコマンドとコマンドの実行にかかった時間の量によって汚される共有バッファブロックの数を表示するために使用されます。これは、SQLコマンドの実際のキロバイト/秒の書き込み速度を計算するための情報を提供し、それをリソースグループに設定されたダーティレート制限と比較します。pg_stat_statementsモジュールを使用するには 、次の手順を実行します。手順2:データベースサーバーを再起動します。pg_stat_statements_reset()関数をクリアするために使用されるpg_stat_statements各実施例を明確にするための図。5.3.2 例 - 単一グループ内の単一プロセス次の一連のコマンドは、テーブル t1 作成を示しています 。現在のプロセスはリソースグループresgrp_bを使用するように設定されています。 pg_stat_statementsビューは、 pg_stat_statements_reset()関数を実行することでクリアされます。最後に、 INSERTコマンドは、1から10,000の一連の整数を生成してテーブルを作成し、約10,000のブロックをダーティにします。INSERTコマンドの結果を次に示します 。
5.4 システムカタログ5.4.1 edb_all_resource_groups
6.2 REFCURSORのサポート以前のリリースでは、Advanced Server は以下のlibpq関数 を REFCURSORs して REFCURSORs を サポートし ていました。これらの関数は廃止予定とみなされるべきです:SPL(またはPL / pgSQL)関数によって返され た REFCURSOR を取得するために、 PQexec() および PQgetvalue() を 使用することができ ます。 REFCURSOR カーソルの名前を示すヌル終了文字列の形式で返されます。カーソルの名前 を取得すると、 1つまたは複数の FETCH 文を 実行 して、カーソルで公開される値を取得 でき ます。CREATE OR REPLACE FUNCTION getEmployees(p_deptno NUMERIC) RETURN REFCURSOR AS
result REFCURSOR;
BEGIN
OPEN result FOR SELECT * FROM emp WHERE deptno = p_deptno;
RETURN result;
END;このファンクションは、単一のパラメータ p_deptno を必要と し、 OPEN 文に 示される SELECT 問合せの 結果セットを保持 する REFCURSOR を 戻します 。 OPEN 文は、クエリを実行し、カーソルに設定された結果を格納します。サーバーはそのカーソルの名前を作成し、その名前を変数( result という名前 )に 格納します 。この関数は、カーソルの名前を呼び出し元に返します。char *commandText = malloc(commandLength);
PGresult *result;
int row;
sprintf(commandText, "FETCH ALL FROM \"%s\"", cursorName);
result = PQexec(conn, commandText);
if (PQresultStatus(result) != PGRES_TUPLES_OK)
fail(conn, PQerrorMessage(conn));
printf("-- %s --\n", description);
for (row = 0; row < PQntuples(result); row++)
