オラクルの データベース互換性とは、アプリケーションが
Oracle環境だけでなく、
EDB Postgres Advanced Server(Advanced Server)環境で動作し、アプリケーションコードをほとんど変更しないか、またはまったく変更しないことを意味します。
Advanced Server でOracleデータベースと互換性のある
アプリケーションを開発するには、アプリケーションの構築にどの機能が使用されているかを特に注意する必要があります。たとえば、
互換性のあるアプリケーションを開発するということは、
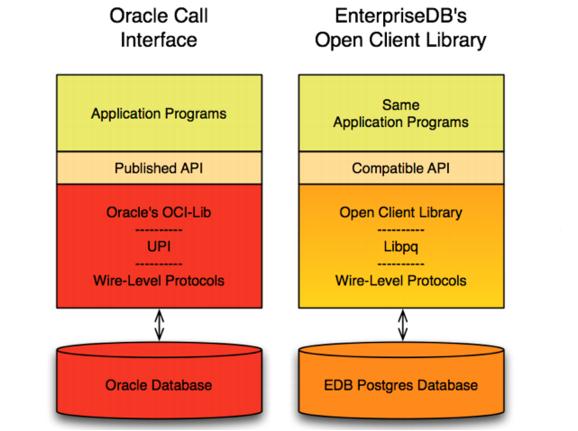
Oracle Call Interface (OCI) を使用して作成されたアプリケーションの場合 、EnterpriseDBの Open Client Library ( OCL )は、これらのアプリケーションとの相互運用性を提供します。 Open Client Libraryの使用方法の詳細については、「 EDB Postgres Advanced Server OCI Connector Guide」 を参照してください 。
Advanced Serverには、
PostgreSQLまたは
Oracle用のデータベースアプリケーションの開発を可能にする豊富な機能が含まれてい
ます 。 Advanced Serverのすべての機能の詳細については、EnterpriseDBのWebサイトにあるユーザーマニュアルを参照してください。
Advanced Server 11を作成するために 、
Advanced Server 10に 以下の Oracle機能の
データベース互換性が追加されました
。
以下の説明では、 用語は、言語キーワード、ユーザ提供値、リテラルなどの任意の単語または単語群を指す。用語の正確な意味は、それが使用される文脈に依存する。
• |
固定幅(単間隔)フォント は、 SQL コマンド、例で使用されている特定のテーブルとカラム名、プログラミング言語キーワード など、文字通り与えなければならない用語に使用され ます 。たとえば、 SELECT * FROM emp; |
• |
イタリック固定幅フォント は、ユーザーが実際の使用で値を置き換える必要がある用語に使用されます。たとえば、 DELETE FROM table_name ; |
EDB Postgres Advanced Serverは、
PostgreSQLおよび
Oracleと
互換性のあるアプリケーションの開発と実行をサポートし
ます 。いくつかのシステム動作は、より多くの
PostgreSQLまたはより
Oracleに準拠した方法で動作するように変更することができます。これらの動作は構成パラメータによって制御されます。ユーザーまたはグループが唯一の彼らのセッションを行うには、コマンドラインでパラメータ値を
設定することができながら
、postgresql.confファイル内のパラメータを変更すると、クラスタ内のすべてのデータベースの動作を変更します。これらのパラメータは次のとおりです。
• |
edb_redwood_date - DATE列に時刻コンポーネントを格納するかどうかを制御します。 Oracleデータベースと 互換性のある動作の場合は、 edb_redwood_dateを TRUEに設定 します 。セクションを参照 1.3.1 。 |
• |
edb_redwood_raw_names - Oracleシステムカタログから見たときにデータベースオブジェクト名を大文字で表示するか小文字で表示するかを制御します。 Oracleデータベースと 互換性のある動作の場合、 edb_redwood_raw_namesはデフォルト値の FALSEに設定され ます 。実際にPostgreSQLシステムカタログに格納されているデータベースオブジェクト名を表示するには、 edb_redwood_raw_namesを TRUEに設定します。 1.3.2節を参照してください。 |
• |
edb_redwood_strings - 文字列連結操作のために空の文字列に nullを指定します。 Oracleデータベースと 互換性のある動作の場合は、 edb_redwood_stringsを trueに設定し ます 。 1.3.3節を参照してください。 |
• |
edb_stmt_level_tx - 中断された SQLコマンドの自動ロールバックを文レベルのロールバックのみに分離します。デフォルトの PostgreSQLの動作と同様に、現在のトランザクション全体が自動的にロールバックされません。 Oracleデータベースと 互換性のある動作の 場合は 、 edb_stmt_level_txを trueに設定し ます 。ただし、絶対に必要な場合にのみ使用してください。 1.3.4節を参照してください。 |
• |
o racle_home - Advanced Serverを正しいOracleインストール・ディレクトリにポイントします。 1.3.5項を参照してください。 |
場合 DATE、コマンドの列のデータ・タイプとして表示され
、I Tは、設定パラメータ
edb_redwood_dateが trueに設定されている場合、テーブル定義はデータベースに格納された時点で
タイムスタンプに変換されます。したがって、時間成分も日付とともに列に格納されます。これは、
Oracleの
DATEデータ型と一致してい
ます 。
edb_redwood_dateが
falseに設定されている
場合 、
CREATE TABLEまたは
ALTER TABLEコマンドのカラムのデータ型は、元の
PostgreSQL DATEデータ型のままで、そのままデータベースに格納されます。
PostgreSQLの DATEデータ型は、列に時間コンポーネントを含まない日付のみを格納します。
関係なく設定の 日付は 、このような
SPL宣言セクション内の変数のデータ・タイプ、または
SPLプロシージャまたは
SPL関数で仮パラメータのデータ型、または他の任意の文脈でデータ型として現れ
edb_redwood_date、 SPL関数の戻り型では、常に内部的に
TIMESTAMPに変換されるため、存在する場合は時間コンポーネントを処理でき
ます 。
日付/時刻データ型の
詳細は、「 Oracle Developer Reference Guide」 の Database Compatibilityを 参照してください 。
とき edb_redwood_raw_namesが FALSEのデフォルト値に設定されているOracleカタログから見たとき、などのテーブル名、列名、トリガー名、プログラム名、ユーザ名、などのデータベース・オブジェクト名は、サポートされているカタログの完全なリストについては、(大文字で表示されます
Oracle Developer Reference Reference GuideのDatabase Compatibilityを参照してください)。さらに、引用符は、囲み引用符で作成された名前を囲みます。
edb_redwood_raw_namesが
TRUEに設定されている
場合 、データベースオブジェクト名は、Oracleカタログから見たときにPostgreSQLシステムカタログに格納されているとおりに表示されます。したがって、引用符を囲まずに作成された名前は、PostgreSQLで期待どおり小文字で表示されます。囲み引用符で作成された名前は、作成されたとおりに正確に表示されますが、引用符は使用しません。
edb_redwood_raw_namesをデフォルト値
FALSEに設定し
たOracleカタログ USER_TABLES から見た 場合 、名前は
Mixed_Case名を除いて大文字で表示されます。名前は作成されたものとして表示され、引用符で囲まれて表示されます。
で見た場合 TRUEに設定
edb_redwood_raw_names、名前が作成されたとして表示されますが、今で囲む引用符
Mixed_Case名を除いて小文字で表示されます。
オラクル 、文字列はヌル変数またはnullカラムと連結されている場合、結果は、元の文字列です。しかし、 PostgreSQLでは、文字列を変数nullまたはNULLで連結すると、結果がNULLになります。 edb_redwood_stringsパラメータがtrueに設定されている場合 、前述の連結操作では、 Oracleによって行われた元の文字列が返されます 。 edb_redwood_stringsがfalseに設定されている場合、ネイティブのPostgreSQLの動作は維持されます。
以下は、 edb_redwood_stringsが
TRUEに設定
されているときに実行される同じクエリです。ここでは、NULL列の値は空の文字列として扱われます。空の文字列を空でない文字列と連結すると、空でない文字列が生成されます。この結果は、同じクエリに対して
Oracleによって生成された結果と一致します。
でランタイムエラーは
、SQLコマンドで発生したときに
、Oracle、その単一のコマンドによって引き起こされるデータベース上のすべての更新がロールバックされます。これは、
文レベルのトランザクション分離と呼ばれ
ます 。たとえば、1つの
UPDATEコマンドが5行を正常に更新するが、6行目を更新しようとすると例外が発生した場合、この
UPDATEコマンドによって作成された6行すべての更新がロールバックされます。コミットまたはロールバックされていない以前の
SQLコマンドの影響は、
COMMITコマンドまたは
ROLLBACKコマンドが実行されるまで保留されます。
では SQLコマンドの実行中に例外が発生した場合
のPostgreSQL、トランザクションの開始以来、データベース上のすべての更新がロールバックされます。さらに、トランザクションは中止状態のままであり、別のトランザクションを開始する前に
COMMITまたは
ROLLBACKコマンドを発行する必要があります。
edb_stmt_level_txが
TRUEに設定されている
場合 、例外はコミットされていないデータベースの更新を自動的にロールバックして、
Oracleの動作をエミュレートしません。
edb_stmt_level_txが
FALSEに設定されている
場合 、例外はコミットされていないデータベースの更新をロールバックします。
注意:絶対に必要な場合にのみ、
edb_stmt_level_txを
TRUEに設定してください。パフォーマンスに悪影響を与える可能性があります。
次の例では 、
edb_stmt_level_txが
FALSEの場合 、2番目の
INSERTコマンドのアボートによって最初の
INSERTコマンドがロールバックされること
が PSQLで示されてい
ます 。
PSQLでは、コマンド
\ set AUTOCOMMIT offを発行
する必要があります。そう
しないと、すべての文が自動的に
edb_stmt_level_txの効果のデモンストレーションの目的を
破棄します。
次の例では、 edb_stmt_level_txを
TRUEに設定して、2番目の
INSERTコマンドで最初の
INSERTコマンドがエラーの後にロールバックされていません。この時点で、最初の
INSERTコマンドをコミットまたはロールバックできます。
ROLLBACKコマンドは、代わりに社員番号9001の挿入が同様にロールバックされていたであろう、その場合には、COMMITコマンドを発行されている可能性があります。
Windowsの場合のみ、代わりに
postgresqlに oracle _
home構成パラメータの
値を設定できます。
confファイル。
oracle _
home構成パラメータで指定された値は、Windows
PATH環境変数よりも優先されます。
LDは、_ _ LIBRARY Linux上のPATH環境変数(PATH環境変数またはWindows上のORACLE_HOME設定パラメータ)を適切に使用すると、Advanced Serverを起動するたびに設定する必要があります。
Windowsの場合のみ: postgresqlに oracle _
home構成パラメータを設定します。
confファイルを編集し、次の行を追加してファイルを編集します。
設定後 のOracle _
ホーム設定
パラメータを、変更を有効にするには、サーバーを再起動する必要があります。 Windowsサービスコンソールからサーバーを再起動します。
• |
EDB Postgres Advanced Serverの インストール中に 、このガイドに示す例と同じ結果を再現するために、Oracleデータベースと互換性のある構成とデフォルトの選択を選択する必要があります。デフォルトの 互換性のある構成は、 PSQLで次のコマンドを発行し、以下に示すように同じ結果を得ることによって検証できます。
|
• |
この例では、 Advanced Serverの インストール 時 に 作成およびロードされる サンプル表 dept 、 emp および jobhistを 使用しています 。 EMP テーブルは、このマニュアルに示されるように同じ結果を再現するために無効にされなければならないトリガーがインストールされています。 Enterprisedb スーパーユーザー として Advanced Serverに ログオンし 、次のコマンドを実行してトリガーを無効にします。 |
emp テーブル のトリガは、 後で次のコマンドで再アクティブ化できます。
このセクションでは、新規のリレーショナル・データベース管理システム
の SQL言語の
概要を説明します。テーブルの作成、移入、クエリ、更新などの基本的な操作については、例とともに説明します。
Advanced Serverは、
リレーショナルデータベース管理システム (
RDBMS )です。つまり、
関係に格納されたデータを管理するシステムです。関係とは本質的に
表のための数学的な用語です。テーブルにデータを格納するという考え方は、本質的に明らかであるように今日はあまり普及していませんが、データベースを整理する他の多くの方法があります。 Unixライクなオペレーティングシステム上のファイルとディレクトリは、階層型データベースの一例です。より現代的な開発は、オブジェクト指向のデータベースです。
各テーブルは、名前付きの 行の 集合です 。与えられた表の各行は同じ名前付き
列のセットを持ち、各列は特定の
データ型です。各行には列の順序が固定されてい
ますが、
SQLはテーブル内の行の順序を保証するものではありません(明示的に並べ替えて表示できます)。
テーブルは データベースに
グループ化され、1つの
Advanced Serverインスタンスによって管理されるデータベースの
集まりがデータベース
クラスタを構成します。
とき Advanced Serverが名前のサンプル・データベースをインストールされている
、EDB、自動的に作成されます。このサンプル・データベースには、
/ usr / edb / as11 / shareディレクトリーにあるスクリプト
edb-sample.sqlを実行することにより、この文書全体で使用される表とプログラムが入ってい
ます 。
次は、 edb-sample.sqlスクリプトです。
空白(空白、タブ、改行など)は、 SQLコマンドで
自由に使用できます。これは、上記とは異なる方法で、またはすべてを1行に並べてコマンドを入力できることを意味します。 2つのダッシュ(
" - " )はコメントを導入します。それに続くものは、行末まで無視されます。
SQLでは 、キーワードと識別子については大文字と小文字が区別されません。大文字と小文字を区別するために二重引用符が使用されている場合は例外です。
VARCHAR2(10)は、最大10文字の任意の文字列を格納できるデータ型を指定します。
NUMBER(7,2)は、精度7と位取り2の固定小数点数です
.NUMBER (4)は、精度4と位取り0の整数です。
Advanced Serverは、通常の
SQLデータ型
INTEGER 、
SMALLINT 、
NUMBER 、
REAL 、
DOUBLE PRECISION 、
CHAR 、
VARCHAR2 、
DATE 、および
TIMESTAMP 、およびこれらのタイプのさまざまな同義語をサポートしてい
ます 。
INSERT文は行を持つ表を移入するために使用されます。
テーブルからデータを取得するには、テーブルが 照会されます。これを行うには、
SQL SELECT文が使用されます。この文は、選択リスト(返される列をリストする部分)、表リスト(データを取り出す表をリストする部分)、およびオプションの修飾(制限を指定する部分)に分かれています。 。次の問合せでは、表内のすべての従業員のすべての列が特定の順序でリストされます。
問合せは、どの行が必要かを指定
する WHERE句を
追加することで修飾できます 。
WHERE句にはブール(真理値)式が含まれ、ブール式が真である行のみが返されます。通常のブール演算子(
AND 、
OR 、および
NOT )は、修飾で使用できます。たとえば、次の例では、部門20の従業員を$ 1000.00以上の給与で取得します。
すべての列は異なる名前(修飾されている必要がある
deptnoを
除く )を持つため、パーサーはどの表に属しているかを自動的に検出しましたが、結合問合せで列名を完全修飾するのは適切な方法です。
この問合せは、 左外部結合 と呼ばれます。これは、結合演算子の左側に記載されている表には、出力の各行が少なくとも1回は存在しますが、右側の表には、左のテーブル。右テーブルの一致がない左テーブルの行が選択された場合、右テーブルの列には空の(
NULL )値が代入されます。
外部結合の別の構文は、 WHERE句
内の結合条件で外部結合演算子 "(+)"を使用することです。外部結合演算子は、一致しない行の代わりにNULL値を代入する必要がある表の列名の後に置かれます。したがって、
emp表に一致する行がない
dept表のすべての行に対して、
Advanced Serverは
empの列を含む選択リスト式に対してnullを戻します。したがって、上記の例は次のように書き直すことができます。
ここでは、 emp表は選択リストおよび結合条件の従業員行を表す
e1 、および選択リストおよび結合条件のマネージャとして機能する一致する従業員行を表す
e2として再ラベル付けされています。次のように、これらのエイリアスを他のクエリで使用して入力を節約できます。
他のほとんどのリレーショナルデータベース製品と同様に、 Advanced Serverは集合関数をサポートしています。集合関数は、複数の入力行から単一の結果を計算します。たとえば、一連の行に対して
COUNT 、
SUM 、
AVG (平均)、
MAX (最大)、
MIN (最小)を計算する集計があります。
集計関数 MAXは
WHERE節で使用できない
ため、これは機能しません 。
WHERE句は集計ステージに入る行を決定し、集計関数が計算される前に評価される必要があるため、この制限があります。ただし、
サブクエリを使用して目的の結果を達成するために、クエリを再作成することができます。
WHERE句と
HAVING句の
間には微妙な違いがあります。
WHERE句は、グループ化が発生し、集約関数が適用される前に行をフィルタリングします。
HAVING句は、行がグループ化され、各グループに対して集計関数が計算された後の結果にフィルタを適用します。
Advanced Serverは、Oracle構文と互換性のある
SQL言語、拡張機能(Oracleとのデータベース互換性を提供しない機能、またはOracleスタイルのアプリケーションをサポートする機能)のための構文およびコマンドをサポートします。
ビュー名 employee_payを通常のテーブル名のように使用してクエリを実行できるようになりました。
セクション2.1.2に示されて
いる empテーブルの
変更されたバージョンが、このセクションでは、外部キー制約の追加とともに示されています。変更された
empテーブルは、次のようになります。
サンプル
emp表で
次の INSERTコマンド
を発行しようとすると 、外部キー制約
emp_ref_dept_fkによって部門
50が
dept表に確実に存在します。そうしないので、コマンドは拒否されます。
ROWNUMは、疑似列であり、問合せから行が検索された順序に基づいて、各行に対して増分の一意の整数値が割り当てられます。したがって、最初に検索される行の
ROWNUMは
1になります。 2行目は
ROWNUMが
2のようになります。
結果セットの任意の並べ替えが行われる前にROWNUM値は、各列に割り当てられています。したがって、結果セットはORDER BY句で指定された順序で返されますが、 ROWNUM値は必ずしも昇順である必要はありません。
次の SELECTコマンドは、新しい
seqno値を
表示します。
同義語は、SQLステートメント内の別のデータベース・オブジェクトを参照するために使用することができる識別子です。シノニムは、通常、データベース・オブジェクトがSQL文で適切に参照されるようにスキーマ名による完全修飾を必要とする場合に役立ちます 。そのオブジェクトに定義された同義語は、単一の修飾されていない名前への参照を簡素化します。
シノニムを作成
するには、 CREATE SYNONYMコマンドを使用します。構文は次のとおりです。
syn_nameは同義語の名前です。シノニム名は、スキーマ内で一意でなければなりません。
schemaは、シノニムが存在するスキーマの名前を指定します。スキーマ名を指定しない場合、シノニムは検索パスの最初の既存スキーマに作成されます。
既存の同義語定義を新しい同義語定義に置き換えるには
、 REPLACE句を
含めます 。
パブリック・スキーマにシノニムを作成するには
、 PUBLIC句を
含めます。 Oracleデータベースと互換性のある
CREATE PUBLIC SYNONYMコマンドは、
パブリック・スキーマに存在するシノニムを作成します。
これで、
enterprisedbスキーマの
emp表は、シノニム、
personnelを使用して、任意の
SQL文(
DDLまたは
DML)で参照でき
ます 。
syn_nameは同義語の名前です。シノニム名は、スキーマ内で一意でなければなりません。
schemaは、シノニムが存在するスキーマの名前を指定します。
必要に応じて、 PUBLIC句を
追加して、
パブリック・スキーマにあるシノニムを削除
できます。 Oracleデータベースとの互換性、
DROP PUBLIC SYNONYMコマンドは、
パブリック・スキーマに存在するシノニムを削除します。
階層クエリは、親子関係を構成するデータに基づいて階層順に結果セットの行を返すクエリの種類です。階層は、典型的には、反転ツリー構造によって表される。ツリーは、相互接続されたノードで構成されています。各ノードは、1つまたは複数の子ノードに接続することができます。各ノードは、親を持たない上位ノードを除いて、1つの親ノードに接続されています。このノードはルートノードです。各ツリーにはちょうど1つのルートノードがあります。子を持たないノードはリーフノードと呼ばれます。ツリーには、少なくとも1つのリーフノードが常に存在します。たとえば、ツリーが1つのノードで構成されているという単純なケースです。この場合、ルートとリーフの両方です。
注 :指定された単一の行が複数のツリーに表示され、結果セットに複数回表示される可能性があります。
問合せの階層関係は、結果セットで行が戻される順序の基礎を形成する
CONNECT BY句
によって記述されます 。
CONNECT BY句とそれに関連するオプションの句が
SELECTコマンドに現れるコンテキストを以下に示します。
select_listは、結果セットのフィールドを構成する1つ以上の式です。
table_expressionは、結果セットの行の
起点となる1つ以上の表またはビューです。
otherは、追加の法的な
SELECTコマンド句です。次のセクションでは、階層問合せに関連する
START WITH 、
CONNECT BY 、および
ORDER SIBLINGS BY節について説明します。
注意:現時点では、Advanced Serverは
CONNECT BY句での
AND (または他の演算子)の使用をサポートしていません。
2。 |
評価 table_expressionの評価から得られた他の任意の行に child_expr |
3。 |
場合 parent_expr = child_expr、この行は、所与の親の行の子ノードであります |
注意 :
WHERE句を
table_expressionに適用する前に、
行が子ノードであるかどうかを判断する評価プロセスは、
table_expressionによって返されるすべての行で発生します。
CONNECT BY句を含むSELECTコマンドは、典型的には、START WITH句を含みます。 START WITH句は、ルート・ノードになる行、つまり前述のアルゴリズムが適用される最初の親ノードである行を決定します。これについては、次のセクションでさらに説明します。
START WITH句は、ルートノードとして使用されるtable_expressionによって選択された行(複数可)を決定するために使用されます。 start_expressionが評価table_expressionによって選択されたすべての行は、真のツリーのルートノードになるために。したがって、結果セット内の潜在的なツリーの数は、ルートノードの数に等しい。結果として、 START WITH句が省略されると、 table_expressionによって返されるすべての行は、それ自身のツリーのルートになります。
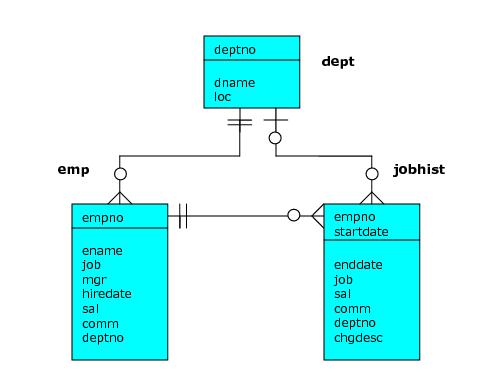
サンプル・アプリケーションの
emp表を
検討してください 。
empテーブルの行は、従業員のマネージャの従業員番号を含む
mgr列に基づいた階層を形成します。各従業員にはマネージャが最大で1人しかいません。
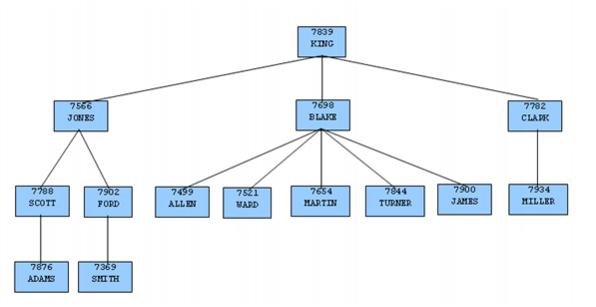
KINGは会社の社長であり、マネージャーがいないので、KINGの
mgr列はnullです。また、従業員が複数の従業員のマネージャーとして行動することも可能です。この関係は、以下に示すような典型的なツリー構造の階層的組織図を形成します。
この関係に基づいて階層クエリを形成するために、 SELECTコマンドには
CONNECT BY PRIOR empno = mgrという節が含まれてい
ます 。たとえば、従業員番号
7839の社長
KINGがあれば、
mgr列が
7839の従業員は、
JONES 、
BLAKE 、
CLARK (これは
KINGの子ノードです)に該当する
KINGに直接報告します。同様に、従業員
JONESの場合、
mgr列が
7566の他の従業員は
JONESの子ノードです。この例では
SCOTTと
FORDです。
組織図の一番上が KINGなので、このツリーにルートノードが1つあります。
START WITH mgr IS NULL句は、最初のルートノードとして
KINGのみを選択します。
LEVELは、疑似列で、
SELECTコマンドで列を表示できる場所であればどこでも使用できます。結果セットの各行について、
LEVELは、この行によって表されるノードの階層内の深度を指定する非ゼロの整数値を戻します。ルートノードの
LEVELは、ルートノードの直接の子のための
レベルは 2のように、そして1です。
共通の親を共有し、同じレベルにあるノードは 兄弟 と呼ばれます。たとえば、上記の出力では、
ALLEN 、
WARD 、
MARTIN 、
TURNER 、および
JAMESの従業員はすべてレベル3で親
BLAKEであるため、兄弟です。
JONES 、
BLAKE 、
CLARKはレベル2にあり、
KINGは共通の親であるため、兄弟です。
この最後の例は、 WHERE句を
追加し、 3つのルートノードで開始します。ノードツリーが構築された後、
WHERE句はツリー内の行をフィルタリングして結果セットを形成します。
注: 単項演算子は単一のオペランド上で動作します。これは、
CONNECT_BY_ROOTの場合は
CONNECT_BY_ROOTキーワードに続く列名です。
SELECTリストの
コンテキストでは 、
CONNECT_BY_ROOT演算子は次のように表示されます。
• |
CONNECT_BY_ROOT 演算子 は 、WHERE 句 、GROUP BY句、HAVING 句 、ORDER BY句、および ORDER兄弟 限り SELECT コマンドは階層クエリに そのままBY句 、SELECTリスト で使用することができます 。 |
• |
CONNECT_BY_ROOT オペレータ は、 句または 階層問合せのWITH句 START BY CONNECT で使用することができません 。 |
• |
列を含む式に CONNECT_BY_ROOT を適用することは可能ですが、そのためには式をかっこで囲む必要があります。 |
次の問合せは、 CONNECT_BY_ROOT演算子を
使用して、従業員
BLAKE 、
CLARK 、および
JONESで始まるツリーに基づいて結果セットにリストされている各従業員のルート・ノードの従業員番号と従業員名を戻します。
以下は、 CONNECT_BY_ROOTの 単項演算子効果を示しています。この例に示すように、カッコで囲まれていない式に適用すると、
CONNECT_BY_ROOT演算子は、その直後の
enameという用語にのみ影響します。その後の連結
|| '管理する' || enameは
CONNECT_BY_ROOT操作の一部ではないため、
enameの2番目の出現は現在処理されている行の値になり、
enameの最初の出現はルート・ノードからの値になります。
2.2.5.7 SYS_CONNECT_BY_PATHを使用し
たパスの取得 columnは、関数を呼び出す階層問合せで指定された表内にある列の名前です。
• |
レベル列は、クエリが返されるレベルの数を表示します。 |
• |
ENAME列には、従業員の名前が表示されます。 |
• |
経営者の欄には、管理者の階層リストが含まれています。
|
多次元分析とは、さまざまな次元の組み合わせを使用してデータを検査するデータ・ウェアハウス・アプリケーションで一般的に使用されるプロセスのことです。
ディメンションは、時間、地理、会社の部門、製品ラインなどのデータを分類するために使用されるカテゴリです。特定のディメンションセットに関連付けられた結果を
ファクトと呼びます。事実は、通常、製品の販売、利益、数量、数などに関連する数字です。
SQL
SELECTコマンド
の GROUP BY句は、集計結果の生成プロセスを簡素化する次の拡張をサポートしています。
さらに、 GROUPING関数と
GROUPING_ID関数を
SELECTリストまたは
HAVING節で使用して、これらの拡張が使用されたときの結果の解釈を支援することができます。
注意:サンプルの
deptおよび
emp表は、この例では使用例を提供するために広く使用されています。より有益な結果を得るために、以下の変更がこれらの表に適用されました。
LOC、DNAME、 ジョブ列は実施例で使用されるSQL集計の寸法のために使用されます。集計結果は、 COUNT(*)関数を使用して取得した従業員の数です。
ROLLUPとCUBE拡張は、結果セットに小計の追加のレベルを提供することによって、ベース集約行に追加します。
GROUPINGは、単一の結果セットにグループの異なるタイプを組み合わせる能力を提供する拡張機能を設定します 。
GROUPINGおよびGROUPING_IDは 、結果セットの解釈に援助を機能します。
ROLLUP拡張は、各階層グループならびに総計の小計とグループの階層的なセットを生成します。階層の順序は、 ROLLUP式リストで指定された式の順序によって決まります。階層の最上位はリストの一番左の項目です。右側に進む各連続する項目は階層の下に移動し、最も右側の項目が最も低いレベルになります。
各 exprは、結果セットのグループ化を決定する式です。
( expr_1a 、 expr_1b 、...)のように括弧で囲まれた場合、
expr_1aと
expr_1bによって返される値の組み合わせは、階層の単一のグループ化レベルを定義します。
さらに、リスト内の最初の項目( expr_1または
( expr_1a 、 expr_1b 、...)のいずれかが指定されている組み合わせ)に対して、それぞれの一意の値に対して
小計が戻されます。リスト内の2番目の項目(
expr_2または
( expr_2a 、 expr_2b 、...)のいずれかが指定されているいずれかの組み合わせ)が最初の項目の各グループ内で一意の値ごとに返されます。最後に、結果セット全体に対して総計が返されます。
GROUP BY句のコンテキスト内で指定されたROLLUP拡張は、以下のように示されています。
select_listで 指定された項目は、
ROLLUPの expression_listにも表示されなければなりません。
COUNT 、
SUM 、
AVG 、
MIN 、
MAXなどの集計関数である必要があります。または、戻り値がグループ内の個々の行とは無関係の定数または関数でなければなりません(たとえば、
SYSDATE関数)。
GROUP BY句は、拡張機能や、個々の表現することで 、複数の ROLLUP拡張だけでなく、他のグループの複数の発生を指定することもできます。
出力を階層構造またはその他の意味のある構造で表示する場合は
、 ORDER BY句を使用する必要があります。
ORDER BY句が指定されていない場合、結果セットの順序は保証されません。
CUBE拡張は、ROLLUP拡張に似ています。しかし、ROLLUP式リスト内の項目の右側のリストに左に基づく階層でグループ化し、結果を生成ROLLUPとは異なり、CUBEは CUBE式リスト内のすべての項目のすべての順列に基づいてグループ化し、小計を生成します。したがって、結果セットには、同じ式リストで実行されたROLLUPより多くの行が含まれています。
各 exprは、結果セットのグループ化を決定する式です。
( expr_1a 、 expr_1b 、...)のように括弧で囲まれた場合、
expr_1aと
expr_1bによって返される値の組み合わせは単一のグループを定義します。
さらに、リスト内の最初の項目( expr_1または
( expr_1a 、 expr_1b 、...)のいずれかが指定されている組み合わせ)に対して、それぞれの一意の値に対して
小計が戻されます。リスト内の2番目の項目(
expr_2または
( expr_2a 、 expr_2b 、...)のいずれかが指定されています)の小計が各一意の値に対して
戻されます。また、最初の項目と2番目の項目の固有の組み合わせごとに小計が返されます。同様に、第3のアイテムがある場合、第3のアイテムの各固有値、第3のアイテムおよび第1のアイテムの組み合わせのそれぞれの固有値、第3のアイテムおよび第2のアイテムの組み合わせのそれぞれの固有値、およびそれぞれの固有値第3のアイテム、第2のアイテム、および第1のアイテムの組み合わせのうちの1つを含む。最後に、結果セット全体に対して総計が返されます。
GROUP BY句のコンテキスト内で指定されたキューブの拡張は、以下のように示されています。
select_listで 指定された項目は、
CUBEの expression_listにも表示される必要があります。
COUNT 、
SUM 、
AVG 、
MIN 、
MAXなどの集計関数である必要があります。または、戻り値がグループ内の個々の行とは無関係の定数または関数でなければなりません(たとえば、
SYSDATE関数)。
GROUP BY句は、拡張機能や、個々の表現することで 、複数の CUBE拡張だけでなく、他のグループの複数の発生を指定することもできます。
出力を意味のある構造で表示する場合は
、 ORDER BY句を使用する必要があります。
ORDER BY句が指定されていない場合、結果セットの順序は保証されません。
クエリの結果は次のとおりです。 loc 、
dname 、
jobの 各組み合わせの従業員数 、および
locと
dnameの各組み合わせの小計、
dnameと
jobの組み合わせごとの、それぞれの
locと
jobの組み合わせの
カウントがあります
ジョブの一意の値ごとに
dnameの一意の値ごとに
locの一意の値、最後の行に表示される総計。
GROUP BY句内
の GROUPING SETS拡張子を
使用すると、異なるグループ化に基づいて複数の結果セットを実際に連結した結果セットを生成することができます。つまり、複数のグループ化の結果セットを1つの結果セットに結合する
UNION ALL操作が実行されます。
UNION ALL操作、したがって
GROUPING SETS拡張は、結合されている結果セットから重複した行を削除しないことに
注意してください 。
単一の GROUPING SETS拡張
の構文は次のとおりです。
GROUPINGは、拡張子が1つまたは複数のカンマで区切られた式、括弧で囲まれた式のリスト、ROLLUP拡張 、およびCUBEの拡張子の任意の組み合わせを含めることができます設定します 。
グループ化は、以下で示されるように拡張がGROUP BY句のコンテキスト内で指定されている設定します 。
select_listで 指定された項目は、
GROUPING SETSの expression_listにも表示する必要があります。
COUNT 、
SUM 、
AVG 、
MIN 、
MAXなどの集計関数である必要があります。または、戻り値がグループ内の個々の行とは無関係の定数または関数でなければなりません(たとえば、
SYSDATE関数)。
複数のグループを指定することがGROUP BY句は、拡張だけでなく、拡張機能や個々の表現BY他のグループの複数の出現を設定します 。
出力を意味のある構造で表示する場合は
、 ORDER BY句を使用する必要があります。
ORDER BY句が指定されていない場合、結果セットの順序は保証されません。
UNION ALL問合せ
からの出力は、
GROUPING SETS出力と同じです。
次のクエリは、 GROUP BY ROLLUP(dname、job)句を使用します。
次のクエリでは、 GROUP BY CUBE(job、loc)句が使用されます。
以下は、 GROUP BY GROUPING SETS(loc、ROLLUP(dname、job)、CUBE(job、loc))節が使用さ
れているときと同じ出力です。
使用する場合 ROLLUP、CUBE、または
GROUPING GROUP BY句の拡張機能を
設定し 、時々 、結果セット内の拡張、ならびにベース集約行によって生成された小計の様々なレベルを区別することが困難であってもよいです。
GROUPING関数は、この区別を行う手段を提供します。
GROUPING関数は、ROLLUP、CUBE、またはGROUPINGの式リストに指定されたディメンション列の発現は、GROUP BY句の拡張を設定しなければならない単一のパラメータを取ります。
GROUPING関数
の戻り値は、 0または1のいずれかです。クエリの結果セットでは、行がその列の複数の値に対する小計を表しているため、
GROUPING関数で指定された列式がNULLの場合、
GROUPING関数は値が1です。行が
GROUPING関数で指定された列の特定の値に基づいて結果を戻す場合、
GROUPING関数は値0を戻します。後者の場合、列はNULLでも非NULLでもかまいませんいずれの場合でも、その列の特定の値であり、複数の値にまたがる小計ではありません。
GROUPING関数は、ベース集計行から、または式リスト内の項目の一つが表現は、1つ以上のヌルである基づいている列の結果としてnullを返す特定の小計行の小計行を区別するために使用することができます列の小計を表すのではなく、表の行を使用します。
ジョブ列(
gf_job )
の GROUPING関数が1を返す
5番目の行は、これがすべてのジョブの小計であることを示します。行には、
employees列に小計の値9が含まれていることに注意してください。
ジョブ列と
loc列
の GROUPING関数が0を返す
4番目の行は、 locが
BOSTONで
jobがnull(この例では挿入された行)であるすべての行の基本集約であることを示します。
従業員の列には、挿入されたそのような単一の行のカウントである1が含まれます。
また、9行目(次の最後まで)に注意 LOCカラム上で
グループ化機能は、これが
ジョブ列がヌルであるすべての場所の上に小計であることを示す1を返しながら、
ジョブ列に
GROUPING関数は再び、であり、0を返しますこの例で挿入された単一行のカウント。
GROUPING_ID関数は、拡張を設定 ROLLBACK、CUBE、またはGROUPINGからの結果セット内の行の小計レベルを決定するために、GROUPING関数の簡略化を提供します。