{
const char *delimiter = "\t";
int col;
for (col = 0; col < PQnfields(result); col++)
{
printf("%s%s", delimiter, PQgetvalue(result, row, col));
delimiter = ",";
}
printf("\n");
}
PQclear(result);
free(commandText);
}
static void
fail(PGconn *conn, const char *msg)
{
fprintf(stderr, "%s\n", msg);
if (conn != NULL)
PQfinish(conn);
exit(-1);
}PQexec() 関数は、Cプログラムにハンドルを結果セットを返します。結果セットにはちょうど1つの値が含まれます。その値は、 getEmployees() によって返されるカーソルの名前です 。カーソルの名前 を取得 すると、SQL FETCH ステートメントを使用してそのカーソル内の行を取り出す ことができ ます。関数 fetchAllRows() は FETCH 構築し fetchAllRows() ALL 文を実行し、その文を実行した後、 FETCH 結果セットを出力します ALL ステートメント。
6.3 配列バインディング
7 デバッガデバッガは pgAdmin 4 と統合され、 pgAdmin 4 から呼び出されます。 Linuxでは、 edb-as xx -server-pldebugger RPMパッケージ( xxはAdvanced Serverのバージョン番号)もインストールする必要があります。 pgAdmin 4の情報は次の場所から入手できます:
7.1 デバッガの設定デバッガを使用する前に、 shared_preload_libraries構成パラメータにリストされているライブラリに$libdir/plugin_debuggerを追加して、 postgresql.confファイル(Advanced Serverホームディレクトリのdataサブディレクトリにあります)を$libdir/plugin_debuggerします。
7.2 デバッガの起動スタンドアロンデバッグのためにデバッガにアクセスするには、pgAdmin 4を使用します。デバッガを開くには、pgAdmin 4 Browserパネルで、デバッグするストアドプロシージャまたはファンクションの名前を強調表示します 。次に、 ObjectメニューからDebuggingメニューまでナビゲートし、サブメニューからDebugを選択します。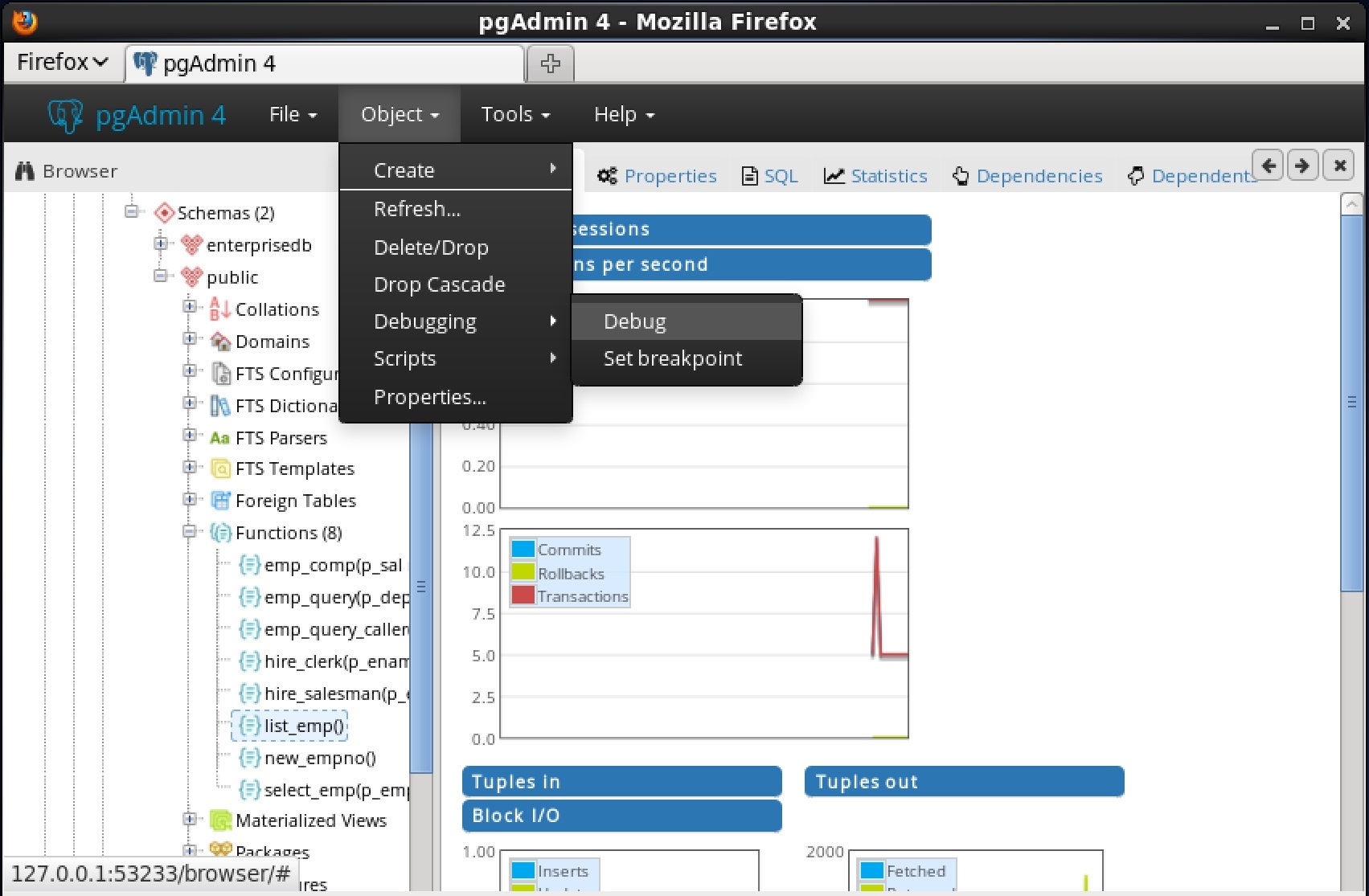
 スタンドアロンデバッグを使用してトリガをデバッグすることはできません。トリガーは、コンテキスト内のデバッグを使用してデバッグする必要があります。コンテキスト内デバッグ用のグローバルブレークポイントの設定については、 7.5.3 項を参照してください 。
スタンドアロンデバッグを使用してトリガをデバッグすることはできません。トリガーは、コンテキスト内のデバッグを使用してデバッグする必要があります。コンテキスト内デバッグ用のグローバルブレークポイントの設定については、 7.5.3 項を参照してください 。