GROUPING関数は1列のみ発現を取り、列が与えられた列のすべての値にわたって小計であるか否かの指示を返します。したがって、複数のグループ化機能を持つクエリの小計のレベルを解釈するには、複数のGROUPING関数が必要になることがあります。
GROUPING_ID関数はROLLBACK、 キューブに使用されている1つ以上の列表現を受け入れる、またはグループ化の拡張機能を設定し、これらの列の小計が集約されたオーバーを決定するために使用することができる単一の整数を返します。
GROUPING_ID機能はROLLUP、CUBE、またはGROUPINGの式リストに指定されたディメンション列の式でGROUP BY句の拡張機能を設定しなければならない1つ以上のパラメータを取ります。
GROUPING_ID関数は、整数値を返します。この値は、 GROUPING_IDで指定されたパラメータの順序と同じ左から右の順序で指定された一連のGROUPING関数によって返される、連結された1と0からなるビットベクトルのベース10解釈に対応します関数。
次のクエリは 、列
gidで表される
GROUPING_ID関数の
戻り値が、列
locおよび
dnameの 2つの
GROUPING関数によって返された値に
どのように対応するかを示しています。
したがって、 dnameで
小計のみを表示するには、
GROUPING_ID関数に基づいて
HAVING句を使用して、次の簡略化されたクエリを使用できます。
Advanced Serverは 、代替プロファイルが指定されていない限り、ロールの作成時に新しいロールに関連付け
られた defaultという
名前のプロファイルを作成します。以前のサーバーバージョンからAdvanced Serverにアップグレードすると、既存のロールが自動的に
デフォルトプロファイルに割り当てられます
。 既定の プロファイル は削除できません 。
デフォルトの プロファイルは、次の属性を指定します。
データベースのスーパーユーザーは、 ALTER PROFILE コマンドを 使用 して、 デフォルト プロファイルで 指定された値を変更します 。プロファイルの変更の詳細については、 2.3.2 項を参照してください 。
新しいプロファイルを作成
するには、 CREATE PROFILEコマンドを使用します。構文は次のとおりです。
Advanced Serverによって実行されるルールを指定するには 、 LIMIT 句と1つ以上のスペース区切り パラメータ / 値の ペアを 含め ます。
パラメータ は、プロファイルによって制限される属性を指定します。
FAILED_LOGIN_ATTEMPTSは、サーバーが
PASSWORD_LOCK_TIMEで指定された時間、アカウントからユーザーをロックする前に、ユーザーが失敗したログイン試行の回数を指定します。サポートされる値は次のとおりです。
• |
DEFAULT - DEFAULT プロファイルで 指定された FAILED_LOGIN_ATTEMPTS の値 。 |
• |
無制限 - 接続しているユーザーは、失敗したログイン試行回数を無制限にすることがあります。 |
PASSWORD_LOCK_TIME は、サーバーが FAILED_LOGIN_ATTEMPTSの ためにロックされたアカウントのロックを解除するまでの時間を指定します 。サポートされる値は次のとおりです。
• |
0以上 の 数値 。 1日の小数部分を指定するには、小数値を指定します。たとえば、値 4.5を使用して 4日 12時間を指定します。 |
• |
DEFAULT - DEFAULTプロファイルで指定された PASSWORD_LOCK_TIMEの値。 |
• |
無制限 -アカウントはデータベーススーパーユーザーによって手動でロック解除されるまでロックされます。 |
PASSWORD_LIFE_TIMEは、ユーザーに新しいパスワードを入力する前に現在のパスワードを使用する日数を指定します。
PASSWORD _
LIFE _
TIME句を使用する場合は、
PASSWORD _
GRACE _
TIME句を含めて、ロールによる接続が拒否されるまでにパスワードが期限切れになってから経過する日数を指定します。
PASSWORD _
GRACE _
TIMEが指定されていない場合、パスワードは
PASSWORD _
GRACE _
TIMEのデフォルト値で指定された日に期限切れになり、ユーザーは新しいパスワードが提供されるまでコマンドを実行できなくなります。サポートされる値は次のとおりです。
• |
0 以上 の 数値 。 1日の小数部分を指定するには、小数値を指定します。たとえば、値 4.5を使用して 4日 12時間を指定します。 |
•
|
DEFAULT - DEFAULT プロファイルで 指定された PASSWORD_LIFE_TIME の値 。 |
PASSWORD_GRACE_TIME パスワードが期限切れになった後、ユーザがパスワードを変更するまでの猶予期間の長さを示します。猶予期間が切れると、ユーザーは接続を許可されますが、期限切れのパスワードを更新するまでコマンドを実行することはできません 。サポートされる値は次のとおりです。
• |
0 以上 の 数値 。 1日の小数部分を指定するには、小数値を指定します。たとえば、値 4.5を使用して 4日 12時間を指定します。 |
• |
DEFAULT - DEFAULT プロファイルで 指定された PASSWORD_GRACE_TIME の値 。 |
PASSWORD_REUSE_TIMEは
、ユーザーがパスワードを
再使用する
まで待機する日数を指定
します。
PASSWORD _
REUSE _
TIMEと
PASSWORD _
REUSE _
MAXパラメーターは、一緒に使用するためのものです。これらのパラメータの1つに有限値を指定し、他のパラメータを
無制限に指定すると 、古いパスワードを決して再利用することはできません。両方のパラメータが
UNLIMITEDに設定されている場合は、パスワードの再利用に制限はありません。サポートされる値は次のとおりです。
• |
0 以上 の 数値 。 1日の小数部分を指定するには、小数値を指定します。たとえば、値 4.5を使用して 4日 12時間を指定します。 |
• |
DEFAULT - DEFAULT プロファイルで 指定された PASSWORD_REUSE_TIME の値 。 |
• |
無制限 - パスワードは制限なしで再利用できます。 |
PASSWORD_REUSE_MAXは
、パスワードを再利用できるようにするために必要なパスワードの変更回数を指定
します。 PASSWORD _
REUSE _
TIMEと
PASSWORD _
REUSE _
MAXパラメーターは、一緒に使用するためのものです。これらのパラメータの1つに有限値を指定し、他のパラメータを
無制限に指定すると 、古いパスワードを決して再利用することはできません。両方のパラメータが
UNLIMITEDに設定されている場合は、パスワードの再利用に制限はありません。サポートされる値は次のとおりです。
• |
DEFAULT - DEFAULT プロファイルで 指定された PASSWORD_REUSE_MAX の値 。 |
• |
無制限 - パスワードは制限なしで再利用できます。 |
• |
DEFAULT - DEFAULT プロファイルで 指定された PASSWORD_VERIFY_FUNCTION の値 。 |
プロファイルを削除するには、
DROP PROFILEコマンドを
使用します。
次のコマンドは、 accts という名前のプロファイルを作成します 。このプロファイルでは、パスワードを最後に使用してから180日以内にユーザーがパスワードを再使用できないように指定しています。パスワードを再使用する前に少なくとも5回パスワードを変更する必要があります。
指定する場合 PASSWORD_VERIFY_FUNCTIONを、あなたは、ユーザーが自分のパスワードを変更するときに適用されるセキュリティルールを指定し、カスタマイズ機能を提供することができます。たとえば、新しいパスワードが少なくとも
n文字以上でなければならず、特定の値を含まないようにするルールを指定できます。
function _ name ( ユーザー _ 名 VARCHAR2、
新しい _ パスワード VARCHAR2、
old _ password VARCHAR2)RETURNブール値
new _ passwordは新しいパスワードです。
old _ passwordはユーザーの以前のパスワードです。関数内でこのパラメータを参照する場合は、次のようにします。
CREATEROLE属性を
持つ ユーザーがパスワードを変更すると、その文に
REPLACE句が含まれている場合、パラメータは以前のパスワードを渡します。
REPLACE句は、
CREATEROLE権限を
持つユーザのオプションの構文
です 。
次の文は、 verify _
password関数の
所有権を enterprisedbデータベースのスーパーユーザーに設定します。
その後、 検証 _
パスワード機能は、プロファイルに関連付けられています。
次に、 アリスがデータベースに接続してパスワードを変更しようとすると、彼女はプロファイル関数によって確立された規則に従わなければなりません。
CREATEROLEのないスーパーユーザー以外のユーザーは、パスワードを変更するときに
REPLACE句を含める必要があります。
アリス が自分のパスワードを変更することにした 場合 、新しいパスワードに古いパスワードが含まれていてはなりません。
ユーザー定義プロファイルを変更
するには、 ALTER PROFILEコマンドを
使用します。 Advanced Serverは、次の2つの形式のコマンドをサポートしています。
Advanced Serverによって実行されるルールを指定するには 、 LIMIT 句と1つ以上のスペース区切り パラメータ / 値の ペアを 含める か、 ALTER PROFILE ...
RENAME TOを使用してプロファイルの名前を変更します。
パラメータ は、プロファイルによって制限される属性を指定します。
ログインロールがサーバへの接続を試みると、
acctg_profileは失敗した接続試行回数をカウントします。このプロファイルでは、ユーザーが3回の試行で正しいパスワードで認証されなかった場合、そのアカウントは1日ロックされるように指定されています。
DROPを 使用する PROFILE コマンドを使用してプロファイルを削除します。構文は次のとおりです。
IFを 含める 指定されたプロファイルが存在しない場合、サーバーにエラーをスローしないように指示する EXISTS 句。プロファイルが存在しない場合、サーバーは通知を出します。
オプションの CASCADE 句を 含めて 、プロファイルに現在関連付けられているユーザーをすべて デフォルトの プロファイル に再割り当てし、プロファイルを 削除します 。
オプションの RESTRICT 句を 含めて 、ロールに関連付けられたプロファイルを削除しないようにサーバーに指示します。これがデフォルト動作です。
このコマンド
の RESTRICT句は、プロファイルに関連付けられているロールがある場合、
acctg_profileを削除しないようにサーバーに指示します。
プロファイルを作成した後、 ALTER USER ... PROFILEまたは
ALTER ROLE ... PROFILEコマンドを使用して、プロファイルをロールに関連付ける
ことができます 。プロファイル管理機能に関連するコマンド構文は次のとおりです。
どこ オプションは、 次の互換性の句を指定できます。
または オプション は、次の互換性のない節に する ことができます。
Advanced Serverでサポートされている
ALTER USERコマンドまたは
ALTER ROLEコマンド
の管理句については 、次のURLにあるPostgreSQLのコアドキュメントを参照してください。
事前定義されたプロファイルを役割に関連付ける、または事前定義されたプロファイルがユーザーに関連付けられていることを変更するに
は、 PROFILE句と
profile_nameを
含めます。
ACCOUNT句と
LOCKまたは
UNLOCKキーワードを
含めて、ユーザー・アカウントをロック状態またはロック解除状態にする必要があることを指定します。
インクルードこのロールに割り当てられたプロファイルの
TIMEパラメータ _ _
LOCK指定した時刻に役割をロックする
LOCK TIME「 タイムスタンプ 」句と日付/時刻値を、および
PASSWORDで示される時点で役割のロックを解除します。
LOCK TIMEを ACCOUNT LOCK句とともに使用すると、ロールは
ACCOUNT UNLOCK句を使用してデータベースのスーパーユーザーのみがロックを解除できます
。
パスワードを 含める ATの EXPIRE 句 ' timestamp ' キーワードを使用して、ロールに関連付けられたパスワードの有効期限が切れる日時を指定します。 AT を省略すると ' timestamp ' キーワードを入力すると、パスワードはすぐに期限切れになります。
パスワードを 含める セット AT ' timestamp ' キーワードを使用して、パスワード修正日を指定された時間に設定します。
ストアを 含める 先行 パスワード { 'パスワード' 'タイムスタンプ } [、...] 新しいパスワードとパスワードが設定された時刻を追加します。
次のコマンドは、 ALTER USER ... PROFILEコマンドを
使用して、 acctgという名前のプロファイルを
johnという名前のユーザーに関連付けます。
次のコマンドは、 ALTER ROLE ... PROFILEコマンドを
使用して、 acctgという名前のプロファイルを
johnという名前のユーザーに関連付けます。
ALTER ユーザー|役割 名
アカウント {LOCK | UNLOCK}
ロックタイム ' タイムスタンプ '
アカウントを 含める 直ちに役割をロックする LOCK 節。ロックされると、ロールの LOGIN 機能は無効になります。 アカウント を指定すると LOCK TIME句が指定されていない
LOCK句で
は、スーパーユーザが ACCOUNTを 使用するまでロールの状態は変更されません UNLOCK 句を使用してロールを解除します。
アカウントを 使用する UNLOCK 句を使用してロールを解除します。
ロックを 使用する 時間 ' timestamp ' 句 は、このロールに関連付けられたプロファイルの PASSWORD_LOCK_TIME パラメータで 指定された時間だけ、指定されたタイムスタンプで指定された時刻にアカウントをロックするようにサーバーに指示します 。
ロックを 組み合わせる TIME ' timestamp ' 句と ACCOUNT ACCOUNT を呼び出すスーパーユーザーによってアカウントがロック解除されるまで、指定された時間にアカウントをロックする LOCK 句 UNLOCK 句。
次の例では、 ACCOUNT LOCK句を
使用して johnという名前のロールをロックし
ます。 ACCOUNT UNLOCK句を使用してアカウントがロック解除されるまで、アカウントはロックされたままです。
次の例では、 ACCOUNT UNLOCK 句を 使用して john という名前のロールをロック解除し ます。
次の例では、 LOCK 時間 2015年9月4日に
johnという名前のロールをロックするための
' timestamp ' 節 :
次の例では、 LOCK 時間 ' timestamp ' 句と ACCOUNT LOCK句を使用して、2015年9月4日に
johnという名前のロールをロックします。
データベース・スーパー・ユーザーは、 CREATE USER |
CREATE USER 節の句を使用できます 。
ROLEコマンドを使用して、ロールの作成時に名前付きプロファイルを
ロールに割り当てたり、ロールのプロファイル管理の詳細を指定することができます。プロファイル管理機能に関連するコマンド構文は次のとおりです。
どこ オプションは、次の互換性の句を指定できます。
または オプションは、次の互換性のない節に
することができます。
Advanced Serverでサポートされている
CREATE USERまたは
CREATE ROLEコマンド
の管理句の詳細については、次のURLにあるPostgreSQLのコアドキュメントを参照してください。
CREATEで 作成されたロール USER コマンドはログインロールです(デフォルト)。 CREATEで 作成されたロール ROLE コマンドは(デフォルトでは)ログインロールではありません。 CREATE を使用してログインアカウントを作成するには ROLE コマンドを使用するには、 LOGIN キーワードを 含める必要があります 。
事前定義されたプロファイルを役割に関連付ける、または事前定義されたプロファイルがユーザーに関連付けられていることを変更するに
は、 PROFILE句と
profile_nameを
含めます。
ACCOUNT句と
LOCKまたは
UNLOCKキーワードを
含めて、ユーザー・アカウントをロック状態またはロック解除状態にする必要があることを指定します。
インクルードこのロールに割り当てられたプロファイルの
TIMEパラメータ _ _
LOCK指定した時刻に役割をロックする
LOCK TIME「 タイムスタンプ 」句と日付/時刻値を、および
PASSWORDで示される時点で役割のロックを解除します。
LOCK TIMEを ACCOUNT LOCK句とともに使用すると、ロールは
ACCOUNT UNLOCK句を使用してデータベースのスーパーユーザーのみがロックを解除できます
。
パスワードを 含める オプションの ATを 持つ EXPIRE 句 ' timestamp ' キーワードを使用して、ロールに関連付けられたパスワードの有効期限が切れる日時を指定します。 AT を省略すると ' timestamp ' キーワードを入力すると、パスワードはすぐに期限切れになります。
次の例では、 CREATE USERを使用して、
acctg_profileプロファイルに関連付けられた
johnというログイン・ロールを作成します。
johnはパスワード
1safepwdを使用してサーバーにログインできます。
次の例では、 CREATE ROLEを使用して、
acctg_profileプロファイルに関連付けられた
johnというログイン・
ロールを作成します。
johnはパスワード
1safepwdを使用してサーバーにログインできます。
プロファイルには、 Advanced Serverによって強制される動作を指定するユーザー定義関数を参照
する PASSWORD _
VERIFY _
FUNCTION節
が含まれます。
プロファイルはグローバルオブジェクトです。それらはクラスタ内のすべてのデータベースによって共有されます。プロファイルはグローバルオブジェクトですが、ユーザー定義関数はデータベースオブジェクトです。
-gまたは
-rオプション
を指定して pg_dumpallを
呼び出すと、既存のプロファイルの定義を再作成するスクリプトが作成
されますが、 PASSWORD _ VERIFY _ FUNCTION 句で 参照されるユーザー定義関数は再作成されません 。これらの関数が存在するデータベースを明示的にダンプ(および後で復元)するには、
pg_dumpユーティリティを使用する必要があります。
PASSWORD_VERIFY_FUNCTION句が
DEFAULTまたは
NULLに設定されている
場合、動作は
pg_dumpall -gまたは
pg_dumpall -r コマンドによって生成されたスクリプトによって複製され
ます。
DELETE 、 INSERT 、 SELECT または UPDATE コマンド を呼び出す と、サーバーは一連の実行計画を生成します。それらの実行計画を分析した後、サーバーは、(最も)最も時間のかかる結果セットを返すプランを選択します。サーバーの計画の選択は、いくつかの要素に依存します。
原則として、クエリプランナは最もコストの安いプランを選択します。 オプティマイザ を使用することができます クエリプランを選択するときにサーバーに影響を与える ヒント 。オプティマイザ・ヒントは、 DELETE 、 INSERT 、 SELECT または UPDATE コマンドの 直後にあるコメントのような構文に埋め込まれたディレクティブ(または複数のディレクティブ) です。コメント内のキーワードは、結果セットを作成するときに特定のプランを採用または回避するようサーバーに指示します。
• |
SQLコマンド でテーブル名またはビュー名にエイリアスを使用する場合は、ヒントで元のオブジェクト名ではなくエイリアス名を使用する必要があります。たとえば、コマンドの SELECT / * + FULL(acct)* / * FROM accounts acct ...、 acct 、 アカウントのエイリアスは、テーブル名ではなく、 FULLヒントで指定する必要があり ます 。 |
ヒントが正しく形成され、プランナーがヒントを
使用していることを確認
するには、 EXPLAINコマンドを使用します。 Advanced Serverを参照してください。
EXPLAINコマンドについては、ドキュメンテーション・セットを参照して
ください 。
DELETE 、
INSERT 、
SELECT 、または
UPDATEコマンド
の残りの部分 。
Advanced Serverデータベースクラスタの
デフォルト設定として選択できるいくつかの最適化モードがあります。この設定は、オプティマイザ・ヒント内の個々の
DELETE 、
SELECTおよび
UPDATEコマンドと同様に、
ALTER SESSIONコマンドを使用して、セッションごとに変更することもできます。これらのデフォルト・モードを制御する構成パラメーターの名前は
OPTIMIZER_MODEです。次の表に、使用可能な値を示します。
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
結果セットの 最初の n 行の 検索用に最適化し ます。このフォームは、 ALTER SESSION SET OPTIMIZER_MODE コマンドの オブジェクトとして使用できません 。これは、 SQL コマンド 内のヒントの形式でのみ使用でき ます 。
|
OPTIMIZER_MODEパラメータ
の現在の値は 、
SHOWコマンドを使用して表示できます。このコマンドは、ユーティリティに依存するコマンドであることに注意してください。
PSQLでは、
SHOWコマンドは次のように使用されます。
Oracleデータベースと互換性
のある SHOWコマンドの構文は次のとおりです。
|
|
|
|
|
|
リレーションにアクセスするには、 table index を 使用 し table 。 |
|
|
さらに、 表2-1 の ALL_ROWS 、
FIRST_ROWS 、および
FIRST_ROWS( n )のヒントを使用できます。
次の手順では、 bank という名前のデータベースを作成し、テーブル、
pgbench_accounts 、
pgbench_branches 、
pgbench_tellers 、および
pgbench_historyで作成します。
-s 20オプションは
pgbench_accountsテーブル内2,000,000行と
pgbench_branchesテーブルの20行の合計をもたらす100,000アカウントで20の分岐、それぞれの生成をもたらす20のスケーリング係数を指定します。 10人の
Tellerが各ブランチに割り当てられ、合計200行が
pgbench_tellersテーブルに格納されます。
以下は、
銀行データベースの
pgbenchアプリケーションを
初期化します。
EXPLAINコマンドは問い合わせプランナによって選択されたプランを示しています。次の例では、 aidが主キー列であるため、索引検索はpgbench_accounts_pkey索引で使用されます。
以下に示すようにFULLヒントは、インデックスを使用するのではなく、完全なシーケンシャルスキャンを強制するために使用されます。
以下に示すようにNO_INDEXヒントではなく、インデックスの使用の並列順次走査を強制します。
前の例に示すように
EXPLAINコマンド
を使用することに加えて 、plannerによってヒントが使用されたかどうかに関するより詳細な情報は、
trace_hints構成パラメーターを次のように設定することによって取得できます。
NO_INDEXヒントとSELECTコマンドはtrace_hints設定パラメータが設定されているときに生じる付加的な情報を説明するために以下繰り返されます。
ヒントが無視されると、 INFO:[HINTS]行は表示されません。これは、索引名のスペルが誤っている次の例に示すように、ヒントに構文エラーまたはその他のスペルミスがあったことを示している可能性があります。
含める彼らは
FROM句にリストされている順序でテーブルを結合するクエリオプティマイザに指示するよう
命じディレクティブを。
ORDEREDキーワードを指定しないと、照会オプティマイザーは表を結合する順序を選択します。
では 、コマンドの
順序付きバージョン、Advanced Serverは最初
JOBHIST時間で結果を結合する前に
DEPT dで
EMP eを参加します。
ORDEREDディレクティブがなければ、ジョイン順はクエリオプティマイザによって選択されます。
注意: Oracleスタイルの外部結合( '+'記号を含む結合)では
、 ORDERED指令は機能しません。
• |
マージソート結合 - 各テーブルは、ジョインが開始する前にジョイン属性でソートされます。次に、2つのテーブルが並列にスキャンされ、一致する行が結合されて結合行が形成されます。 |
• |
ハッシュ結合 - テーブルがスキャンされ、その結合属性がその結合属性をハッシュ・キーとして使用してハッシュ表にロードされます。次に、他の結合された表がスキャンされ、その結合属性がハッシュ・キーとして使用されて、一致する行が最初の表から検索されます。 |
次の例では 、
pgbench_branchesおよび
pgbench_accountsテーブルの結合に
USE_HASHヒントが使用されています。クエリ・プランは、
pgbench_branches表の結合属性からハッシュ表を作成することによってハッシュ結合が使用されることを示しています。
次に、 NO_USE_HASH(ab)ヒントは、プランナにハッシュテーブル以外のアプローチを使用させるように強制します。結果はマージ結合です。
最後に、 USE_MERGEヒントは、プランナーにマージ結合を使用させるように強制します。
ビュー txは、セクション
2.4.4の最後の例に示す
pgbench_history 、
pgbench_branches 、および
pgbench_accountsの3つのテーブルの結合から作成されます。
サブクエリ内
の emp表に
ヒントを適用して 、表スキャンではなく索引
emp_pkで索引スキャンを実行できます。クエリプランの違いに注意してください。
APPEND ヒント はまた、INSERT の SELECT 句 に含めることができます INTO ステートメント:
PARALLELオプティマイザヒントは、並列スキャンを強制するために使用されます。
NO_PARALLELオプティマイザヒントは、並列スキャンの使用を防止します。
パラレルスキャンとは、複数のバックグラウンドワーカーを使用して、特定のクエリに対して同時にテーブルをスキャンする(つまりパラレルに実行する)ことです。このプロセスは、順次スキャンなどの他の方法よりもパフォーマンスの向上をもたらします。
parallel_degreeは、並列スキャンに使用するワーカーの希望する数を指定する正の整数です。これを指定
すると、
parallel_degreeと構成パラメータ
max_parallel_workers_per_gatherのうち小さい方が計画された作業者数として使用されます。
max_parallel_workers_per_gatherパラメータの詳細については、
19.4.6節「
非同期 動作」を参照してください。ここでは、PostgreSQLのコアドキュメントの
リソース 消費量を示します。
DEFAULTが指定されている
場合 、可能な最大並列度が使用されます。
parallel_degreeと
DEFAULTの 両方を省略
すると、問合せオプティマイザは並列度を決定します。この場合、
parallel_workers記憶域パラメーターを使用して
表が設定されている場合は、この値が並列度として使用されます。そうでない場合、
DEFAULTが指定されたかのように、オプティマイザーは可能な最大並列度を使用します。
parallel_workersストレージパラメータの詳細については、PostgreSQLのコアドキュメントの
CREATE TABLEの Storage Parametersサブセクションを参照してください。
次の例では、 PARALLELヒントを
使用しています。クエリプランでは、バックグラウンドワーカーを起動するGatherノードは、2人のワーカーを使用する予定であることを示します。
注: trace_hintsが
onに設定され
ている場合、
INFO:[HINTS]行に、
pgbench_accountsおよびその他のヒント情報で
PARALLELが受け入れられたことが
示されます。残りの例では、これらの行は、一般的に同じ出力を示すので表示されません(つまり、
trace_hintsは
offにリセットされてい
ます )。
今、 max_parallel_workers_per_gather設定が増加しました:
pgbench_accounts の同じ照会が
PARALLELヒントに並列度指定を指定せずに再度発行され
ます 。計画されている作業者の数は、オプティマイザによって決定されるように4に増加しました。
テーブル pgbench_accountsが変更され、
parallel_workersストレージパラメータが3に設定されました。
注意: parallel_workersパラメータを設定する
ALTER TABLEコマンドのこの形式は、Oracleデータベースと互換性がありません。
parallel_workers設定はPSQLの\ dの+コマンドによって示されています。
場合今、 PARALLELヒントがない平行度が付与され、計画された労働者の得られた数は
parallel_workersパラメータの値です。
PARALLELヒントに
並列度値または DEFAULTを
指定すると 、
parallel_workers設定がオーバーライドされます。
次の例は、 NO_PARALLELヒントを
示しています。
trace_hintsを
onに設定する
と 、
INFO:[HINTS]メッセージは、
NO_PARALLELヒントのためにパラレルスキャンが拒否されたことを
示します。
この章では、 ストアドプロシージャ言語 ( SPL) について説明し ます 。 SPL は 高度なサーバー 用のカスタムプロシージャ、関数、トリガ、およびパッケージを作成するための高度に生産的な手続き型プログラミング言語です 。
この章では、基本的な要素について説明し SPLプログラムの組織の概要を提供する前に
、SPLプログラムを、プロシージャまたは関数を作成するために使用される方法。トリガーは、まだ
SPLを利用しているが、別の議論を正当化するためには十分に異なっている
( トリガーについての 詳細はセクション 4 を 参照 )。パッケージは、次の URLにあるOracle Developerの組み込みパッケージ・ガイド の データベース互換性 について説明してい ます。
SPLプログラムは、次の文字セットを使用して記述されます。
• |
シンボル ( ) + - * / < > = ! 〜 ^ ; : 。 ' @ % 、 " # $ & _ | { } ? [ ] |
注意: SPL プログラムで 操作できるデータ は、データベースエンコーディングでサポートされている文字セットによって決まります。
SPL プログラムで 使用されるキーワードおよびユーザー定義の識別子 は、大文字と小文字を区別しません。したがって、たとえば、文 DBMS_OUTPUT.PUT_LINE( 'Hello World')。 dbms_output.put_line( 'Hello World') と同じ意味を持つと解釈され ます。 または Dbms_Output.Put_Line( 'Hello World'); または DBMS_output.Put_line( 'Hello World')。 。
しかし、文の DBMS_OUTPUT.PUT_LINE( 'HELLO WORLD!'); 出力が生成されます。
識別子 は 、変数、カーソル、ラベル、プログラム、およびパラメータを含む
SPLプログラムの
さまざまな要素を識別するために使用されるユーザー定義の名前です 。有効な識別子の構文ルールは、
SQL言語の識別子と同じです。
修飾子は、 資格の対象となるエンティティの所有者またはコンテキストを指定する名前です。 修飾されたオブジェクトが修飾子の名前として指定され、続いて空白が挿入されないドットが続き、修飾されるオブジェクトの名前の後に空白が挿入されません。この構文を ドット表記法 といいます 。
修飾子 は、オブジェクトの所有者の名前です。 object は 修飾子に 属するエンティティの名前です 。前の修飾子が後続の修飾子とオブジェクトによって識別されるエンティティを所有する場合、一連の修飾を持つことが可能です。
原則として、 SPL文の
構文に名前が表示されている場合でも 、その修飾名も使用できます。通常、修飾された名前は、名前にあいまいさがある場合にのみ使用されます。たとえば、2つの異なるスキーマに属する同じ名前を持つ2つのプロシージャがプログラム内から呼び出された場合、または同じプログラム内の表の列および
SPL変数に同じ名前が使用された場合。
定数 または リテラル は 、数値、文字列、日付などのさまざまな型の値を表す
ために SPLプログラム
で使用できる固定値です 。定数の型は次のとおりです。
SUBTYPE サブタイプ _ 名前 IS タイプ _ 名前 [( 制約 )] [NOT NULL]
{ precision [、 scale ]} | 長さ
type _
nameは、サブタイプの基となる元のタイプの名前を指定します。
type_nameは次のようになります。
精度または位取りをサポートする型
の 制約を定義するに
は、 constraint句を
含めます 。
scaleは、サブタイプの値に許容される小数の桁数を指定します。
lengthは、
CHARACTER 、
VARCHAR 、または
TEXTの基本タイプの値に許可
されている合計
長を指定します。
指定されたサブタイプの列に
NULL値が格納されないように指定するに
は、 NOT NULL句を
含めます 。
拘束されていないサブタイプを作成するには、 SUBTYPEコマンドを
使用して 、新しいサブタイプ名とサブタイプの基になるタイプの名前を指定します。たとえば、次のコマンドは、タイプが
CHARのすべての属性を持つ
addressという名前のサブタイプを作成します。
このコマンドは 、
アドレスサブタイプのすべての属性を共有する
cust _
address という名前のサブタイプを作成し
ます 。
CUSTの値が_
アドレスが NULLではないかもしれないことを指定するには
、NOT NULL句が含まれます。
サブタイプの最大長を定義する文字タイプに基づくサブタイプを作成するときに
、 長さの値を
含めます 。例えば:
数値型の基本型を制約するときは、
精度の 値 (サブタイプの値の最大桁数を指定する)とオプションで
scale (小数点の右側の桁数を指定する)を指定します。例えば:
この例では、 NUMBER型のすべての属性を共有する
acct_balanceという
サブタイプを作成しますが、小数点の左側に3桁、小数点の右側に2桁を超えることはできません。
引数宣言(関数またはプロシージャヘッダー内)は 仮 引数です。関数またはプロシージャに渡される値は、
実際の 引数です。関数またはプロシージャを呼び出すとき、呼び出し側は実際の引数を(0以上)提供します。実際の各引数は、関数またはプロシージャの本体内の値を保持する仮引数に割り当てられます。
%TYPE表記を
使用して、列にアンカーされたサブタイプを宣言する
ことができます。例えば:
このコマンドは、基本タイプが
empテーブルの
empnoカラムのタイプと一致する
emp _
type というサブタイプを作成します。列に基づいたサブタイプは列サイズの制約を共有します。
NOT NULLおよび
CHECK制約は継承されません。
SPL は手続き型のブロック構造言語です。 SPL を使用して作成できるプログラムには 、 プロシージャ 、 関数 、 トリガ 、および パッケージの 4種類が あり ます 。
さらに、SPLを使用してサブプログラムを作成します。 サブプログラムは、プロシージャおよび関数に外観がほぼ同じであるが、プロシージャおよび関数は、個別にデータベースに格納され、他のSPLプログラムによって、またはPSQLから呼び出すことができ
、スタンドアロンのプログラム 、であるという点で異なる
サブプロシージャまたは
サブファンクションを指し。サブプログラムは、作成されたスタンドアロン・プログラム内からのみ呼び出すことができます。
BEGIN -
ENDブロック
内に例外セクションを含めることができます 。例外セクションはキーワード
EXCEPTIONで始まり、それが現れるブロックの終わりまで続きます。ブロック内のステートメントによって例外がスローされた場合、プログラム制御は、例外セクションおよび例外セクションの内容に応じて、スローされた例外が処理される場合とされない場合があります。
プラグマがディレクティブです(
AUTONOMOUS_TRANSACTIONは現在サポートされているプラグマです)。
宣言 は、ブロックに対してローカルな1つ以上の変数、カーソル、タイプ、またはサブプログラムの宣言です。サブプログラム宣言が含まれている場合は、他のすべての変数宣言、カーソル宣言、および型宣言の後に宣言する必要があります。各宣言はセミコロンで終わらなければなりません。キーワード DECLARE の使用は 、ブロックが表示されるコンテキストによって異なります。
ステートメント は、1つ以上の SPL ステートメントです。各ステートメントは、セミコロンで終了する必要があります。 END キーワードで示されるブロックの終わりもセミコロンで終わらなければなりません。
存在する場合、キーワード EXCEPTIONは例外セクションの先頭を示します。
exception_conditionは、1つまたは複数のタイプの例外をテストする条件式です。例外がexception_condition内の
例外の 1つと一致する場合、
WHEN exception_condition節の後の
ステートメントが実行されます。 1つ以上の
WHEN exception_condition句があり、それぞれには
ステートメントが続きます。
注: BEGIN / ENDブロック自体はステートメントとみなされます。従って、ブロックは入れ子にされてもよい。例外セクションには、ネストされたブロックも含まれます。
このタイプのブロックは 匿名ブロック と呼ば れます 。無名ブロックは名前が付けられておらず、データベースに格納されません。ブロックが実行され、アプリケーションバッファから消去されると、ブロックコードがアプリケーションに再入力されない限り、ブロックは再実行できません。
プロシージャは 、個々の
SPLプログラム文として呼び出される、または呼び出される
スタンドアロンの SPLプログラムです。呼び出されると、プロシージャはオプションで入力パラメータの形式で呼び出し元から値を受け取り、オプションで出力パラメータの形式で呼び出し元に値を返します。
PROCEDUREコマンド定義と名称データベースに格納されるスタンドアロン・プロシージャを作成します 。
既存のプロシージャーの定義を更新するには、 CREATE OR REPLACE PROCEDUREを 使用します 。このようにプロシージャの名前または引数の型を変更することはできません(試した場合は、実際には新しいプロシージャを作成することになります)。
OUTパラメーターを使用する場合は、プロシージャーをドロップすることを除いて、
OUTパラメーターのタイプを変更することはできません。
| ROWSは _ 行の 結果
| SET 構成 _ パラメーター
{TO 値 | = 値 | FROM CURRENT}
...]