7.3 デバッガウィンドウDebuggerウィンドウを使用して、スタンドアロン時にパラメータ値を渡して、パラメータを必要とするプログラムをデバッグすることができます。デバッガを起動すると、 Debuggerウィンドウが自動的に開き、プログラムが期待するINまたはIN OUTパラメータが表示されます。プログラムがINまたはIN OUTパラメーターを宣言していない場合、 Debuggerウィンドウはオープンしません。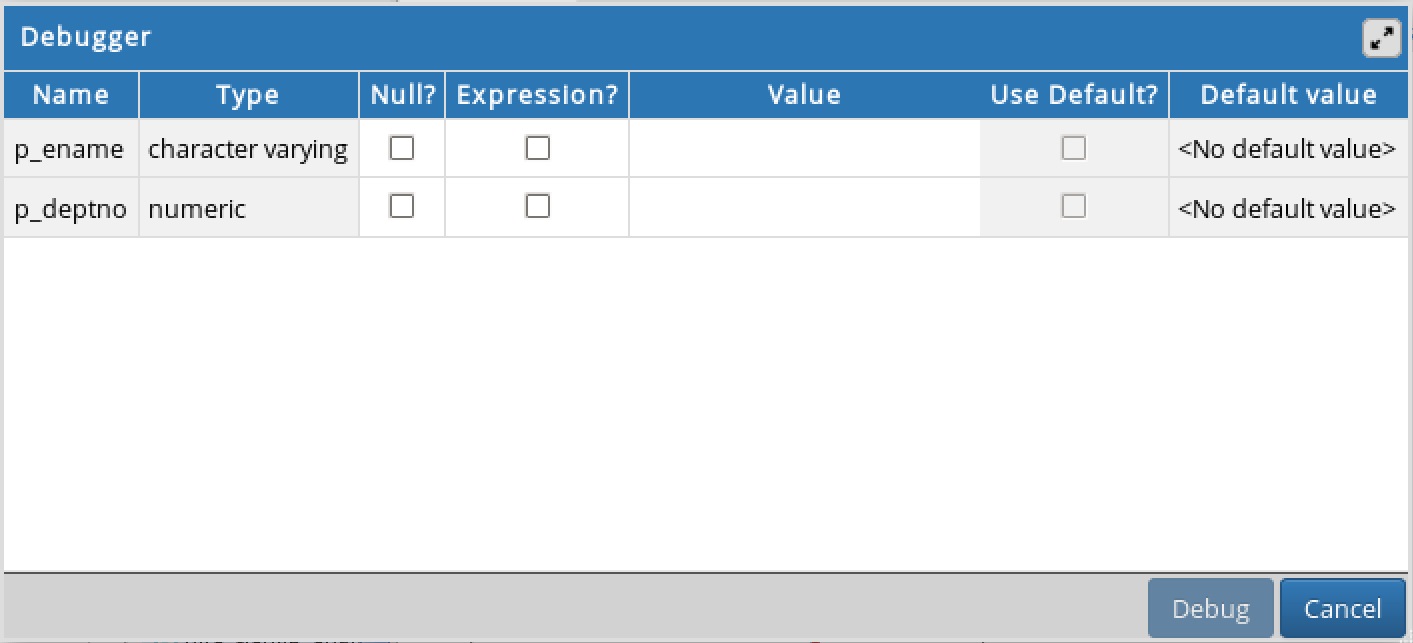
7.4 メインデバッガウィンドウ
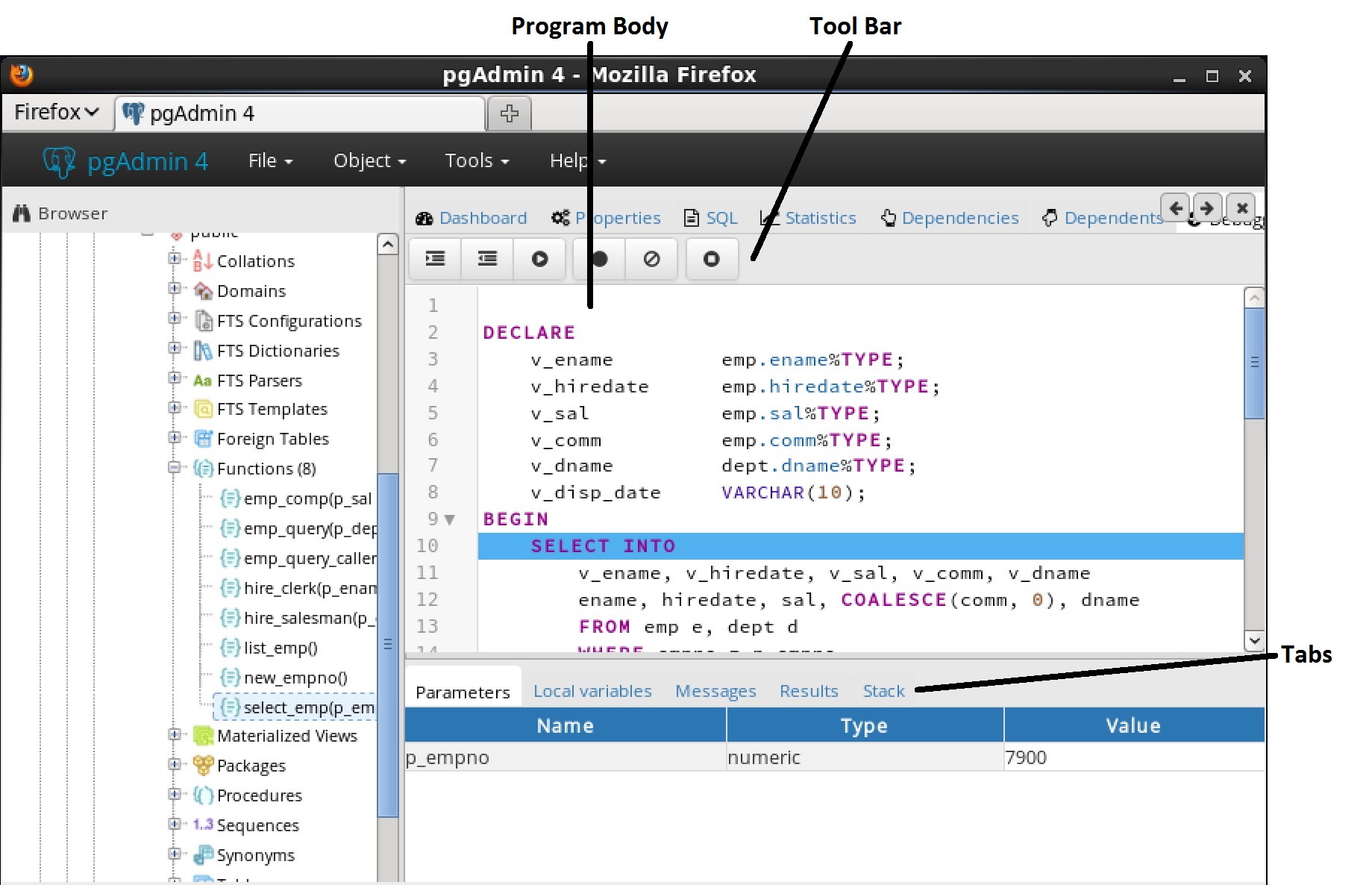 7.4.1 プログラム本体パネルProgram Bodyパネルがデバッグされているプログラムのソースコードが表示されます。
7.4.1 プログラム本体パネルProgram Bodyパネルがデバッグされているプログラムのソースコードが表示されます。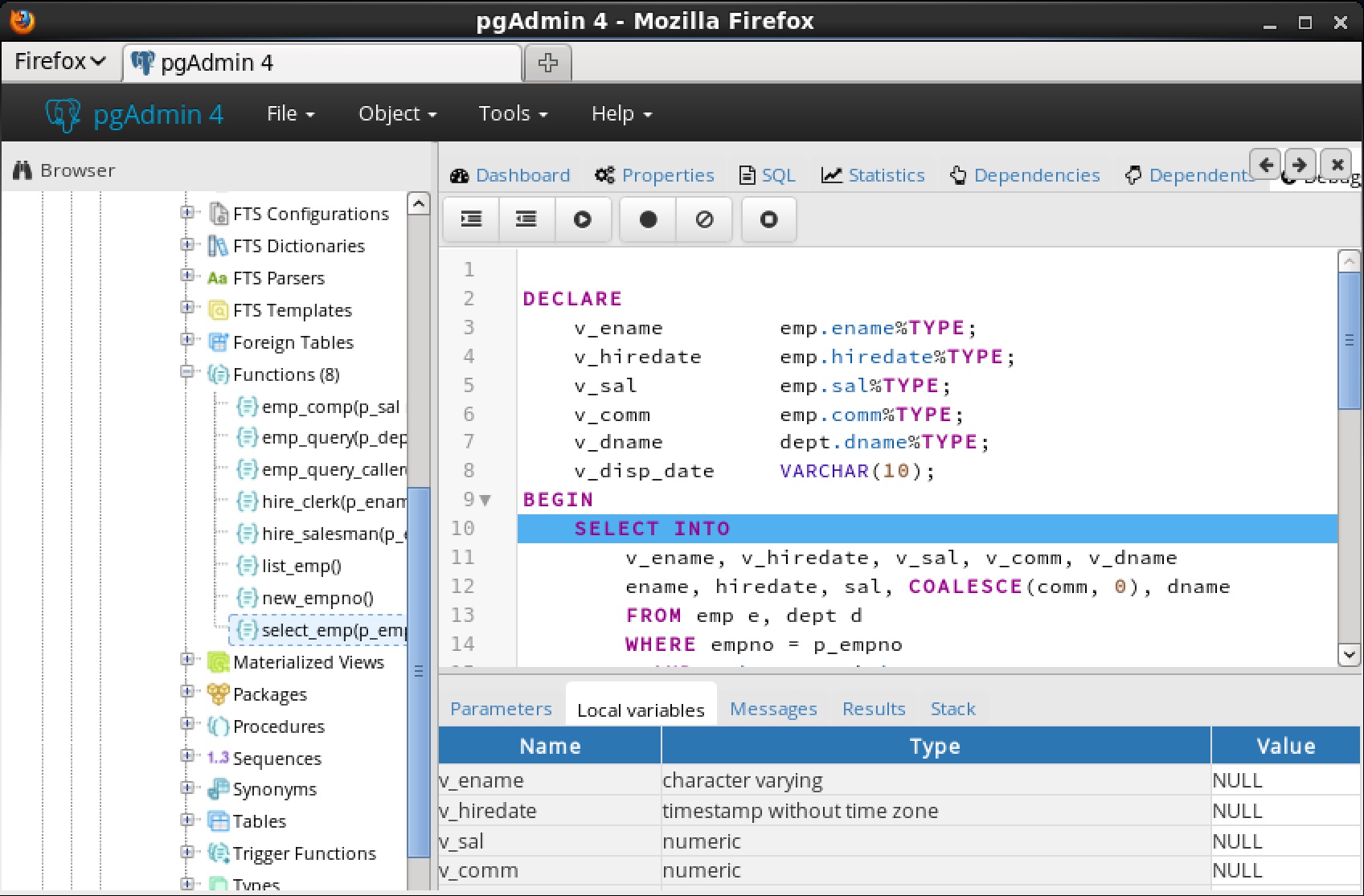 7.4.2 タブパネルは、
7.4.2 タブパネルは、
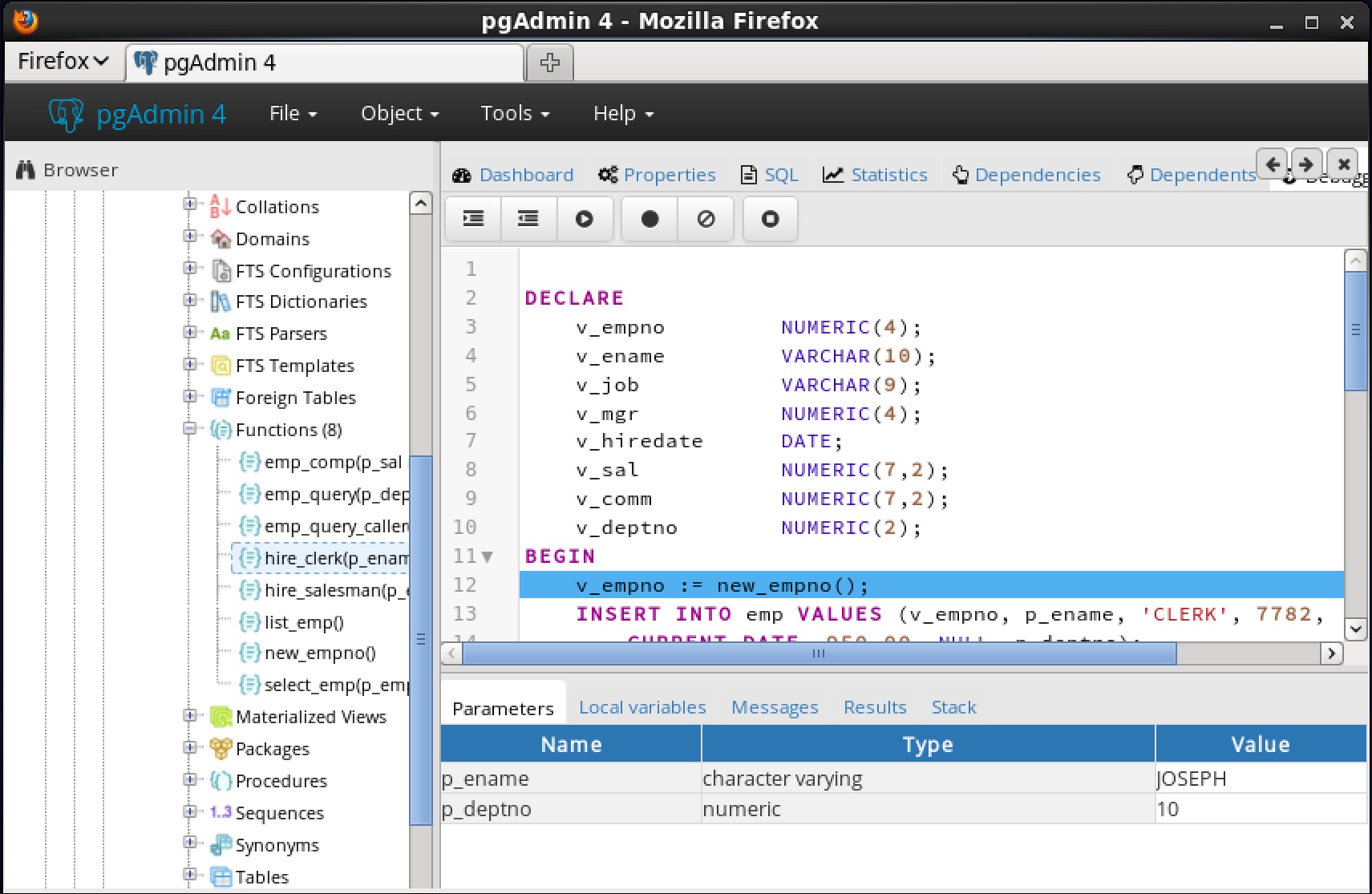
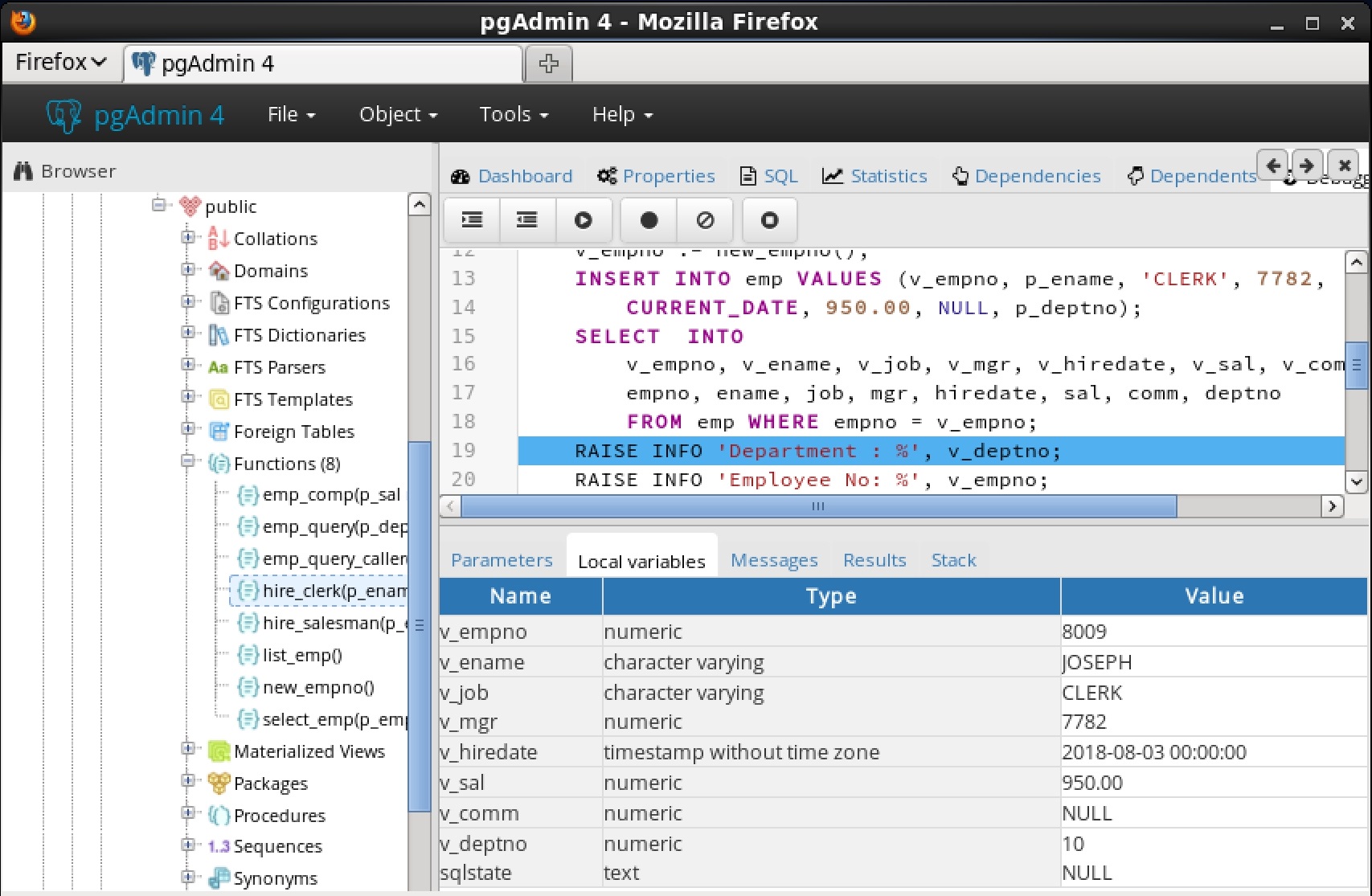
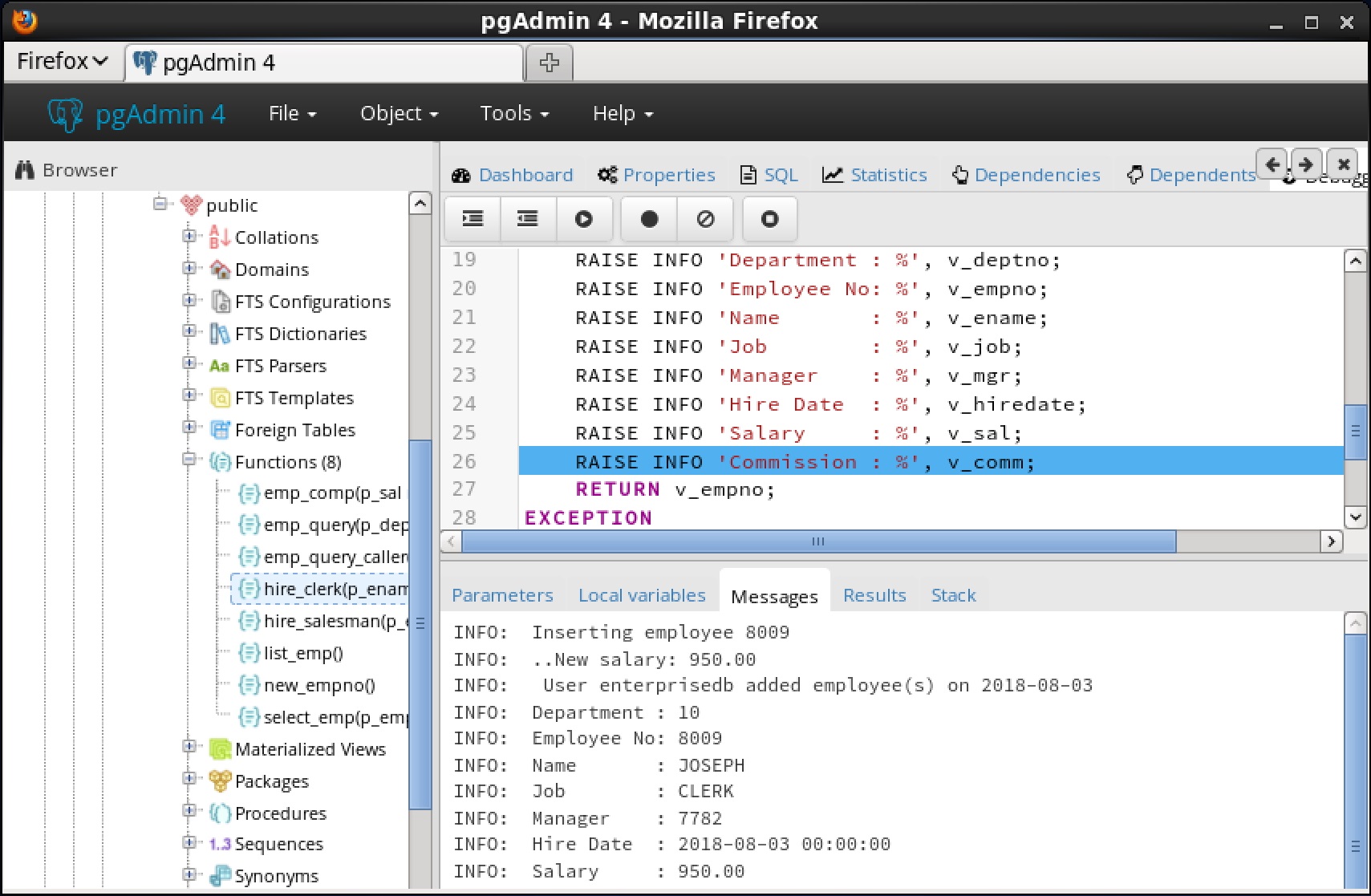
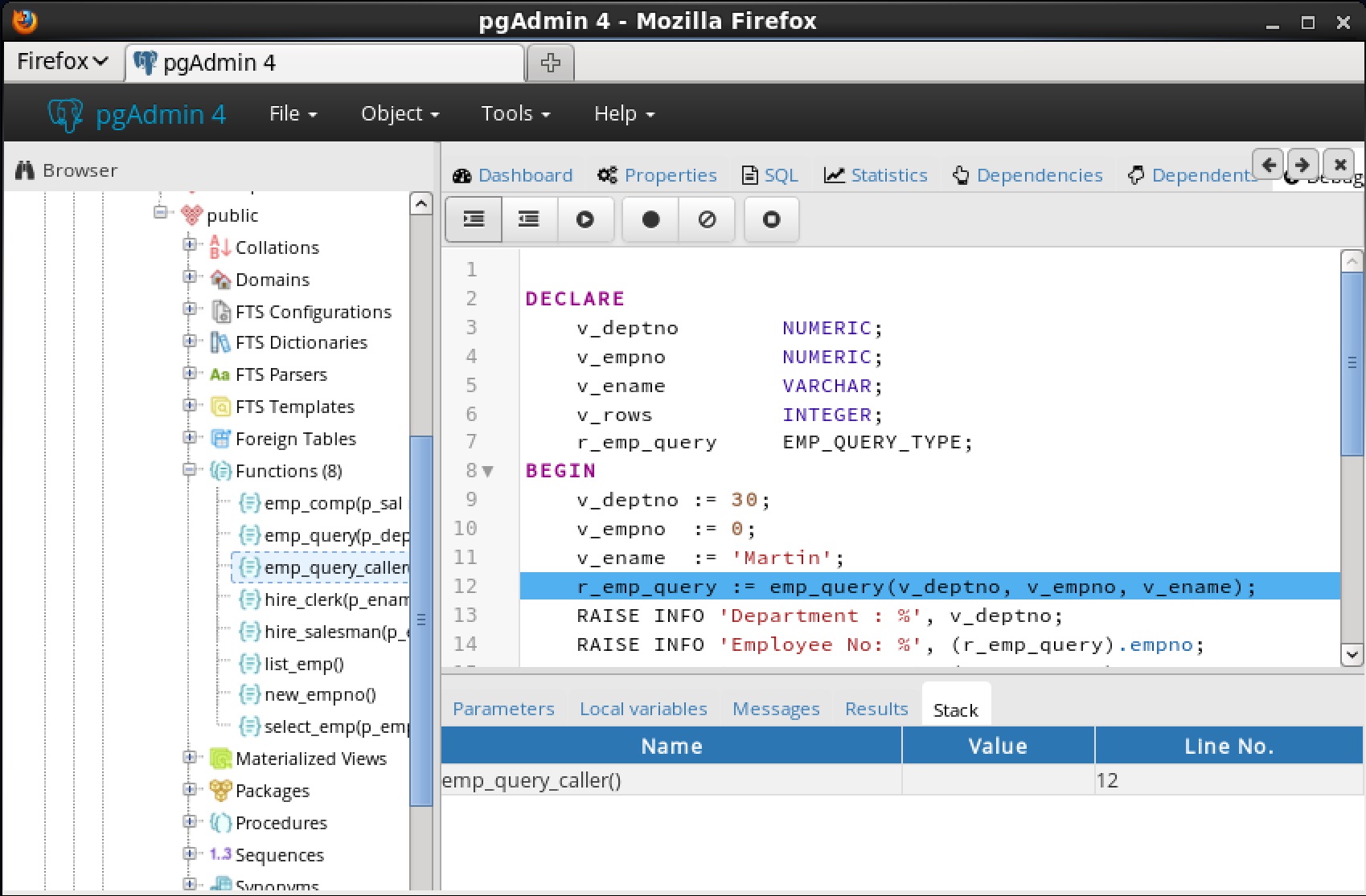
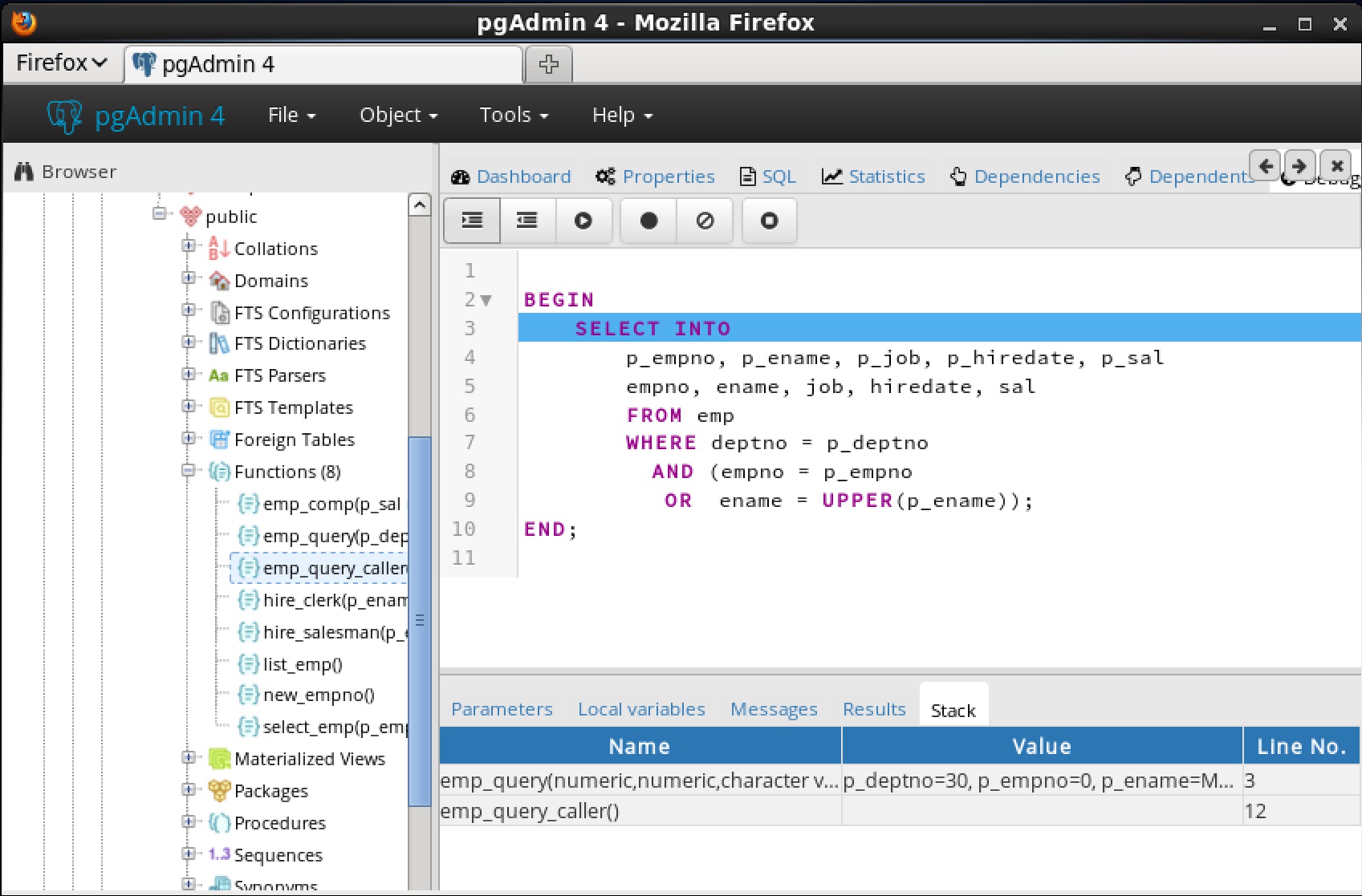
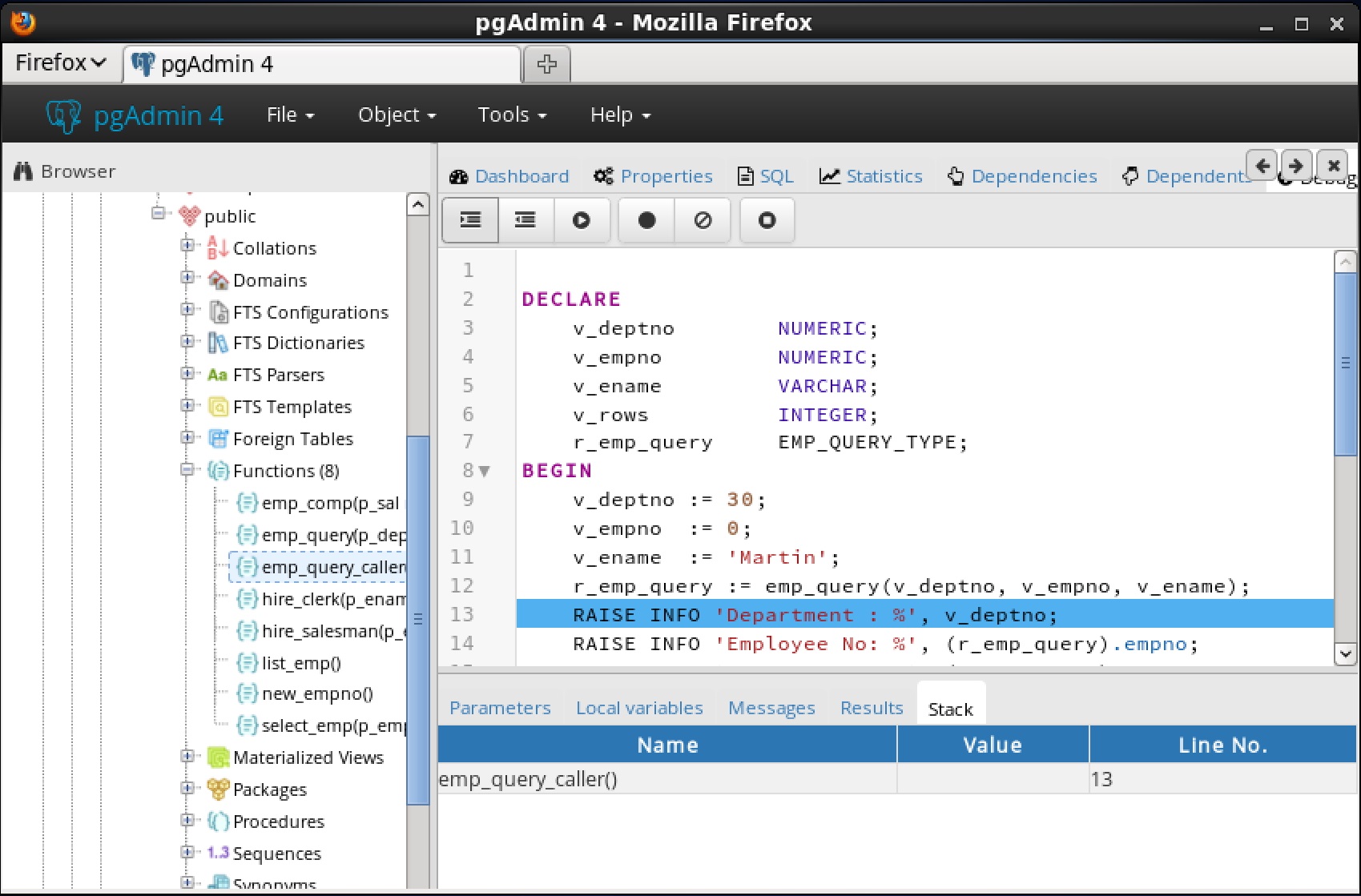
 7.4.3 スタックタブ[ Stack ]タブには、現在コールスタック上にあるプログラムのリスト(呼び出されたがまだ完了していないプログラム)のリストが表示されます。プログラムが呼び出されると、 Stackタブに表示されるリストの一番上にプログラムの名前が追加されます。 Wプログラムが終了鶏は、その名前がリストから削除されます。
7.4.3 スタックタブ[ Stack ]タブには、現在コールスタック上にあるプログラムのリスト(呼び出されたがまだ完了していないプログラム)のリストが表示されます。プログラムが呼び出されると、 Stackタブに表示されるリストの一番上にプログラムの名前が追加されます。 Wプログラムが終了鶏は、その名前がリストから削除されます。
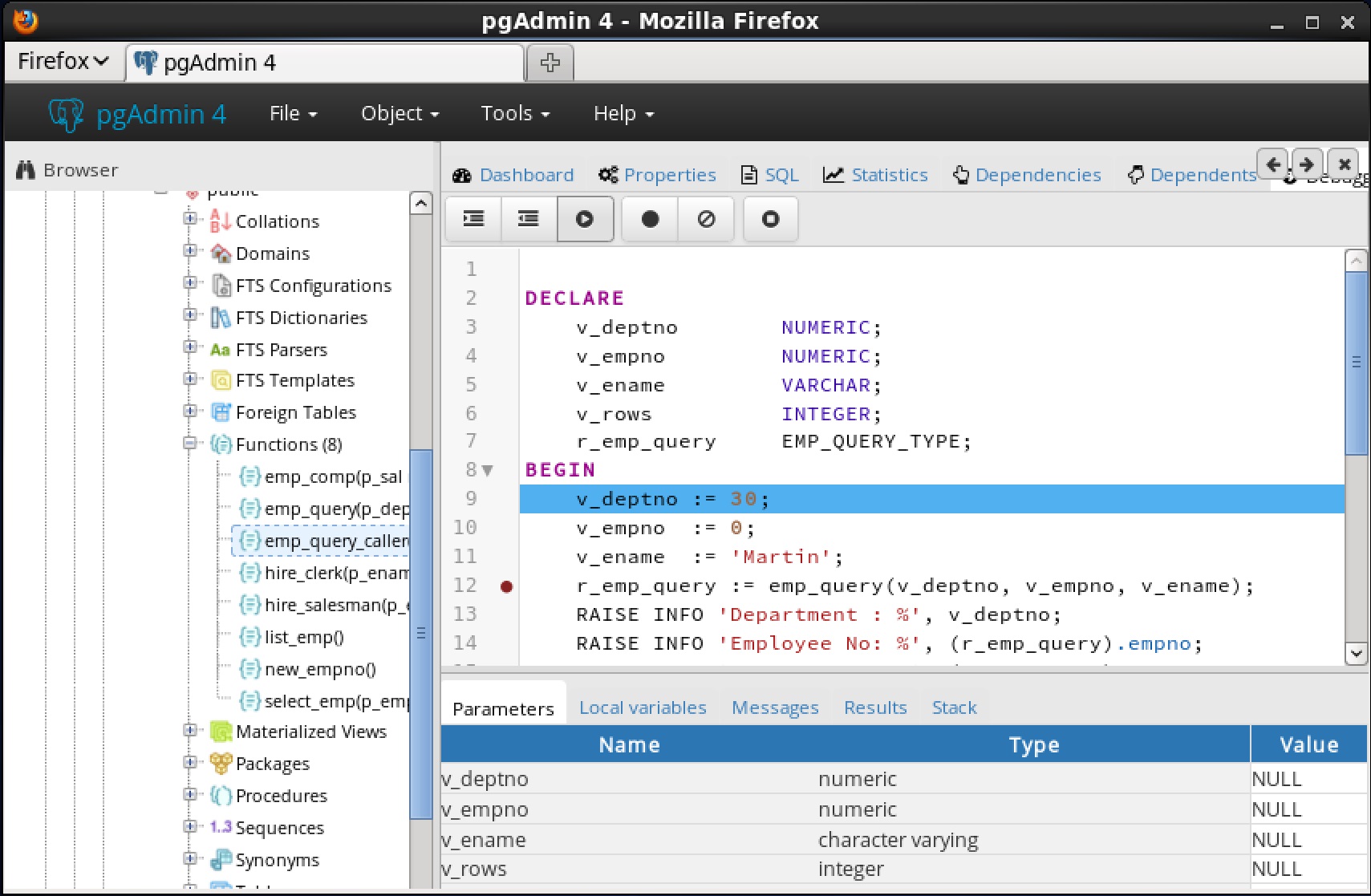
7.5 プログラムのデバッグ7.5.1 コードの実行
 ローカルブレークポイントを削除するには、 Program Bodyパネルの灰色で塗りつぶされた余白にあるブレークポイントの点をマウスで左クリックします 。点が消え、ブレークポイントが削除されたことを示します。[ all breakpoints Clear all ]アイコンをクリックすると、現在 Program Bodyフレームに表示されている Program からすべてのブレークポイントを削除できます。
ローカルブレークポイントを削除するには、 Program Bodyパネルの灰色で塗りつぶされた余白にあるブレークポイントの点をマウスで左クリックします 。点が消え、ブレークポイントが削除されたことを示します。[ all breakpoints Clear all ]アイコンをクリックすると、現在 Program Bodyフレームに表示されている Program からすべてのブレークポイントを削除できます。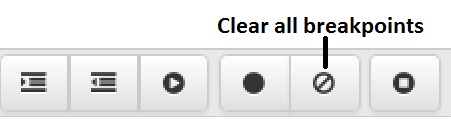 注:上記のいずれかの操作を実行すると、 Program Bodyパネルに現在表示されているProgram Body内のブレークポイントだけが削除されます。現在Program Bodyパネルに表示されているプログラムを呼び出すプログラム内の呼び出されたサブプログラムまたはブレークポイントのブレークポイントは削除されません。コンテキスト内デバッグのグローバルブレークポイントを設定するには、 Browserパネルでブレークポイントを設定するストアドプロシージャ、関数、またはトリガを強調表示します 。 [ Object ]メニューから[ Debugging ]、[ Breakpoint Set ]の順に選択します。