{IS | AS}
宣言 は、変数、カーソル、型、または副プログラムの宣言です。サブプログラム宣言が含まれている場合は、他のすべての変数宣言、カーソル宣言、および型宣言の後に宣言する必要があります。
ステートメント は SPL プログラムステートメントです( BEGIN - END ブロックには EXCEPTIONセクション
が含まれる場合があります )。
IMMUTABLE は、プロシージャーがデータベースを変更できず、同じ引き数値が与えられたときに常に同じ結果に達することを示します。データベース参照を行わず、引数リストに直接存在しない情報を使用しません。この句をインクルードすると、すべて定数の引数を持つプロシージャの呼び出しをすぐにプロシージャの値に置き換えることができます。
STABLE は、プロシージャーがデータベースを変更できず、単一の表スキャン内で、同じ引き数値に対して同じ結果を一貫して戻しますが、結果がSQLステートメントで変更される可能性があることを示します。これは、データベースルックアップ、パラメータ変数(現在のタイムゾーンなど)に依存するプロシージャの適切な選択です。
VOLATILE は、単一の表スキャン内でもプロシージャ値が変更可能であるため、最適化を実行できないことを示します。副作用のある関数は、呼び出しが最適化されないように、結果がかなり予測可能であっても、揮発性に分類されなければならないことに注意してください。
DETERMINISTICは
IMMUTABLEの同義語です
。 DETERMINISTIC プロシージャーはデータベースを変更することはできず、同じ引き数値が与えられたときに常に同じ結果になります。データベース参照を行わず、引数リストに直接存在しない情報を使用しません。この句をインクルードすると、すべて定数の引数を持つプロシージャの呼び出しをすぐにプロシージャの値に置き換えることができます。
漏れ防止の 手順は、副作用がなく、プロシージャを呼び出すために使用される値に関する情報を明らかにしません。
呼び出される に ヌル INPUT (デフォルト)は、引数の一部が NULLの 場合にプロシージャが正常に呼び出されることを示し ます 。 必要に応じ て NULL 値 をチェックし、 適切に応答するの は作者の責任 です。
戻り値 ヌル に ヌル INPUT または STRICT は 、その引数のいずれか が NULL の場合は必ずプロシージャが NULL を返すことを示し ます 。これらの句が指定されている場合、 NULL 引数 がある場合はプロシージャは実行されません 。代わりに NULL という結果が自動的想定されます。
セキュリティ DEFINER は、プロシージャを作成したユーザーの権限でプロシージャを実行するように指定します。これがデフォルトです。キーワード EXTERNAL はSQL準拠には使用できますが、オプションです。
SECURITY INVOKER 句は、プロシージャがそれを呼び出すユーザの権限で実行されることを示します。キーワード EXTERNAL はSQL準拠には使用できますが、オプションです。
AUTHID DEFINER 句は、 [EXTERNAL]の 同義語です 。 セキュリティ DEFINER 。 AUTHID 句が省略された 場合 、または AUTHID 場合 DEFINER が指定されている場合は、プロシージャ所有者の権限を使用してデータベース・オブジェクトへのアクセス権限が決定されます。
AUTHID CURRENT_USER 句は、 [EXTERNAL]の 同義語です 。 セキュリティ INVOKER 。 AUTHIDの 場合 CURRENT_USER が指定されている場合、プロシージャを実行している現行ユーザーの権限を使用してアクセス権限が決定されます。
PARALLEL 句は、並列逐次走査(パラレルモード)の使用を可能にします。 並列逐次スキャンは、逐次逐次スキャンとは対照的に、クエリ中に複数のワーカーを使用してリレーションを並行してスキャンします。
UNSAFE に 設定すると 、パラレルモードでは実行できません。このようなプロシージャが存在すると、シリアル実行プランが強制されます。これは、 PARALLEL 句が省略された 場合のデフォルト設定です 。
RESTRICTED に 設定する と、プロシージャはパラレルモードで実行できますが、実行はパラレルグループリーダーに制限されます。特定の関係の資格に並行制限があるものがあれば、その関係は並列性のために選択されません。
SAFE に 設定されている場合 、プロシージャは制限なしでパラレルモードで実行できます。
実行 _ コストは、CPU _ オペレータ _ コスト の単位で手順の推定実行コストを与える正の数です 。プロシージャーがセットを戻す場合、これは戻された行あたりのコストです。値を大きくすると、プランナは必要以上に機能を評価しないようにします。
result _ rows は、プランナがプロシージャが返すと予想する行の推定数を示す正の数です。これは、プロシージャがセットを返すと宣言されている場合にのみ許可されます。デフォルトの仮定は1000行です。
SET 設定 _ パラメータ {TO 値 | = 値 | FROM CURRENT}
SET 句は、指定された設定パラメータは、手順が入力されると、指定された値に設定され、その前の値場合の処理手順が終了に復帰させます。 セット から CURRENT は、プロシージャーに入ったときに適用される値として、セッションの現行のパラメーター値を 保管 します。
場合 SET の SET 句は、プロシージャに装着され、その後、効果 同じ変数のプロシージャー内で実行される LOCAL コマンドは、プロシージャーに限定されています。プロシージャ出口で構成パラメータの事前値がリストアされます。 (LOCALなし ) 通常の SET コマンドは 、前の SET のために行うだろう限り、SET句を 上書きします 現在のトランザクションがロールバックされない限り、プロシージャの終了後にそのようなコマンドの効果が持続する LOCAL コマンド。
注: STRICT 、
LEAKPROOF 、
PARALLEL 、
COST 、
ROWSおよび
SETキーワードはAdvanced Serverの拡張機能を提供し、Oracleではサポートされていません。
注意:デフォルトでは、ストアド・プロシージャは
SECURITY DEFINERSとして作成されますが、plpgsqlで書かれたストアド・プロシージャは
SECURITY INVOKERSとして作成されます。
次の例は、プロシージャ宣言で
AUTHID DEFINERおよび
SET句
を使用する方法を示しています。
更新 _ 給与の 手順は(手順の実行中)プロシージャを呼び出している役割に手順を定義したロールの権限を伝えます :
プロシージャの検索パスを public に、ワークメモリを 1MB に設定するに は、 SET 句を 含めます 。他のプロシージャ、関数、およびオブジェクトは、これらの設定の影響を受けません。
この例では、 AUTHID DEFINER 句は、プロシージャ内の文の実行を許可されないロールに一時的に権限を付与します。プロシージャを呼び出すロールに関連付けられた権限を使用するようにサーバーに指示するには、 AUTHID AUTHIDを 持つ DEFINER 句 CURRENT _ USER 節。
注意:渡される実際のパラメータがない場合は、空のパラメータリストを使用してプロシージャを呼び出すことができます。または、開閉括弧を完全に省略することもできます。
注:プロシージャを呼び出す構文は、PSQLまたはEDB * Plusの
EXECコマンドを使用して実行する場合の構文図と同じです。
EXECコマンドの詳細は、
「Oracle Developer Tools and Utilities Guide」の
データベースの互換性を参照してください。
注 :各アプリケーションには、プロシージャーを呼び出す独自の方法があります。たとえば、
Javaアプリケーションでは、アプリケーションプログラミングインターフェイスである
JDBCが使用されます。
ここで、 nameは削除するプロシージャの名前です。
注意:パラメータリストの指定は、オーバーロードされたプロシージャなど、特定の状況下でAdvanced Serverに必要です。 Oracleでは、パラメータ・リストを常に省略する必要があります。
注: IF EXISTS 、
CASCADE 、または
RESTRICTの使用法は、Oracleデータベースとの互換性がありません。これらのオプションの詳細は、
「Oracle Database開発者リファレンスガイド」のデータベース互換性の
DROP PROCEDUREコマンドを参照してください。
関数は 、式として呼び出される スタンドアロンの SPL プログラムです。評価されると、関数は、関数が組み込まれている式で代入された値を返します。関数はオプションで、呼び出しプログラムから入力パラメータの形で値を取ることができます。ファンクション自体が値を返すという事実に加えて、関数は出力パラメータの形式で呼び出し側にオプションで追加の値を返すことがあります。しかし、関数内での出力パラメータの使用は、プログラミングの奨励策ではありません。
機能 コマンド定義と名称データベースに格納されるスタンドアロン関数を 作成 します 。
既存の関数の定義を更新するには、 CREATE OR REPLACE FUNCTIONを 使用します 。この方法で関数の名前や引数の型を変更することはできません(試した場合は、実際には別個の関数を作成することになります)。また、
CREATE OR REPLACE FUNCTIONでは、既存の関数の戻り値の型を変更することはできません。これを行うには、関数を削除して再作成する必要があります。また、
OUTパラメーターを使用する場合は、その関数をドロップすることを除いて、
OUTパラメーターのタイプを変更することはできません。
| ROWSは _ 行の 結果
| SET 構成 _ パラメーター
{TO 値 | = 値 | FROM CURRENT}
...]
{IS | AS}
宣言 は、変数、カーソル、型、または副プログラムの宣言です。サブプログラム宣言が含まれている場合は、他のすべての変数宣言、カーソル宣言、および型宣言の後に宣言する必要があります。
ステートメント は SPL プログラムステートメントです( BEGIN - END ブロックには EXCEPTIONセクション
が含まれる場合があります )。
IMMUTABLE は、関数
がデータベースを変更できず、同じ引数値が与えられたときに常に同じ結果に達することを示します。データベース参照を行わず、引数リストに直接存在しない情報を使用しません。この句を含める と、すべて定数の引数を持つ関数の
呼び出しを すぐに関数の
値 に置き換えることができ ます。
STABLE は、関数
がデータベースを変更できない ことを示し 、単一の表スキャン内では、同じ引き数値に対して同じ結果を一貫して戻しますが、結果はSQLステートメント全体で変更される可能性があることを示します。これは、 データベースルックアップ、パラメータ変数(現在のタイムゾーンなど)に依存する関数
の適切な選択です 。
VOLATILE は 、単一のテーブル・スキャン内でも関数
値が変更できることを 示している ため、最適化は行えません。副作用のある関数は、呼び出しが最適化されないように、結果がかなり予測可能であっても、揮発性に分類されなければならないことに注意してください。
DETERMINISTICは
IMMUTABLEの同義語です。
DETERMINISTIC関数
はデータベースを変更することはできず、同じ引き数を指定すると常に同じ結果になります。データベース参照を行わず、引数リストに直接存在しない情報を使用しません。この句を含めると、すべて定数の引数を持つ関数の呼び出しをすぐに関数の値に置き換えることができます。
漏れ止め 関数には副作用がなく、関数の呼び出しに使用された値に関する情報は表示されません 。
呼び出される に ヌル INPUT (デフォルト)は、引数の一部が NULLの 場合にプロシージャが正常に呼び出されることを示し ます 。 必要に応じ て NULL 値 をチェックし、 適切に応答するの は作者の責任 です。
戻り値 ヌル に ヌル INPUT または STRICT は 、その引数のいずれか が NULL の場合は必ずプロシージャが NULL を返すことを示し ます 。これらの句が指定されている場合、 NULL 引数 がある場合はプロシージャは実行されません 。代わりに NULL という結果が自動的想定されます。
セキュリティ DEFINER は、関数を作成したユーザーの権限で関数が実行されることを指定します。これがデフォルトです。キーワード EXTERNAL はSQL準拠には使用できますが、オプションです。
SECURITY INVOKER 句は、関数を呼び出すユーザーの権限で関数が実行されることを示します。キーワード EXTERNAL はSQL準拠には使用できますが、オプションです。
AUTHID DEFINER 句は、 [EXTERNAL]の 同義語です 。 セキュリティ DEFINER 。 AUTHID 句が省略された 場合 、または AUTHID 場合 DEFINER が指定されている場合、関数所有者の権限を使用してデータベース・オブジェクトへのアクセス権限が決定されます。
AUTHID CURRENT_USER 句は、 [EXTERNAL]の 同義語です 。 セキュリティ INVOKER 。 AUTHIDの 場合 CURRENT_USER が指定されている場合、その関数を実行している現行ユーザーの権限を使用してアクセス特権が判別されます。
PARALLEL 句は、並列逐次走査(パラレルモード)の使用を可能にします。 並列逐次スキャンは、逐次逐次スキャンとは対照的に、クエリ中に複数のワーカーを使用してリレーションを並行してスキャンします。
UNSAFE に 設定すると 、パラレルモードでは実行できません。このような関数がSQL文に存在すると、実行計画が強制的に実行されます。これは、 PARALLEL 句が省略された 場合のデフォルト設定です 。
RESTRICTED に 設定すると 、この関数はパラレルモードで実行できますが、実行はパラレルグループリーダーに制限されます。特定の関係の資格に並行制限があるものがあれば、その関係は並列性のために選択されません。
SAFE に 設定すると 、パラレルモードで機能を制限なく実行できます。
実行 _ コスト は、 CPUの _ 演算子 _ コストの 単位で 、関数の
推定実行コストを示す正の数 です。機能
の場合 セットを返します。返される行あたりのコストです。値を大きくすると、プランナは関数の
評価を回避しようとします
必要以上に頻繁に。
result _ rows は、プランナが関数
を予想する行の推定数を示す正の数です。
復帰する。これは、関数
セットを返すように宣言されています。デフォルトの仮定は1000行です。
SET 設定 _ パラメータ {TO 値 | = 値 | FROM CURRENT}
SET 句は、場合関数指定された構成パラメータが指定された値に設定させます 関数が入力されると、その値に戻されます 終了します。 セット から CURRENT は、セッションの現在のパラメータ値を、関数の実行時に適用される値として保存します 入力されます。
場合は SET 句は、関数
、SETの後、効果 に取り付けられています。 関数
内で実行される LOCAL コマンド 同じ変数に対しては関数に
制限されています
。構成パラメータの以前の値が関数
で復元される 出口。 (LOCALなし ) 通常の SET コマンドは 、前の SET のために行うだろう限り、SET句を 上書きします 現在のトランザクションがロールバックされない限り、プロシージャの終了後にそのようなコマンドの効果が持続する LOCAL コマンド。
注: STRICT 、
LEAKPROOF 、
PARALLEL 、
COST 、
ROWSおよび
SETキーワードはAdvanced Serverの拡張機能を提供し、Oracleではサポートされていません。
渡された入力パラメーターが NULLの 場合 、サーバーに NULL を戻すように指示 する STRICT キーワードを 組み込み ます 。 NULL 値 が渡された 場合 、この関数は実行されません。
DEPT _ 給与の 関数は、関数を呼び出している役割の権限で実行されます。 現在のユーザーに 、 (従業員の給与を表示 するために) emp 表を 照会する SELECT ステートメント を実行するための十分な特権がない場合、 関数はエラーを報告します。関数を定義したロールに関連付けられた権限を使用するようにサーバーに指示するには、 AUTHID AUTHIDを 持つ CURRENT _ USER 節 DEFINER 句。
name は関数の名前です。 parameters は実際のパラメータのリストです。
注意:渡される実際のパラメータがない場合は、空のパラメータリストを使用して関数を呼び出すことも、開かれたかっこを完全に省略することもできます。
注意:パラメータリストの指定は、オーバーロードされた関数など、特定の状況下でAdvanced Serverで必要です。 Oracleでは、パラメータ・リストを常に省略する必要があります。
注: IF EXISTS 、
CASCADE 、または
RESTRICTの使用法は、Oracleデータベースとの互換性がありません。これらのオプションの詳細は、
「Oracle Database開発者リファレンスガイド」のデータベース互換性の
DROP FUNCTIONコマンドを参照してください。
name は、仮パラメータに割り当てられた識別子です。 INを 指定すると、 IN はプロシージャーまたは関数への入力データを受け取るためのパラメーターを定義します。 IN パラメータは、デフォルト値に初期化することができます。指定すると、 OUT はプロシージャまたは関数からデータを戻すためのパラメータを定義します。 IN OUTを 指定すると、 入力と出力の両方にパラメーターを使用できます。 IN のすべて 、OUT、および OUTを 省略している 場合 、パラメータ に は、それが デフォルトで の ように定義されていたかのように機能し ます。パラメータが IN 、 OUT 、または IN OUTの いずれであるか は、パラメータの モード と呼ばれ ます 。 data_typeは、パラメータのデータ型を定義します。
valueは、コールで実際のパラメータが指定されていない場合、呼び出されたプログラムの
INパラメータに割り当てられたデフォルト値です。
この例では、 p_deptno は IN 仮パラメータであり、 p_empno および p_ename は IN OUT 仮パラメータであり、 p_job 、 p_hiredate および p_sal は OUT 仮パラメータです。