注:上記のいずれかの操作を実行すると、 Program Bodyパネルに現在表示されているProgram Body内のブレークポイントだけが削除されます。現在Program Bodyパネルに表示されているプログラムを呼び出すプログラム内の呼び出されたサブプログラムまたはブレークポイントのブレークポイントは削除されません。コンテキスト内デバッグのグローバルブレークポイントを設定するには、 Browserパネルでブレークポイントを設定するストアドプロシージャ、関数、またはトリガを強調表示します 。 [ Object ]メニューから[ Debugging ]、[ Breakpoint Set ]の順に選択します。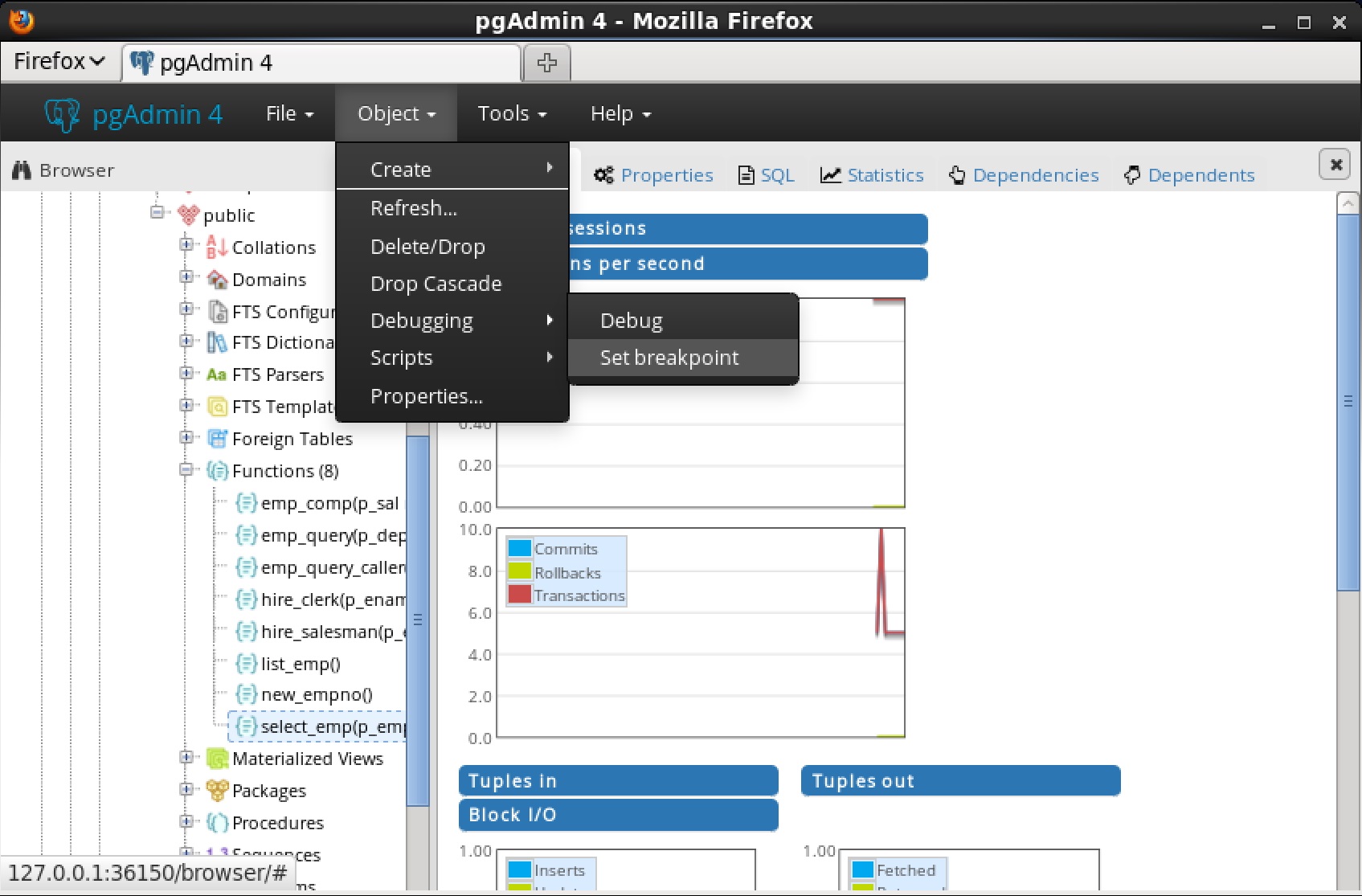 または、グローバルブレークポイントを設定するストアドプロシージャ、関数、またはトリガの名前を右クリックし 、コンテキストメニューからDebugging を選択し 、次にSet BreakpointをSet Breakpointすることもできます。
または、グローバルブレークポイントを設定するストアドプロシージャ、関数、またはトリガの名前を右クリックし 、コンテキストメニューからDebugging を選択し 、次にSet BreakpointをSet Breakpointすることもできます。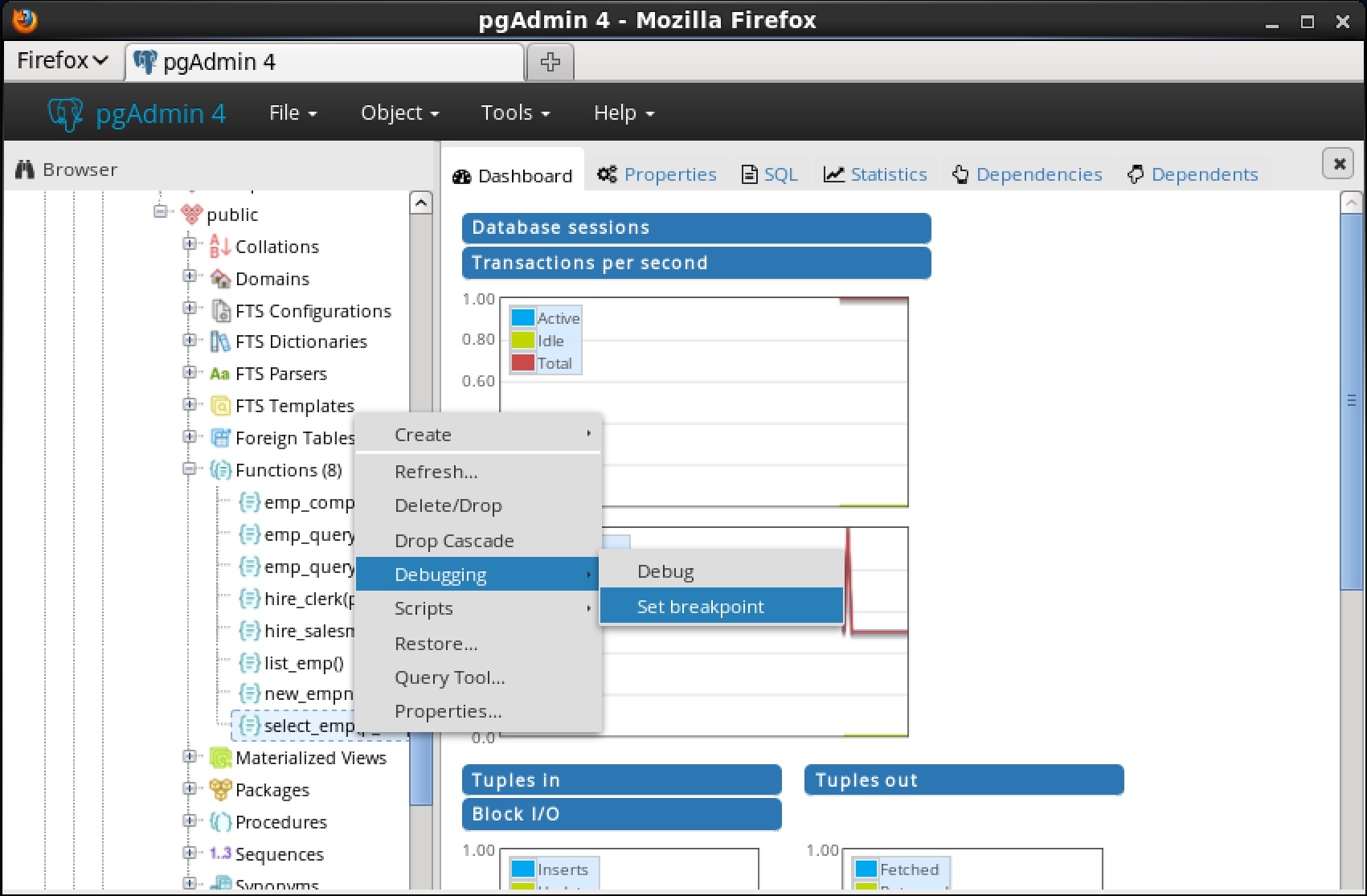 パッケージ内にグローバルブレークポイントを設定するには、デバッグするパッケージのパッケージノードの下にある特定のプロシージャまたは関数を強調表示し、ストアドプロシージャおよび関数と同じ指示に従います。
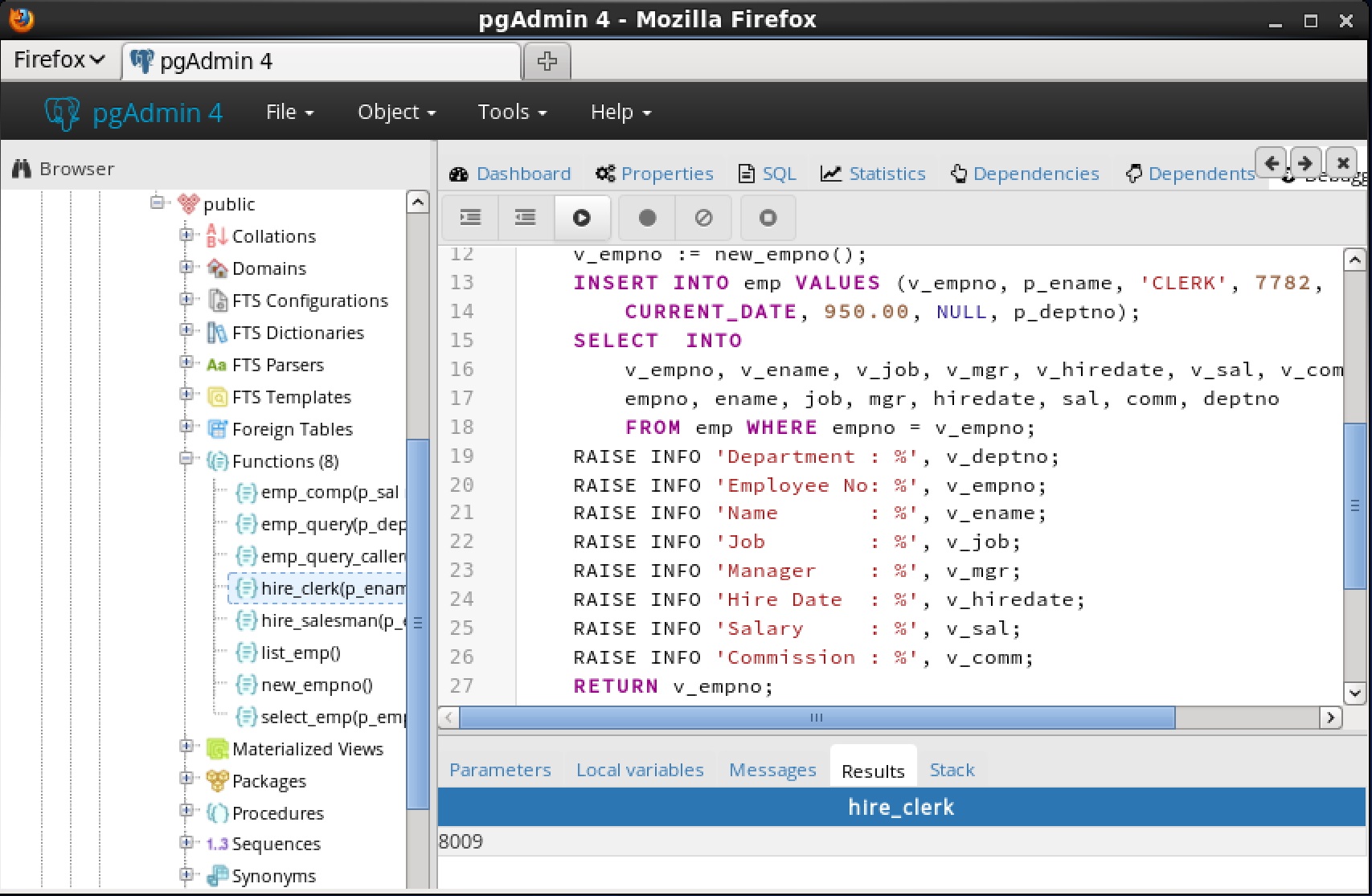
パッケージ内にグローバルブレークポイントを設定するには、デバッグするパッケージのパッケージノードの下にある特定のプロシージャまたは関数を強調表示し、ストアドプロシージャおよび関数と同じ指示に従います。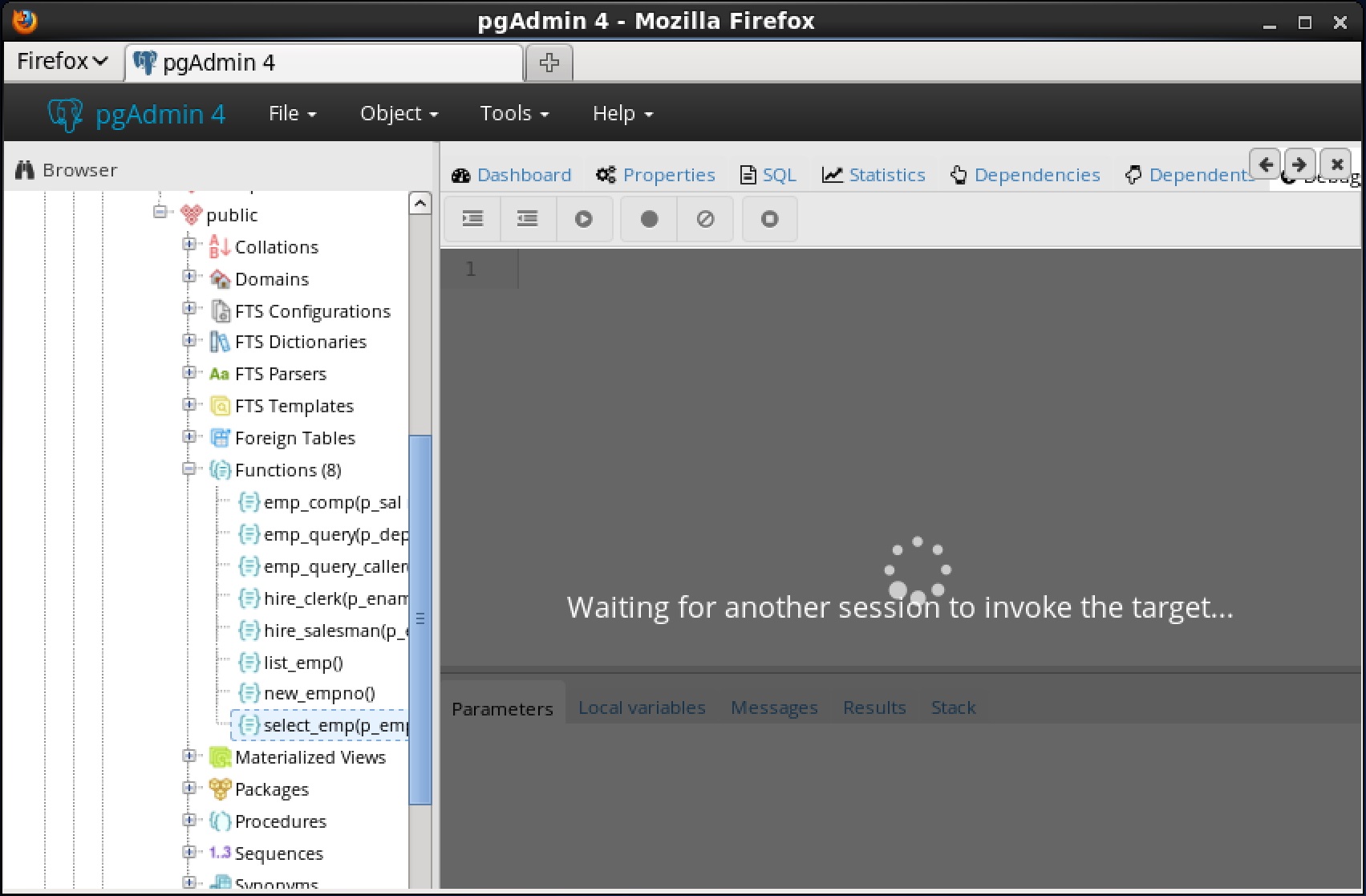 select_empデバッガでプログラムをステップ実行するまでの機能は完了しません。
select_empデバッガでプログラムをステップ実行するまでの機能は完了しません。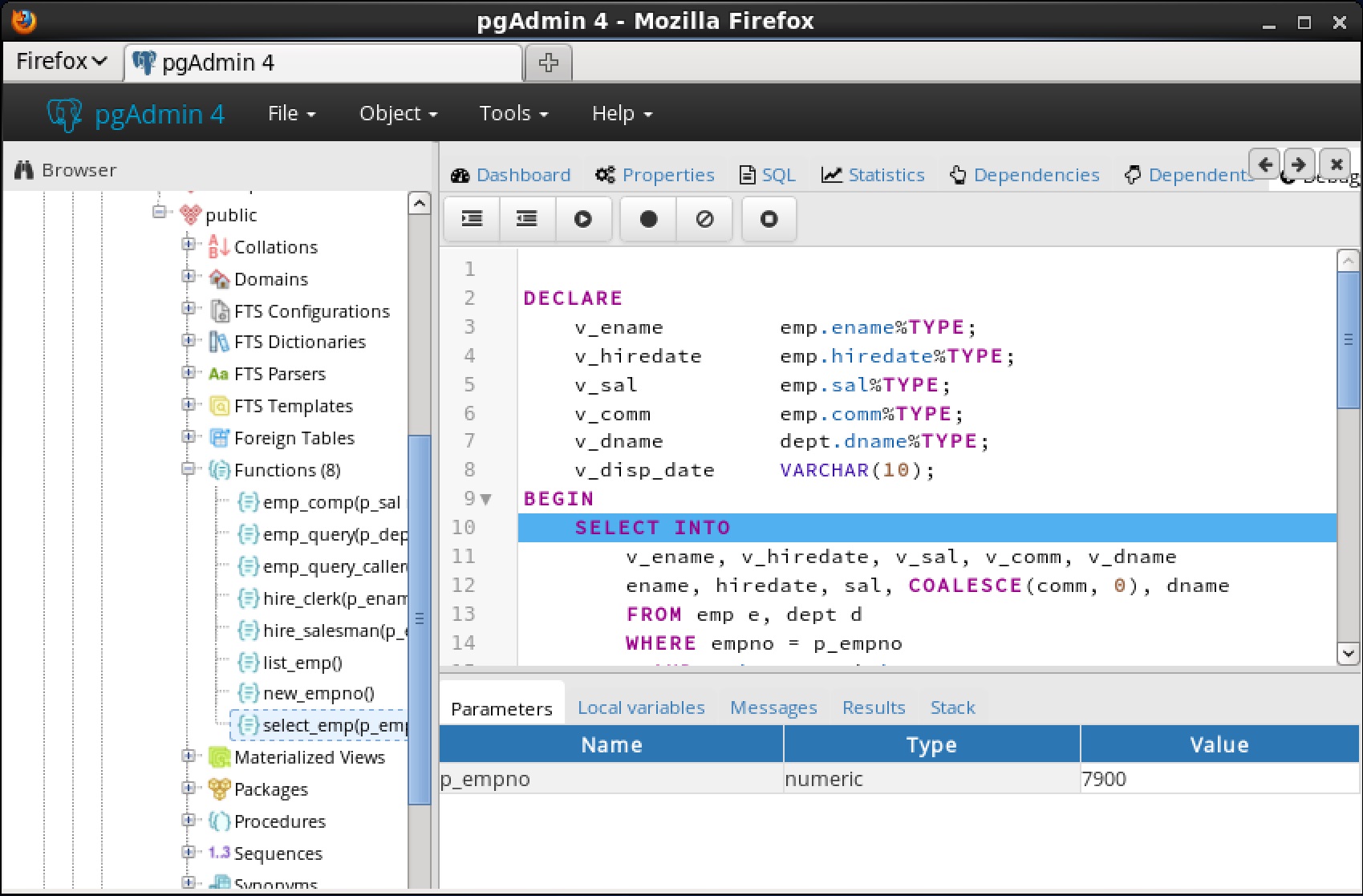 ステップイン、ステップオーバー、および続行、またはローカルブレークポイントの設定など、前述の操作のいずれかを使用してプログラムをデバッグできるようになりました。プログラムの実行をステップ実行すると、呼び出し元のアプリケーション(PSQL)が制御を取り戻し、 select_emp関数の実行が完了し、その出力が表示されます。この時点で、セクション 7.5.4に 示すようにデバッガセッションを終了することができます 。デバッガセッションを終了しないと、プログラムを呼び出す次のアプリケーションにグローバルブレークポイントが発生し、デバッグサイクルが再び開始されます。7.5.4 デバッガの終了