注: 前の例では、 VARCHAR2 パラメーター に最大長が指定されて おらず、 NUMBERパラメーターに
精度と位取りが指定されていませんでした 。パラメータの宣言に長さ、精度、スケールなどの制約を指定することはできません。これらの制約は、プロシージャまたは関数の呼び出し時に使用される実際のパラメータから自動的に継承されます。
emp_query手順は、それを実際のパラメータを渡し、他のプログラムから呼び出すことができます。以下は、 emp_queryを呼び出す別のSPLプログラムの例です。
この例では、 v_deptno 、 v_empno 、 v_ename 、 v_job 、 v_hiredate 、および v_salが実際のパラメータです。
関数またはプロシージャーにパラメーターを渡すとき
は、 定位置または
名前付きのパラメーター表記
を使用できます。位置指定表記を使用してパラメータを指定する場合、宣言されている順序でパラメータをリストする必要があります。名前付き表記でパラメータを指定すると、パラメータの順序は重要ではありません。
表に示すように、 IN 仮パラメータは、デフォルト値で明示的に初期化されない限り、呼び出される実際のパラメータに初期化されます。 IN パラメータが呼ばれるプログラム内で参照することができる、しかし、と呼ばれるプログラムは、IN パラメータ に新しい値を割り当てることはできません 。制御が呼び出し元のプログラムに戻った後、実際のパラメータには、呼び出し前に設定されたのと同じ値が常に含まれます。
OUT仮パラメータは、それが呼び出されると、実際のパラメータに初期化されます。呼び出されるプログラムは、仮パラメータに新しい値を参照して割り当てることができます。呼び出されたプログラムが例外なく終了した場合、実際のパラメーターは仮パラメーターで最後に設定された値をとります。処理された例外が発生した場合、実パラメータの値は仮パラメータに割り当てられた最後の値をとります。未処理の例外が発生した場合、実際のパラメータの値は呼び出し前の状態のままです。
INパラメータ
と同様に、
IN OUT仮パラメータは、呼び出された実際のパラメータに初期化されます。
OUTパラメータと同様に、
IN OUT仮パラメータは被呼び出しプログラムによって変更可能であり、呼び出されたプログラムが例外なく終了する場合、仮パラメータの最後の値が呼び出しプログラムの実際のパラメータに渡されます。処理された例外が発生した場合、実パラメータの値は仮パラメータに割り当てられた最後の値をとります。未処理の例外が発生した場合、実際のパラメータの値は呼び出し前の状態のままです。
name は、パラメータに割り当てられた識別子です。
expr は、パラメータに割り当てられたデフォルト値です。 DEFAULT 句 を指定しない場合 、呼び出し元はパラメータの値を指定する必要があります。
宣言部で指定されたプロシージャの句は、そのブロックにローカルサブプロシージャを定義し、名前。
ブロック という用語は、オプションの宣言セクション、必須の実行可能セクション、およびオプションの例外セクションで構成されるSPLブロック構造を指します。ブロックは、スタンドアロンのプロシージャおよびファンクション、匿名ブロック、サブプログラム、トリガ、パッケージおよびオブジェクト型メソッドの構造です。
識別子がブロックに対してローカルである という句 は 、識別子(つまり、変数、カーソル、タイプ、またはサブプログラム)がそのブロックの宣言セクション内で宣言されていることを示します。したがって、実行可能セクション内のSPLコードとオプションそのブロックの例外セクション。
宣言 は、変数、カーソル、型、または副プログラムの宣言です。サブプログラム宣言が含まれている場合は、他のすべての変数宣言、カーソル宣言、および型宣言の後に宣言する必要があります。
ステートメント は SPL プログラムステートメントです( BEGIN - END ブロックには EXCEPTIONセクション
が含まれる場合があります )。
宣言部で指定された機能の句は、そのブロックにローカルサブファンクションを定義し、名前。
ブロック という用語は、オプションの宣言セクション、必須の実行可能セクション、およびオプションの例外セクションで構成されるSPLブロック構造を指します。ブロックは、スタンドアロンのプロシージャおよびファンクション、匿名ブロック、サブプログラム、トリガ、パッケージおよびオブジェクト型メソッドの構造です。
識別子がブロックに対してローカルである という句 は 、識別子(つまり、変数、カーソル、タイプ、またはサブプログラム)がそのブロックの宣言セクション内で宣言されていることを示します。したがって、実行可能セクション内のSPLコードとオプションそのブロックの例外セクション。
宣言 は、変数、カーソル、型、または副プログラムの宣言です。サブプログラム宣言が含まれている場合は、他のすべての変数宣言、カーソル宣言、および型宣言の後に宣言する必要があります。
ステートメント は SPL プログラムステートメントです( BEGIN - END ブロックには EXCEPTIONセクション
が含まれる場合があります )。
• |
ブロックは、オプションの宣言セクション、必須の実行部、およびオプションの例外部からなる基本的なSPL構造です。ブロックは、スタンドアロンのプロシージャおよび関数プログラム、匿名ブロック、トリガ、パッケージ、サブプロシージャおよびサブファンクションを実装します。 |
• |
親ブロックは別のブロック( 子ブロック )の宣言が含まれています。 |
• |
降順ブロックは、特定の親ブロックから開始して子関係を形成するブロックの集合です。 |
• |
祖先ブロックは、与えられた子ブロックから始まる親の関係を形成するブロックの集合である。 |
• |
レベルが最も高い、先祖ブロックから所定ブロックの序数です。たとえば、スタンドアロン・プロシージャでは、このプロシージャの宣言セクション内で宣言されたサブプログラムはすべて同じレベルにあります(たとえば、レベル1と呼びます)。スタンドアロン・プロシージャで宣言されたサブプログラムの宣言セクション内の追加サブプログラムは、レベルはレベル2です。
|
• |
兄弟ブロックは (つまり、それらはすべてローカルに同じブロック内で宣言されている)同じ親ブロックを持つブロックのセットです。兄弟ブロックも常に同じレベルにあります。 |
指定された場合は、 qualifier_nは subprogはその宣言セクションで宣言されたサブプログラムです。修飾子の前のリストには、最大連続した経路
qualifier_1する
qualifier_nから階層内に存在しなければなりません。
qualifier_1は、パス内の任意の祖先サブプログラムでも、次のいずれかです。
• |
宣言セクションが存在する場合 は DECLARE キーワードの前に、 宣言セクションがない場合 は BEGIN キーワードの 前に 含まれる無名ブロックラベル 。 |
注意: qualifier_1はスキーマ名ではない可能性があります。それ以外の場合は、サブプログラムの起動時にエラーがスローされます。このAdvanced Serverの制限は、スキーマ名を修飾子として使用できるOracleデータベースとは互換性がありません。
注意:サブプログラム起動のためのAdvanced Server検索アルゴリズムは、Oracleデータベースとあまり互換性がありません。 Oracleの場合、最初の修飾子(
qualifier_1 )の最初の一致が検索されます。このような一致が見つかると、残りのすべての修飾子、サブプログラム名、サブプログラムのタイプ、および呼び出しの引数が、一致する第1修飾子が見つかる階層コンテンツと一致しなければなりません。そうでない場合はエラーがスローされます。 Advanced Serverの場合、呼び出しのすべての修飾子、サブプログラム名、およびサブプログラムの型が階層の内容と一致しない限り、一致が見つかりません。このような完全一致が最初に見つからない場合、Advanced Serverは検索を続けて階層を上に進めます。
呼び出し注意 level_2aのまたは等価的手順
level_1b内から
level_1a.level_2aは、このコールがエラーをもたらすようにコメントアウトされています。兄弟ブロック(
level_1a )の子孫サブプログラム(
level_2a )を呼び出すことはできません。
次の例では、プロシージャプロシージャ
level_3bの祖先が正常に起動されている手順
level_1bの兄弟である
level_1a、。
これは 、呼び出しの前にSPLコードに
前方宣言を
挿入することによって実現されます。前方宣言は、サブプロシージャーまたはサブ関数名、仮パラメーター、およびそれがサブ関数の場合の戻りタイプの指定です。
サブファンクション test_maxは前方宣言が匿名ブロック宣言セクションの冒頭に
add_oneために実装されているサブプログラム、のいずれかのために必要とされるように、また、サブ関数
test_max呼び出すサブファンクション
add_oneを呼び出します。
たとえば、 CHARまたは
CHARACTER として指定できる固定長文字データ型があります 。
CHAR VARYING 、
CHARACTER VARYING 、
VARCHAR 、または
VARCHAR2として指定できる可変長文字データ型があります。整数の
場合 、
BINARY_INTEGER 、
PLS_INTEGER 、および
INTEGERデータ型があります。数値の場合は、
NUMBER 、
NUMERIC 、
DEC 、および
DECIMALのデータ型があります。
PSQL \ dコマンドを使用してテーブル定義を表示すると、[Type]列には、テーブル定義のデータ型に基づいて各列に内部的に割り当てられたデータ型が表示されます。
注意:仮パラメータ・データ型に基づくオーバーロード・ルールは、Oracleデータベースと互換性がありません。通常、Advanced Serverルールは柔軟性があり、Advanced ServerではOracleデータベースでプロシージャまたはファンクションを作成しようとするとエラーが発生する特定の組み合わせが許可されます。
注意:サブプログラムのシグネチャに仮パラメータが含まれている場合は、サブプログラムのローカル変数と同じ方法でアクセスできます。この項では、サブプログラムの変数に関するすべての説明が、サブプログラムの仮パラメータにも適用されます。
指定した場合、 修飾子は
変数が宣言セクションで宣言されているサブプログラムまたはラベル付き匿名ブロック
です (つまり、ローカル変数です)。
注: Advanced Serverでは、2つの修飾子が許可される環境は1つだけです。このシナリオは、参照を次の形式で指定できるパッケージのパブリック変数にアクセスするためのものです。
注意:変数にアクセスするためのAdvanced Serverプロセスは、Oracleデータベースと互換性がありません。 Oracleでは、任意の数の修飾子を指定することができ、検索は、サブプログラムを呼び出すためのOracleの一致アルゴリズムと同様の方法で、最初の修飾子の最初の一致に基づいて行われます。
次の例は、オブジェクト型メソッド display_empにレコード型
emp_typとサブ
プロシージャ emp_sal_queryが含まれて
いるオブジェクト型 です 。
emp_sal_queryにローカルに宣言されたレコード変数
r_empは、親ブロック
display_empで宣言されたレコードタイプ
emp_typにアクセスすることが可能です。
spl.max _
error _
countは、SPLコードで指定された数のエラーが発生した場合、またはSQLコードでエラーが発生した場合に、サーバーに解析を停止するように指示します。
spl.maxのデフォルト値は、_ _
エラー カウントは 10です。最大値は
1000です。
spl.max_error_countを
1に設定すると、SPLコードまたはSQLコードの最初のエラーが発生したときに、サーバーは解析を停止するように指示されます。
あなたは使用することができ 、あなたの現在のセッションの
spl.max _ _
エラー カウンタの値を指定
するには
、SETコマンドを使用します。構文は次のとおりです。
どこ NUMBER_OF_ERRORSは 、サーバがコンパイルプロセスを停止する前に発生することがありSPLエラーの数を指定します。例えば:
次の例では 、前の例に
SELECT文が
追加されています。
SELECT文のエラーは、次に続く他のエラーをマスクします。
SPLプログラム(ファンクション、プロシージャまたはパッケージ)は、次のいずれかに該当する場合にのみ実行を開始することができます:
• |
現在のユーザは、そのような特権を持つグループのメンバであるため、 SPLプログラムに対する EXECUTE特権を 継承します。 |
Advanced Serverで
SPLプログラムが作成される
たびに 、
EXECUTE特権がデフォルトで
PUBLICグループに自動的に付与されるため、どのユーザーもすぐにプログラムを実行できます。
プログラムに対する
明示的な EXECUTE特権を個々のユーザーまたはグループに付与できます。
これで、ユーザー johnは
list_empプログラムを実行できます。このセクションの冒頭に記載されている条件のいずれかを満たしていないユーザーは、他のユーザーにアクセスできません。
SPLプログラム
内のデータベースオブジェクトは 、修飾名または非修飾名で参照されることがあります。修飾名は
スキーマの形式です
。 nameここで、
schemaは、識別子、
名前のデータベースオブジェクトが存在するスキーマの名前です。修飾されていない名前には「
スキーマ 」はありません
。 "部分。修飾された名前への参照が行われるとき、指定されたスキーマ内に存在するか存在しないかは、正確にどのデータベースオブジェクトが意図されているかについて全く曖昧さがありません。
$ユーザ次いで、第一
、EnterpriseDBのを -上記検索パスでは、上記セッションの現在のユーザーが
EnterpriseDBのであれば、非修飾データベース・オブジェクトがこの順に次のスキーマで検索されるように、現在のユーザを指す一般的なプレースホルダ
公衆
注意:検索パスの概念は、
Oracleデータベースと互換性がありません。修飾されていない参照の場合、
Oracleは現在のユーザーのスキーマ内で、指定されたデータベース・オブジェクトを探します。
Oracleでは、
Advanced Serverではユーザーとスキーマは同じエンティティであり、ユーザーとスキーマは2つの異なるオブジェクトであることに注意してください。
いったん SPLプログラムが実行を開始、現在のユーザーを確保するために、チェックのプログラムの結果の中からデータベースオブジェクトにアクセスしようとすると、参照されるオブジェクトに対する意図したアクションを実行する権限を持っています。
GRANTおよび
REVOKEコマンドを使用して、データベース・オブジェクトに対する権限が付与され、削除されます。現在のユーザーがデータベースオブジェクトに対する不正アクセスを試みると、プログラムは例外をスローします。セクション
を参照してください。 3.5.7例外処理
の詳細については、
を 。
場合 SPLプログラムが実行を開始しようとしている、決意は、このプロセスに関連するものをユーザが行われます。このユーザーは、
現在のユーザーと呼ばれ
ます 。現在のユーザーのデータベース・オブジェクト権限は、プログラムで参照されるデータベース・オブジェクトへのアクセスを許可するかどうかを決定するために使用されます。プログラムが呼び出されたときに有効な現在の一般的な検索パスは、未修飾のオブジェクト参照を解決するために使用されます。
現在のユーザの選択は、 SPLプログラムが定義者の権利または実行者の権利で作成さ
れたかどうかによって影響されます。
AUTHID節はその選択を決定します。
AUTHID DEFINER節の出現により、プログラム定義者の権利が与え
られます。
AUTHID句が省略されている場合のこれもデフォルトです。
AUTHID CURRENT_USER句を使用すると、プログラムの呼び出し元の権限が与えられます。両者の違いは次のようにまとめられています。
• |
プログラムに 定義者の権利がある場合、プログラムの実行開始時にプログラムの所有者が現在のユーザーになります。プログラム所有者のデータベースオブジェクト権限は、参照されたオブジェクトへのアクセスが許可されているかどうかを判断するために使用されます。定義者の権利プログラムでは、どのユーザーが実際にプログラムを呼び出したかは関係ありません。 |
• |
プログラムに 呼び出し元の権限 がある場合、プログラムが呼び出された時点の現在のユーザーは、プログラムが実行されている間は現在のユーザーのままです(ただし、必ずしも呼び出されるサブプログラム内ではありません -起動者の権利プログラムが呼び出されると、セッションがSET ROLEコマンドを使用して開始された後に現在のユーザーを変更することは可能ですが、通常、現在のユーザーはセッションを開始したユーザー(データベース接続)です。呼び出し元の権利プログラムでは、どのユーザーがプログラムを実際に所有しているかは関係ありません。 |
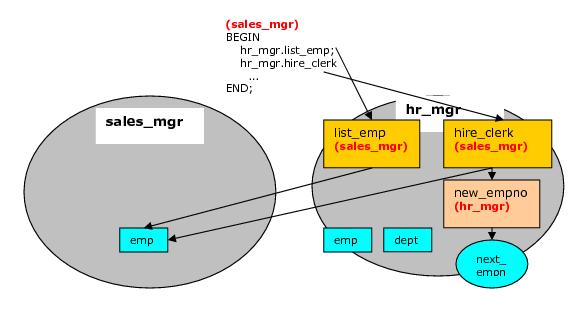
この例では、
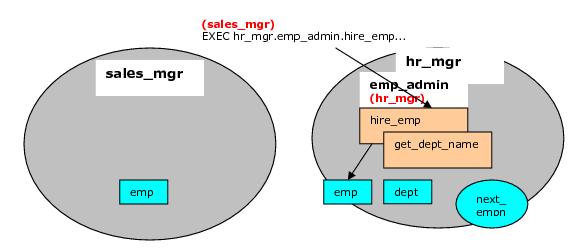
プロシージャ list_emp 、関数
hire_clerk 、およびパッケージ
emp_adminが使用されます。サンプルアプリケーションのインストール時に付与されるすべてのデフォルト権限は削除され、この例ではより安全な環境を提供するために明示的に再付与されます。
プログラム list_empと
hire_clerkは、デフォルトの定義者権限から呼び出し元の権限に変更されます。
sales_mgrがこれらのプログラムを実行すると、
sales_mgrの検索パスと権限が名前解決と権限チェックに使用されるため、
sales_mgrのスキーマ内の
empテーブルが
処理されることが示されます。
emp_adminパッケージの
get_dept_nameおよび
hire_emp プログラムは、
sales_mgrによって実行され
ます 。
hr_mgrが定義者権限を使用している
EMP_ADMINパッケージの所有者であり、この場合には
、hr_mgrのスキーマ内の
DEPTテーブルと
EMPテーブルがアクセスされます。デフォルトの検索パスは
$ userプレースホルダで有効なので、
ユーザと一致するスキーマ(この場合は
hr_mgr )を使用してテーブルを検索します。
ユーザー enterprisedb として 、
hrデータベースを作成します。
サブセットを作成 sales_mgrのスキーマに
sales_mgrが所有する
emp表を。
上記の例では、 スキーマコマンド
ON GRANTの使用は S
emp表 「hr_mgrのコピーを作成するためのスキーマ
」hr_mgrに
sales_mgrアクセスを可能にするために与えられています。この手順は
Advanced Serverでは必須です
.Oracleには、ユーザーとは異なるスキーマの概念がないため
、Oracleデータベースとの互換性はありません。
ユーザー hrhmgr として接続しているときに、
AUTHID CURRENT_USER句を
list_empプログラムに追加し、
Advanced Serverに再保存し
ます 。この手順を実行するときは、
hr_mgrとしてログオンしていることを確認して
ください 。そうしないと、変更されたプログラムが
hr_mgrのスキーマではなく
パブリックスキーマに
書き込まれることがあります。
ユーザー hr_mgr として接続しているときに、
AUTHID CURRENT_USER句を
hire_clerkプログラムに追加します。
また、後に BEGIN文で、完全に
new_empno機能は
hr_mgrスキーマに解決に
hire_clerk関数呼び出しを確保するために
hr_mgr.new_empnoし
、new_empno、参照を修飾。
ユーザーとして接続し、 hr_mgr、sales_mgrは list_emp手順 、hire_clerk機能、および
EMP_ADMINパッケージを実行できるように、必要な権限を付与します。
sales_mgrがアクセスできるデータオブジェクトは、
sales_mgrスキーマの
empテーブル
だけです。
sales_mgrには、
hr_mgrスキーマ内の表に対する権限はありません。
sales_mgrの
empテーブル
から選択すると 、このテーブルで更新が行われたことが示されます。
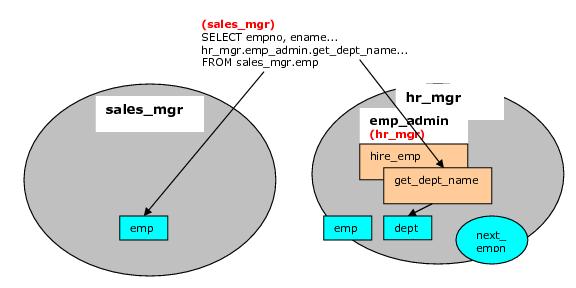
次の図は、ことを示して SELECTコマンドリファレンス
sales_mgrスキーマの
EMP表を、しかし
EMP_ADMINパッケージは、定義者権限を持ち
、hr_mgrが所有しているので
、EMP_ADMINパッケージに
GET_DEPT_NAME機能によって参照
DEPT表は
hr_mgrスキーマからです。
$ userプレースホルダを
使用するデフォルトの検索パス設定では、
hr_mgrスキーマの
deptテーブルに対するユーザー
hr_mgrのアクセスが解決されます。
この図は、ことを示して EMP_ADMINの定義者権限パッケージの
hire_emp手順は
hr_mgrのオブジェクト権限が使用されているので
、hr_mgrに属する
emp表を更新し
、$ユーザーのプレースホルダーでの設定デフォルトの検索パスは
hr_mgrのスキーマに解決されます。
今すぐユーザー hr_mgr として接続します 。次の
SELECTコマンドは、
emp_adminパッケージに定義者権限があり、
hr_mgrが
emp_adminの所有者であるため、新しい従業員が
hr_mgrの
empテーブルに追加されたことを確認します。
SPL はブロック構造言語です。ブロックに表示される最初のセクションは宣言です。宣言には 、ブロックに含まれる SPL ステートメント で使用できる変数、カーソル、およびその他のタイプの定義が 含まれています。
[ := 式 ]を指定すると、ブロックが入力されたときに変数に割り当てられた初期値を指定します。この節が指定されていない場合、変数は SQL NULL値に
初期化されます。
多くの場合、変数は データベース内のテーブルの値を保持するために使用される SPL プログラムで 宣言され ます。テーブル列と SPL変数
との間の互換性を保証するためには、2つのデータ型が同じである必要があります。
特定の列データ型を変数宣言にコーディングする代わりに、列属性 %TYPEを代わりに使用できます。ドット表記の修飾列名または事前に宣言された変数の名前を
%TYPEの接頭辞として指定する必要があります。
%TYPEにプレフィックスされた列または変数のデータ型は、宣言されている変数に割り当てられます。指定された列または変数のデータ型が変更された場合、宣言コードを変更することなく、新しいデータ型が変数に関連付けられます。
注意: %TYPE 属性は、同様に仮パラメータの宣言で使用することができます。
name は、宣言されている変数または仮パラメータに割り当てられた識別子です。 column は、 表 または ビュー 内の列の名前です 。 variable は、nameで指定された変数の前に宣言された変数の 名前です。
注:変数は、
NOT NULL句または
DEFAULT句の列に指定されているような列の他の属性を継承しません。
次の例では 、従業員番号を使用し
て empテーブルを
照会し 、従業員のデータを表示し、従業員が属する部門の全従業員の平均給与を見つけ、選択した従業員の給与と部門平均を比較します。
注: p_empno は、 %TYPE を使用して定義された仮パラメータの例を示しています 。
v_avgsal は、 %TYPE の使用法を示し、テーブル列の代わりに別の変数を参照します。
%TYPE 属性は、列のデータ型に依存して変数を作成する簡単な方法を提供します。 %ROWTYPE属性を使用すると、特定の表のすべての列に対応するフィールドを含むレコードを定義できます。各フィールドは、対応する列のデータ型を取ります。レコードのフィールドは、 NOT NULL句またはDEFAULT句で指定されたような列の他の属性を継承しません 。
レコードが命名され、フィールドのコレクションを命じました。 フィールドは変数に似ています。識別子とデータ型を持ちますが、レコードに属しているという追加の特性があり、レコード名を修飾子としてドット表記法を使用して参照する必要があります。
あなたは使用することができ 、レコードを宣言する
%ROWTYPE属性を。
%ROWTYPE属性の前には表名が付いています。名前付きテーブルの各列は、列と同じデータ型を持つレコード内の同じ名前のフィールドを定義します。
レコード は レコードに 割り当てられた識別子です。 tableは、列がレコード内のフィールドを定義するテーブル(またはビュー)の名前です。次の例では、前のセクションから
emp_sal_query手順は
EMP内の列の個々の変数を宣言する代わり
r_empという名前のレコードを作成するため
のemp%のROWTYPEを使用するように変更することができる方法を示しています。
TYPE文はレコード型の定義を作成するために使用されるレコードです 。 レコードタイプは、1つ以上の識別子とそれに対応するデータタイプで構成されるレコードの定義です。レコードタイプはそれ自体でデータを操作することはできません。
TYPE rec _ type IS RECORD( フィールド )
where fieldsは、次の形式の1つ以上のフィールド定義のカンマ区切りリストです。
フィールド _ 名前 data_type [NOT NULL] [{:= | DEFAULT} デフォルト _ 値 ]
DEFAULT句は、対応するフィールドのデフォルトデータ値を割り当てます。デフォルトの式のデータ型は、列のデータ型と一致する必要があります。デフォルトを指定しない場合、デフォルトはNULLです。
レコード変数または簡単に言えば、 レコードは 、レコード型のインスタンスです。レコードはレコードタイプから宣言されます。フィールド名や型などのレコードのプロパティは、レコードタイプから継承されます。
record は、レコード変数に割り当てられた識別子です。 rectypeは、以前に定義されたレコードタイプの識別子です。一度宣言すると、レコードを使用してデータを保持できます。
レコード は以前に宣言されたレコード変数であり、 フィールド は レコードが定義さ
れているレコードタイプに属するフィールドの識別子です 。
ユーザ定義レコード型とレコード変数を使用して、この時間- emp_sal_queryが再び変更されます。
NULL 文は実行文は IF-THEN-ELSE文の枝のような必要とされるプレースホルダとして機能することができます。
variable は、以前に宣言された変数、 OUT 仮パラメータ、または IN OUT 仮パラメータの 識別子です 。
expression は単一の値を生成する式です。式によって生成される値は、 変数 と互換性のあるデータ型でなければなりません 。
SELECT INTO ステートメントは、SQL の SPL の変動 であります SELECTコマンド、違いは:
• |
その SELECT INTOは、結果を変数またはレコードに代入して SPLプログラムステートメントで使用できるように設計されています。 |
上記以外の WHERE 、
ORDER BY 、
GROUP BY 、
HAVINGなど
の SELECTコマンドの
すべての句は、 SELECT INTOに対して有効です。
SELECT INTOの 2つのバリエーションは次のとおりです。
target はカンマで区切られた単純変数のリストです。 select_expressions と残りの文は SELECT コマンド と同じ です。選択された値は、データ型、数値、および順序がターゲットの構造と正確に一致する必要があります。また、実行時エラーが発生します。
注意: どちらの場合も、行が返されないか、複数の行が返される場合、 SPLは例外をスローします。
注:コレクションに戻される複数の行の結果セットを許可する
BULK COLLECT節を使用する
SELECT INTOのバリエーションがあります。
SELECT INTO文に
BULK COLLECT句を使用する方法の詳細は、第
3.12.4.1項を参照してください。
EXCEPTIONブロック
の WHEN NO_DATA_FOUND節を
使用して 、割り当てが成功したかどうか(つまり、クエリによって少なくとも1つの行が返されたかどうか)を判断できます。
このバージョンの emp_sal_queryプロシージャは、結果セットをレコードに戻す
SELECT INTOのバリエーションを使用します。
WHEN NO_DATA_FOUND条件式を含む
EXCEPTIONブロックの追加にも注意してください。
SELECT INTOを 伴う EXCEPTION セクション で使用するもう1つの条件節 は、 TOO_MANY_ROWS 例外です。 SELECT INTO 文 によって複数の行が選択されている場合 、 SPL によって例外がスローされます。
次のブロックを実行すると、指定された部門に従業員が多数いるため
、 TOO_MANY_ROWS例外がスローされます。
SQL 言語 で利用可能な INSERT コマンドは 、SPLプログラムで使用することができます 。
で表現式が
SQLの INSERTコマンドで許可されている場所
SPL言語を使用することができます。したがって、
SPL変数およびパラメータを使用して、挿入操作に値を供給することができます。
注: INSERTコマンドは
FORALLステートメントに含めることができます。
FORALL文を使用すると、1つまたは複数のコレクションで指定された値から複数の行を
INSERTコマンドで挿入できます
。 FORALL ステートメントの 詳細については、 3.12.3 を 参照してください 。
SQL 言語 で利用可能 UPDATE コマンドは 、SPLプログラムで使用することができます 。
SQL UPDATEコマンドで式が許可されている場合は
、 SPL言語
の式を使用でき
ます 。したがって、
SPL変数およびパラメータを使用して、更新操作に値を供給することができます。
行が FALSE さもなければ 、更新された場合は 、SQL%FOUND 条件式は TRUEを 返し 。 SQL%FOUNDと他の同様の式
については、 3.4.8 項を参照してください 。
注: UPDATEコマンドは、
FORALLステートメントに組み込むことができます。
FORALL文を使用すると、1つ以上の
コレクションで指定された値から1つの
UPDATEコマンドで複数の行を更新できます
。セクションを参照してください。 3.12.3を FORALL 文 の詳細については 。
(SQL 言語 で利用可能 )DELETE コマンドは 、SPLプログラムで使用することができます 。
で表現式が
SQLコマンドを
DELETEに許可されている場所
SPL言語を使用することができます。したがって、
SPL変数およびパラメータを使用して、削除操作に値を供給することができます。
SQL%は、 行が そうでなければ FALSE 削除された場合 、条件式は TRUEを 返し 見出しました 。 SQL%FOUNDと他の同様の式
については、 3.4.8 項を参照してください 。
注: DELETEコマンドは、
FORALLステートメントに組み込むことができます。
FORALL文では、1つ以上の
コレクションで指定された値から複数の行を削除する単一の
DELETEコマンドを使用できます
。 3.12.3 項を参照してください 。 FORALLステートメントの詳細については、
INSERT、UPDATE、および DELETE コマンド は RETURNING INTO句 オプションが付加されてもよいです 。 この句を使用すると、 SPL プログラムは INSERT 、 UPDATE または DELETEコマンドの結果から新たに追加、変更、または削除された値を取得 できます 。
insert は有効な INSERT コマンドです。 update は有効な UPDATE コマンドです。 delete は有効な DELETE コマンドです。 *が 指定されている 場合 、INSERTの影響を受けた行の値 、UPDATE、またはDELETE コマンド は INTO キーワード の右側にレコードまたはフィールドへの割り当てのために利用可能にされます 。 (*の使用は、Advanced Serverの 拡張機能 であり 、Oracleデータベースと互換性が ない ことに注意してください 。)expr_1、expr_2 ... INSERT によって影響を受ける行時に評価される式 、UPDATE、またはDELETE コマンド です 。評価された結果は、 INTO キーワードの 右側のレコードに割り当てられ ます。 record は、番号と順序が一致するフィールドを含む必要のあるレコードの識別子で、 RETURNING 句の 値と互換性のあるデータ型 です。 field_1 、 field_2 、...は、番号と順序が一致しなければならない変数で、 RETURNING句の
値のセットと互換性のあるデータ型です。
INSERT 、
UPDATE 、または
DELETEコマンドが複数の行を含む結果セットを戻す
場合、 SQLCODE 01422で例外がスローされ
、複数の行が戻されます 。結果セットに行がない場合、
INTOキーワードに続く変数はNULLに設定されます。
注:コレクションに戻される複数の行の結果セットを許可する
BULK COLLECT節を使用すると、
RETURNING INTOのバリエーションがあります。
BULK COLLECT句の詳細については、第
3.12.4項を参照してください。
次の例は、 3.4.5項で導入され
た emp_comp_updateプロシージャの
変更であり、
RETURNING INTO句が追加されています。
次の例は、 emp_delete プロシージャの 変更です 。レコード型を使用し た RETURNING INTO 句が 追加されてい ます。
SQL%ROWCOUNT は、 INSERT 、 UPDATE 、 DELETE 、または SELECT INTO コマンドの 影響を受ける行の数を提供します 。 SQL%ROWCOUNTの 値は、BIGINT データ型 として返されます 。次の例は、挿入されたばかりの行を更新し、 SQL%ROWCOUNT を表示し ます 。
SQL%NOTFOUND は SQL%FOUNDの 反対です 。 SQL%NOTFOUND は 、 INSERT 、 UPDATE または DELETE コマンド によって影響を受けた行がない場合、 または SELECT INTO コマンドが行を取得しなかった 場合 は trueを 返し ます 。
IF 文を使用すると、特定の条件に基づいてコマンドを実行できます。 SPLに は4つの IF 形式があり ます。
IF-THEN 文は、IFの最も単純な形式です 。条件が
真であれば、
THEN と END IFの 間のステートメントが実行され
ます 。それ以外の場合はスキップされます。
次の例では、 IF-THENステートメントを使用して、手数料を持つ従業員をテストして表示します。
IF-THEN-ELSE ステートメントは、条件がfalseと評価された場合に実行されるステートメントの代替セットを指定させることによって、
IF-THENに 追加されます。
IF-THEN-ELSEステートメントを使用して、従業員が
手数料を受け取らない場合は、
非手数料テキストを表示する
ように、前の例を変更しました 。
IF 文を入れ子にして 、外部 IF文の
条件が
真であるか
偽 であるかを判定したら 、代替 IF 文を呼び出すことができ ます 。
次の例では、外側 IF-THEN-ELSEステートメントは、従業員に手数料があるかどうかをテストします。
IF-THEN-ELSEの内側のステートメントは、従業員の総報酬が会社の平均を上回るか下回るかをテストします。
注: このプログラムのロジック は、カーソル宣言の SELECT コマンド 内で NVL 関数 を使用して従業員の年次報酬を計算することによって大幅に単純化できますが 、この例の目的は IF 文の使用 方法を示す ことです。
IF-THEN-ELSIF-ELSE は、1つのステートメントで多くの選択肢をチェックする方法を提供します。正式にはネストされた IF-THEN-ELSE-IF-THEN コマンド と同等ですが 、 END IFは
1つだけ必要です。
次の例では、 IF-THEN-ELSIF-ELSEステートメントを
使用して、従業員数を$ 25,000の補償範囲で数えます。
RETURN文は、現在の関数、プロシージャまたは無名ブロックを終了し、呼び出し元に制御を戻します。
RETURNステートメントに
は2つの形式があります 。
RETURN文の最初の形式は、
voidを返すプロシージャまたは関数を終了するために使用され
ます 。最初の形式の構文は次のとおりです。