ステップイン、ステップオーバー、および続行、またはローカルブレークポイントの設定など、前述の操作のいずれかを使用してプログラムをデバッグできるようになりました。プログラムの実行をステップ実行すると、呼び出し元のアプリケーション(PSQL)が制御を取り戻し、 select_emp関数の実行が完了し、その出力が表示されます。この時点で、セクション 7.5.4に 示すようにデバッガセッションを終了することができます 。デバッガセッションを終了しないと、プログラムを呼び出す次のアプリケーションにグローバルブレークポイントが発生し、デバッグサイクルが再び開始されます。7.5.4 デバッガの終了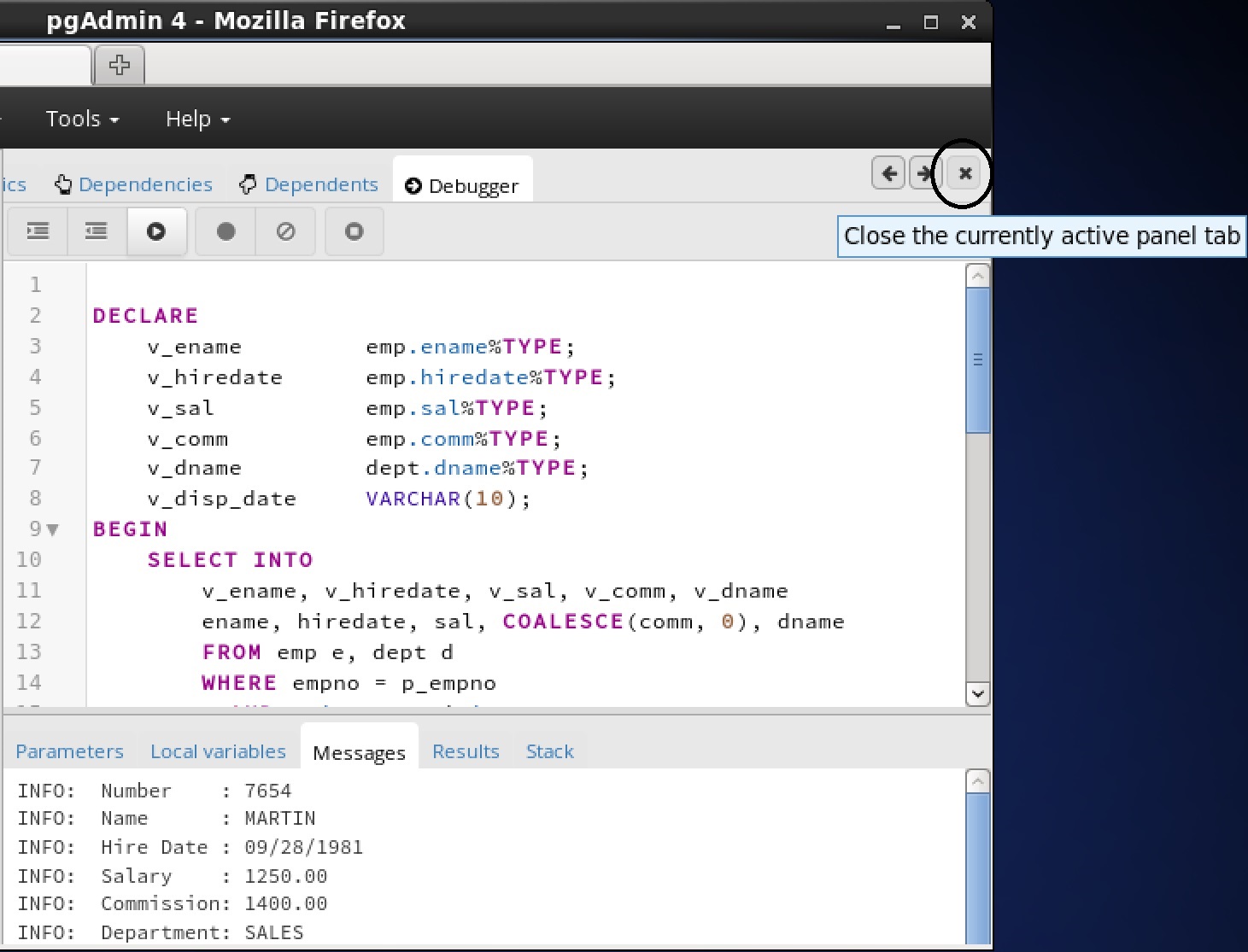
8.1 ダイナネAdvanced Serverは、インストールされているホストマシンでシステムリソースを最適に使用できるように、データベースサーバーの動的調整をサポートしています。この機能を制御する2つのパラメータは、 postgresql.confファイルにあります。これらのパラメータは次のとおりです。8.1.1 edb_dynatuneedb_dynatuneは、ホスト・マシンの使用可能リソースの合計とホスト・マシンの使用目的に基づいて、データベース・サーバーが使用するホスト・システムのリソースの量を決定します。Advanced Serverを最初にインストールすると、 edb_dynatuneパラメータは、インストールされたホストマシン(開発マシン、混在マシン、専用サーバー)の選択された使用状況に従って設定されます。ほとんどの場合、パフォーマンスを向上させるためにデータベース管理者がpostgresql.confファイルのさまざまな設定パラメータを調整する必要はありません。postgresql.confファイルを編集することにより、Advanced Serverの初期インストール後にedb_dynatuneパラメータの値を変更できます。新しい設定を有効にするには、postmasterを再起動する必要があります。edb_dynatuneパラメータは、包括的、0と100の間の任意の整数値に設定することができます。値0を指定すると、動的チューニング機能がオフになり、データベースサーバのリソース使用量はpostgresql.confファイルの他の設定パラメータの制御下に完全にpostgresql.confます。非ゼロの値が小さければ(例えば、1〜33)、ホスト・マシンのリソースの最小量がデータベース・サーバーに割り当てられます。この設定は、他の多くのアプリケーションが使用されている開発マシンで使用されます。edb_dynatune 値が選択されると、 postgresql.confファイル内の他の設定パラメータを調整することによって、データベースサーバのパフォーマンスをさらに微調整することができます。調整された設定は、 edb_dynatuneによって選択された対応する値を上書きします。パラメーターの値を変更するには、構成パラメーターをコメント解除し、目的の値を指定して、データベース・サーバーを再始動します。8.1.2 edb_dynatune_profileedb_dynatune_profileパラメータは、データベース・サーバー上で予想されるワークロードのプロファイルに基づいて調整局面を制御するために使用されます。このパラメータは、データベースサーバの起動時に有効になります。
8.2 EDB待機状態EDBの状態を待つ貢献モジュールは、2つの主要なコンポーネントが含まれています。この情報は 、 postgresql.confファイルに追加されるedb_wait_states.directoryパラメータで指定された、ユーザが設定可能なパスとディレクトリフォルダ内の一連のファイルに保存されます。指定されたパスは完全パスで、相対パスではありません。
EDB Clone Schemaは、Advanced Serverの拡張モジュールで、スキーマとそのデータベースオブジェクトをローカルデータベースまたはリモートデータベース(ソースデータベース)から受信側データベース(ターゲットデータベース)にコピーすることができます。
9.1 セットアッププロセス9.1.1 拡張機能とPL / Perlのインストール手順1:次の拡張機能をデータベースにインストールする必要があります。
9.2 EDBクローンスキーマ関数
10 PL / JavaPL / Javaパッケージは、JDBCインタフェースを介してJavaストアド・プロシージャ、トリガ、およびファンクションへのアクセスを提供します。特に指定のないかぎり、次のセクションで説明するコマンドとパスは、 edb-as xx -pljava RPMパッケージ( xxはAdvanced Serverのバージョン番号)でインストールを実行したことを前提としています 。
pljava.classpath = ' path_to_pljava.jar 'pljava.libjvm_location = ' path_to_libjvm.so '手順2:データベースサーバーを再起動します。ステップ3: CREATE EXTENSIONコマンドを使用してPL / Javaをインストールできます。 PL / Java拡張機能をインストールするには、psqlまたはpgAdminクライアントを使用してPL / Javaをインストールするデータベースにログインし、次のコマンドを実行します。ステップ4: PL / Javaがインストールされていることを確認するには、次のコマンドを実行します。edb-psqlクライアントがあることを示す2つの行を表示javaとjavau (Javaの信頼できない)は、データベースにインストールされています。
ステップ1: postgresql.confファイルを編集し、次の設定を追加(または変更)します。pljava.classpath = ' POSTGRES_INSTALL_HOME \lib\pljava.jar'pljava.libjvm_location = ' path_to_libjvm.so 'どこ POSTGRES_INSTALL_HOME Advanced Serverのインストールの場所を指定します。たとえば、次の設定はデフォルトインストールの設定です。手順2:データベースサーバーを再起動します。手順3:サーバーで使用されるPATH設定を変更し、次の2つのエントリを追加します。ステップ4: Postgres CREATE EXTENSIONコマンドを使用してPL / Javaをインストールします。インストール・スクリプトを実行するには、psqlまたはpgAdminクライアントを使用して、PL / Javaをインストールするデータベースに接続し、次のコマンドを実行します。ステップ5: PL / Javaがインストールされていることを確認するには、次のコマンドを実行します。
10.3 PL / Javaの使用PL / Javaプログラムを作成するには、少なくとも1つの静的メソッドを含むJavaクラスを作成してから、そのクラスを .classまたは.jarファイルにコンパイルする必要があります。次に、 CREATE FUNCTIONコマンドを使用してSQL内のJava関数を宣言します。 CREATE FUNCTIONコマンドは、関数にSQL名を与え、コンパイルされたクラス(およびメソッド名)をその関数名に関連付けます。手順1:次のコードサンプルをHelloWorld.javaという名前のファイルに保存します。ステップ2:ファイルをコンパイルします。手順3: helloworld.jarというアーカイブファイル(JARファイル)を作成します。ステップ4: edb-psqlクライアントを開き、次のコマンドでjarファイルをインストールします。SELECT sqlj.install_jar('file:/// file_path /helloworld.jar', 'helloworld', true);ステップ5:クラスパスを次のように設定します。sqlj.classpath_entryテーブルは現在のエントリが含まれますhelloworldクラスファイルを。ステップ6: Javaを使用してjarファイルで宣言された静的関数を呼び出す関数を作成します。ステップ7:関数を実行する:
Advanced Serverには、拡張されたSQL機能とその他の柔軟性と利便性を提供するさまざまな機能が含まれています 。この章では、これらの追加について説明します。
11.1 コメントPostgreSQLの COMMENTコマンドでサポートされているオブジェクトにコメントするだけでなく、Advanced Serverは追加のオブジェクトタイプに関するコメントをサポートしています。サポートされている完全な構文は次のとおりです。COMMENT ON
{
AGGREGATE aggregate _ name ( aggregate _ signature ) |
CAST ( source _ type AS target _ type ) |
COLLATION object _ name |
COLUMN relation _ name . column _ name |
CONSTRAINT constraint _ name ON table _ name |
CONSTRAINT constraint _ name ON DOMAIN domain _ name |
CONVERSION object _ name |
DATABASE object _ name |
DOMAIN object _ name |
EXTENSION object _ name |
EVENT TRIGGER object _ name |
FOREIGN DATA WRAPPER object _ name |
FOREIGN TABLE object _ name |
FUNCTION func _ name ([[ argmode ] [ argname ] argtype [, ...]])|
INDEX object _ name |
LARGE OBJECT large _ object _ oid |
MATERIALIZED VIEW object _ name |
OPERATOR operator _ name (left_type, right_type) |
OPERATOR CLASS object _ name USING index _ method |
OPERATOR FAMILY object _ name USING index _ method |
PACKAGE object _ name
POLICY policy _ name ON table _ name |
[ PROCEDURAL ] LANGUAGE object _ name |
PROCEDURE proc _ name [([[ argmode ] [ argname ] argtype [, ...]])]
PUBLIC SYNONYM object _ name
ROLE object _ name |
RULE rule _ name ON table _ name |
SCHEMA object _ name |
SEQUENCE object _ name |
SERVER object _ name |
TABLE object _ name |
TABLESPACE object _ name |
TEXT SEARCH CONFIGURATION object _ name |
TEXT SEARCH DICTIONARY object _ name |
TEXT SEARCH PARSER object _ name |
TEXT SEARCH TEMPLATE object _ name |
TRANSFORM FOR type _ name LANGUAGE lang _ name |
TRIGGER trigger _ name ON table _ name |
TYPE object _ name |
VIEW object _ name
} IS 'text'* |
[ argmode ] [ argname ] argtype [ , ... ] |
[ [ argmode ] [ argname ] argtype [ , ... ] ]
ORDER BY [ argmode ] [ argname ] argtype [ , ... ]集約についてのコメントを作成するには、 AGGREGATE句を含めます 。 aggregate _ nameはaggregate name指定し、 aggregate _ signatureは関連する署名を次のいずれかの形式で指定します。* |
[ argmode ] [ argname ] argtype [ , ... ] |
[ [ argmode ] [ argname ] argtype [ , ... ] ]
ORDER BY [ argmode ] [ argname ] argtype [ , ... ]どこ argmode is the mode of a function, procedure, or aggregate argument; argmode may be IN , OUT , INOUT , or VARIADIC , or VARIADIC . If omitted, the default is IN .argname is the name of an aggregate argument.argtype is the data type of an aggregate argument.キャストに関するコメントを作成するには、 CAST句を含めます 。 When creating a comment about a cast, source_type When creating a comment about a cast, specifies the source data type of the cast, and specifies the target data type of the cast. target_type specifies the source data type of the cast, and specifies the target data type of the cast.列に関するコメントを作成するには、 COLUMN句を含めます。 column_name specifies name of the column to which the comment applies. relation_name is the table, view, composite type, or foreign table in which a column resides.clause to add a comment about a constraint. When creating a comment about a constraint, Include the CONSTRAINT clause to add a comment about a constraint. When creating a comment about a constraint, Include the clause to add a comment about a constraint. When creating a comment about a constraint, constraint_name specifies the name of the constraint; table_name or domain_name specifies the name of the table or domain on which the constraint is defined. domain_name specifies the name of the table or domain on which the constraint is defined.clause to add a comment about a function. Include the FUNCTION clause to add a comment about a function. Include the clause to add a comment about a function. func _ nameは、関数の名前を指定します。 argmode specifies the mode of the function; argmode may be IN , OUT , INOUT , or VARIADIC , or VARIADIC . If omitted, the default is IN . argname specifies the name of a function, procedure, or aggregate argument. argtype specifies the data type of a function, procedure, or aggregate argument.large_object_oid is the system-assigned OID of the large object about which you are commenting.オペレータに関するコメントを追加するには、 OPERATOR句を含めます 。 operator _ nameは、コメントしている演算子の名前(スキーマ修飾名でも可)を指定します。 left _ typeおよびright _ type are the (optionally schema-qualified) data type(s) of the operator's arguments.演算子クラスについてのコメントを追加するには、 OPERATOR CLASS句を含めます 。 object _ nameは、コメントしている演算子の名前(スキーマ修飾名でも可)を指定します。 index_method specifies the associated index method of the operator class.OPERATOR FAMILYについてのコメントを追加するには、 OPERATOR FAMILY句を含めます 。 object _ nameは、コメントしている演算子ファミリの名前(スキーマ修飾名でも可)を指定します。 index_method specifies the associated index method of the operator family.clause to add a comment about a procedure. Include the PROCEDURE clause to add a comment about a procedure. Include the clause to add a comment about a procedure. proc _ name specifies the name of the procedure. argmode specifies the mode of the procedure; argmode may be IN , OUT , INOUT , or VARIADIC , or VARIADIC . If omitted, the default is IN . argname specifies the name of a function, procedure, or aggregate argument. argtype specifies the data type of a function, procedure, or aggregate argument.Include the RULE clause to specify a COMMENT oルールNAが. rule _ name specifies the name of the rule, and name specifies the name of the table on which the rule is defined. table _ name specifies the name of the table on which the rule is defined.Include the TRANSFORM Include the FOR clause to specify a on a TRANSFORM COMMENT clause to specify a . type _ name specifies the name of the data type of the transform and name specifies the name of the language of the transform. lang _ name specifies the name of the language of the transform.TRIGGER clause to specify a Include the COMMENT o NAトリガclause to specify a . trigger _ name specifies the name of the trigger, and name specifies the name of the table on which the trigger is defined. table _ name specifies the name of the table on which the trigger is defined.The following example adds a comment to a table named new_emp The following example adds a comment to a table named :COMMENT command, please see the PostgreSQL core documentation at: For more information about using the command, please see the PostgreSQL core documentation at:
11.2 機能バージョン()の出力version()関数のテキスト文字列出力は、製品の名前、バージョン、およびそれがインストールされているホストシステムを表示します。Advanced Serverの場合、 version()出力形式は、PostgreSQLコミュニティバージョンと似た形式ですversion() Advanced Serverバージョン10以前のように、最初のテキストワードはPostgreSQLでEnterpriseDBではなく)。
11.3 SQL ServerのdboスキーマAdvanced Server 11より前は、 dbo という名前のシステムカタログが利用可能でした。 dboシステムカタログには、Microsoft®SQLServer®と類似しているデータベースオブジェクトのビューが含まれていました。
12 システムカタログテーブル
12.1 edb_diredb _ dir表は、で作成したディレクトリを指し、各エイリアスの1つの行が含まCREATE DIRECTORYコマンド。ディレクトリは、ユーザーがホストファイルシステムに限定してアクセスできるようにするパス名のエイリアスです。ディレクトリを使用して、ファイルシステム内の特定のディレクトリツリーにユーザを囲むことができます。例えば、 UTL _ FILEパッケージには、ホストファイルシステム内のファイルおよびディレクトリを読み書きするためのユーザを許可する機能を提供していますが、唯一のデータベース管理者が経由へのアクセスを許可されたパスにアクセスすることができますCREATE DIRECTORYコマンドを。
edb_all_resource_groups表は、で作成された各リソースグループの1つの行を含んCREATE RESOURCE GROUPコマンドと各リソースグループ内のアクティブなプロセスの数を表示します。
12.3 edb_password_historyedb _ password_history表は、各パスワード変更のために1行が含まれます。この表は、クラスタ内のすべてのデータベースで共有されます。
12.4 edb_policyedb _ policyテーブルは、ポリシーごとに1つの行が含ま。
12.5 edb_profileedb _ profileの表は、使用可能なプロファイルに関する情報を格納します。 edb _ profilesは、クラスタ内のすべてのデータベースで共有されます。
12.6 edb_redaction_columnカタログ edb_redaction_columnは、表の列にアタッチされたデータ変更ポリシーの情報が格納されます。
12.7 edb_redaction_policyカタログ edb_redaction_policyは、表の編集ポリシーの情報が保管されます。
12.8 edb_resource_groupedb_resource_group表は、で作成された各リソースグループに対して1つの行含まれているCREATE RESOURCE GROUPコマンド。
12.9 edb_variableedb _ variableテーブルには、各パッケージレベルの変数(パッケージ内で宣言された各変数)のための1つの行が含ま。
12.10 pg_synonympg _ synonymテーブルには、各同義語で作成するための1つの行含まCREATE SYNONYMコマンドまたはCREATE PUBLIC SYNONYMコマンド。
product _ component _ versionテーブルは、特徴の互換性についての情報を含みます。アプリケーションはインストール時または実行時にこのテーブルを照会して、このデプロイメントでアプリケーションで使用される機能が使用可能であることを確認できます。
13 高度なサーバーキーワードキーワードは、Advanced Serverパーサによって特別な意味または関連があると認識される単語です。 pg_get_keywords()関数を使用すると、Advanced Serverのキーワードの最新リストを取得できます 。pg_get_keywordsは、Advanced Serverによって認識されるキーワードを含むテーブルを返します。
目次