RETURN の2番目の形式は 、呼び出し側に値を返します。
RETURNステートメントの2番目の形式の構文は次のとおりです。
式は、関数の戻り値の型と同じデータ型に評価されなければなりません。
GOTO文は、指定されたラベルでのステートメントにジャンプし、実行のポイントになります。 GOTOステートメントの構文は次のとおりです。
labelは実行可能なステートメントに割り当てられた名前です。
ラベルは、関数、プロシージャ、または匿名ブロックの範囲内で一意でなければなりません。
GOTO文は、条件付きブロックまたはサブブロックに制御
を移すことはできません
が 、条件付きブロックまたはサブブロック
から制御
を移すことができます。
• |
GOTO文は、宣言にジャンプすることはできません。 |
• |
GOTO文は、別の関数またはプロシージャに制御を転送することはできません。 |
• |
ラベルは、ブロック、関数またはプロシージャの最後に配置されるべきではありません。 |
CASE 式は CASE式を式の中でどこにあるか置換されている値を返します 。
セレクタ CASE 式は、セレクタと呼ばれる式を1つ以上の WHEN 句で 指定された式に一致させようとします 。 result は、 CASE 式が使用さ れているコンテキストで型互換性のある 式です。一致が見つかると、対応する THEN 句に 指定された値 が CASE 式 によって返され ます。一致するものがなければ、 ELSEに 続く値 が返されます。 ELSEが 省略され た場合 、CASE 式はnullを返します。
match-expression は、 CASE 式の 中に現れる順に評価され ます。 result は、 CASE 式が使用さ れているコンテキストで型互換性のある 式です。 セレクタ式 に 等しい 最初の 一致式 が 見つかる と、対応する THEN 句の 結果 が CASE 式の 値として返されます 。 一致式 のいずれも、 セレクタ式に 等しくない 場合 、 返される ELSE 以下 もたらします 。 ELSE が指定されてい ない場合 、 CASE式はnullを戻します。
検索された CASE 式は、1つまたは複数のブール式を使用して、結果として返される値を決定します。
boolean-expression は、 CASE 式の 中に現れる順序で評価され ます。 result は、 CASE 式が使用さ れているコンテキストで型互換性のある 式です。最初の ブール式が 真 と評価され、その検出された とき 、 対応する 句 を もたらす CASE 式 の値として返されます 。 boolean-expressionの どれもが 真でない場合、 ELSEに 続く 結果 が返されます。 ELSE が指定されてい ない場合 、 CASE式はnullを戻します。
CASE 文は、指定した検索条件が 真 である1つ以上の文のセットを実行し ます。 先に述べた CASE式は式の一部として表示される必要がありながら、CASE文は、それ自体でスタンドアロンステートメントです 。
セレクタ CASE 文は、セレクタと呼ばれる式を1つ以上の WHEN 句で 指定された式に一致させようとします 。一致が見つかると、対応する1つまたは複数のステートメントが実行されます。
selector-expression は、各 match-expression と型互換性のある値を返します 。 match-expression は、 CASE 文の 中に現れる順に評価され ます。 ステートメント は1つ以上の SPL ステートメントで、それぞれがセミコロンで終了します。 セレクタ式 の値は、 最初の 一致式に 等しい 場合 、対応する 句 のステートメント(単数または複数)を 実行し、制御を エンドケースキーワード 以下継続されます 。一致するものがなければ、 ELSEに 続くステートメント が実行されます。一致するものがなく、 ELSE句
がない場合、例外がスローされます。
検索された CASE ステートメントは、1つまたは複数のブール式を使用して、実行されるステートメントの結果セットを判別します。
boolean-expression は、 CASE 文の 中に現れる順に評価され ます。 TRUE と評価される 最初の ブール式 が 検出されると 、対応する THEN 句 の文 が実行され、制御は END CASE キーワードの 後に続きます 。 boolean-expressionの どれも TRUE と 評価され ない場合 、 ELSEに 続く文 が実行されます。 boolean-expressionの いずれも TRUE と 評価され ず、 ELSE節
がない場合、例外がスローされます。
LOOP、EXIT、CONTINUE、WHILE、および FOR 文は、 一連のコマンドを繰り返す あなたの SPL プログラム の手配をすることができます 。
LOOP は、 EXIT または RETURN ステートメントで 終了するまで無期限に繰り返される無条件ループを定義します 。
場合存在する
場合に、ループ出口が指定された条件が
真である場合にのみ発生し、そうでない場合は
EXITの後のステートメントへのパスを制御します。
EXITを使用すると、すべてのタイプのループから早期に終了することができます。無条件ループでの使用に限定されません。
CONTINUE文は、介在文をスキップして、ループの次の繰り返しを進めるための方法を提供します。
ときに CONTINUE文が検出され、最も内側のループの次の反復は、ループの最後まで
CONTINUE文を、次のすべてのステートメントをスキップし、開始されます。つまり、ループ制御式があれば制御が戻され、ループの本体が再評価されます。
場合 WHEN句が使用され、その後、ループの次の反復は
、WHEN句で指定された式が
真と評価された場合にのみ開始されます。それ以外の場合は、
CONTINUEステートメントの次のステートメントに制御が渡されます。
CONTINUE文は、ループの外で使用することはできません。
WHILE文は条件式がTRUEに評価される一連の文を繰り返します。条件は、ループ本体への各エントリの直前でチェックされます。
注意: ループを終了するタイミングを決定する条件式を変更する必要があります。 EXIT 文は、その条件式が真のループを終了します。 WHILE ステートメント終了(または決してループを開始します)その条件式が偽のとき。
FORの この形式は 、整数値の範囲を反復するループを作成します。変数 名 は自動的に INTEGER 型として定義され 、ループ内にのみ存在します。ループ範囲を与える2つの式は、ループに入るときに1回評価されます。反復ステップは1で、 名前は ... の左の 式 の値で始まり 、 名前が .. の右側に 式 の値を超える と終了し ます。したがって、2つの式は、 start-value .. end-valueという 役割を担い ます。
オプションの REVERSE句は、ループが逆の順序で繰り返されるように指定します。ループをはじめて実行するとき、
nameは最も右の
式の値に設定されます。
名前が一番左の
式よりも小さい場合、ループは終了します。
注: SPL は CURSOR FOR ループ もサポートしてい ます ( 3.8.7 項を 参照 )。
デフォルトでは、 SPL プログラムで 発生したエラー はプログラムの実行を中止します。 EXCEPTION セクションの ある BEGIN ブロックを 使用すると、エラーをトラップして回復することができ ます。構文は、 BEGIN ブロックの 通常の構文の拡張です 。
エラーが発生しない場合、この形式のブロックは単にすべての ステートメントを 実行し、 ENDの 後の次のステートメントに制御を渡し ます。エラーが ステートメント 内で発生した場合 、 文 のさらなる処理が 放棄され、制御が 例外リスト に渡されます 。リストは 、発生したエラーと一致する 最初の 条件 が検索され ます。一致するものが見つかった場合は、対応する handler_statements が実行され、 ENDの 後の次のステートメントに制御が渡され ます。一致するものが見つからない場合、 EXCEPTION 句がまったく存在しない かのようにエラーが伝播し ます。 EXCEPTIONを使用 して囲みブロックでエラーを捕らえることができます 。囲みブロックがない場合は、そのサブプログラムの処理を中止します。
特殊条件名 OTHERSはすべてのエラー・タイプに一致します。条件名では大文字と小文字は区別されません。
選択した handler_statements 内で新しいエラーが発生した場合、この
EXCEPTION句ではキャッチできませんが、伝播されます。周囲の
EXCEPTION節がそれを捕まえることができます。
注意:条件名
INVALID_NUMBERおよび
VALUE_ERRORは、文字列を数値リテラルに変換できないことに起因する例外の条件名であるOracleデータベースとは互換性がありません。さらに、Oracleデータベースの場合、
INVALID_NUMBER例外はSQL文にのみ適用され、
VALUE_ERROR例外はプロシージャ文にのみ適用されます。
プログラムの実行中に
何らかのエラー(PL / SQLで 例外 と呼ばれる )が発生することがあります。例外が
スローされると、プログラムの正常な実行が停止し、プログラムの制御がプログラムのエラー処理部分に移ります。
例外は、サーバーによって生成される事前定義されたエラーでも、ユーザー定義の例外を発生させる論理エラーでもかまいません。
宣言のスコープは、パッケージで作成され
ない限り 宣言されているブロックに限定され、参照された場合はパッケージ名で修飾されます。たとえば、
inventory_controlという名前のパッケージにある
out_of_stockという例外を発生させるには、次のようなエラーが発生する必要があります。
次の手順( 購入 )で
check_balanceプロシージャを呼び出します。
p_amountが p_balanceよりも大きい場合
、CHECK_BALANCEは例外を発生させます。
購入は
ar.overdrawn例外をキャッチします。
購入は ARパッケージ内で定義されていないため
、購入はパッケージ修飾名
(ar.overdrawn)で例外を参照しなければなりません。
とき ar.check_balanceは 例外を発生させ、実行は 購入 で定義された例外ハンドラにジャンプ :
PRAGMA EXCEPTION_INITは 、ユーザー定義のエラーコードを例外に関連付けます。 PRAGMA EXCEPTION_INIT 宣言は、任意のブロック、サブブロックまたはパッケージに含まれていてもよいです。例外にのみエラーコードを割り当てることができます( PRAGMA EXCEPTION_INIT )を宣言します。 PRAGMA の形式 EXCEPTION_INIT 宣言は次のとおりです。
exception_number は 、プラグマに関連付けられ たユーザー定義のエラーコード です。 マップされていない exception_number を指定する と、サーバーは警告を返します。
exception_code は、事前定義された例外の名前です。有効な例外の完全なリストについては、以下にあるPostgresのコアドキュメントを参照してください 。
前のセクション( ユーザー定義の例外 )に は、パッケージ内のユーザー定義の例外を明確にする ための例が含ま れていました。次の例では、同じ基本構造を使用しますが、 PRAGMA EXCEPTION_INIT 宣言 が追加されています 。
次の手順( 購入 )で
check_balanceプロシージャを呼び出します。
p_amountが p_balanceよりも大きい場合
、CHECK_BALANCEは例外を発生させます。
購入は
ar.overdrawn例外をキャッチします。
とき ar.check_balanceは 例外を発生させ、実行は 購入 で定義された例外ハンドラにジャンプします。
プロシージャ RAISE_APPLICATION_ERROR を使用すると、開発者は SPL プログラム 内で意図的に処理を中止し 、例外を発生させることで呼び出すことができます。例外は、 3.5.7 項で説明したのと同じ方法で処理され ます。さらに、 RAISE_APPLICATION_ERROR プロシージャは、プログラムで使用可能なユーザー定義コードとエラー・メッセージを作成し、それを使用して例外を識別します。
error_number は、 プロシージャーの実行時に SQLCODE という名前の変数に戻される整数値または式です 。 エラー番号は、-20000 と -20999 の間の値でなければなりません 。
message は、 SQLERRM という名前の変数に戻される文字列リテラルまたは式です 。
詳細については SQLCODE と SQLERRM 変数、のSec ション 参照 3.13を 、 エラーとメッセージ 。
次の例では、 RAISE_APPLICATION_ERRORプロシージャを
使用して 、従業員に欠落している情報に応じて異なるコードとメッセージを表示します。
次の条件が満たされている場合、Oracleデータベースと互換性のあるトランザクション制御スタイルを使用
する SPLアプリケーションを作成できます。
• |
edb_stmt_level_txパラメータが TRUEに設定する必要があります。これにより、例外が発生した場合に BEGIN / ENDブロック内のすべてのデータベース更新を無条件にロールバックするアクションが防止されます。 edb_stmt_level_txパラメータの詳細は、第 1.3.4項を参照してください。 |
トランザクションは、最初の SQLコマンドが
SPLプログラムで検出された
ときに開始され ます 。後続のすべての
SQLコマンドは、そのトランザクションの一部として組み込まれます。トランザクションは、次のいずれかが発生したときに終了します。
• |
COMMITコマンドが検出された場合永久になるトランザクション中に行われたすべてのデータベースの更新の影響をインチ |
• |
ROLLBACKコマンドは、トランザクション中に行われたすべてのデータベースの更新の効果はロールバックされ、トランザクションが中止された場合に発生します。新しいSQLコマンドが検出されると、新しいトランザクションが開始されます。 |
• |
制御は呼び出し元のアプリケーション(Java、 PSQLなど)に 戻ります 。この場合、トランザクションが PRAGMA AUTONOMOUS_TRANSACTIONが宣言されているブロック内にある場合を除いて、トランザクションがコミットまたはロールバックされるかどうかがアプリケーションのアクションによって判断されますトランザクションのコミットメントまたはロールバックは呼び出しプログラムとは独立して行われます。 |
注意: Oracleと異なり、
CREATE TABLEなどの
DDLコマンドは、自分のトランザクション内で暗黙的に発生しません。したがって、
DDLコマンドは
Oracleの場合のように即時データベースコミットを自動的には引き起こさず、
DMLコマンドのように
DDLコマンドをロールバックすることができます。
COMMITコマンドは、永久的な現在のトランザクション中に行われたすべてのデータベースの更新を行い、現在のトランザクションを終了します。
COMMITコマンドは、匿名ブロック、ストアドプロシージャ、または関数内で使用することができます。 SPLプログラム内では、実行可能セクションおよび/または例外セクションに表示されることがあります。
次の例では 、匿名ブロックの
3番目の INSERTコマンドがエラーになります。最初の2つの
INSERTコマンドの効果は、最初の
SELECTコマンドのように保持されます。
ROLLBACKコマンドを発行した後でも、2つの行は、実際にコミットされたことを確認する2番目の
SELECTコマンドに示されているように、テーブルに残ります。
注意:次の例に示す
edb_stmt_level_tx設定パラメータは、
ALTER DATABASEコマンドを使用してデータベース全体に対して設定することも、
postgresql.confファイルでデータベースサーバ全体を設定することもできます。
ROLLBACKコマンドは、現在のトランザクション中に行われたすべてのデータベース更新を元に戻して、現在のトランザクションを終了します。
ROLLBACKコマンドは、匿名ブロック、ストアドプロシージャ、または関数内で使用することができます。 SPLプログラム内では、実行可能セクションおよび/または例外セクションに表示されることがあります。
次の例では、例外セクションに ROLLBACKコマンド
が含まれてい ます 。最初の2つの
INSERTコマンドが正常に実行されたにもかかわらず、3番目の例外の結果、匿名ブロック内のすべての
INSERTコマンドのロールバックが発生します。
次の SELECTコマンドは、FarrellとTylerの従業員が正常に追加されたことを示しています。
テーブルに対して実行SELECTコマンドでは、次のように得られます。
例外セクション
の ROLLBACKコマンドは、従業員Harrisonの挿入を正常に取り消します。また、ファレル(Farrell)とタイラー(Tyler)の従業員は、最初の匿名ブロックの
COMMITコマンドによってその挿入が永続化されているため、テーブルに残っていることにも注意してください。
注意: plpgsqlプロシージャで
COMMITまたは
ROLLBACKを実行すると、ランタイム・スタックにOracleスタイルのSPLプロシージャがある場合はエラーがスローされます。
自律型トランザクションは、呼び出しプログラムによって開始される独立したトランザクションです。自律型トランザクション内のSQLコマンドのコミットまたはロールバックは、呼び出し側プログラムのトランザクションでのコミットまたはロールバックには影響しません。呼び出し元プログラムのコミットまたはロールバックは、自律型トランザクションのSQLコマンドのコミットまたはロールバックには影響しません。
匿名ブロックの最後に与えられ
た ROLLBACKコマンドは、以前の3つの挿入もすべて削除します。
今、 PRAGMA AUTONOMOUS_TRANSACTIONは、匿名ブロックとともに、匿名ブロックの最後にある
COMMITコマンドとともに与えられます。
トランザクションの終了時に
ROLLBACKの 後、トランザクションの最初の行の挿入だけが破棄されます。
PRAGMA AUTONOMOUS_TRANSACTIONを持つ無名ブロック内の他の2行の挿入は、独立してコミットされています。
さて、プロシージャーの最後に
は ROLLBACKコマンド
があり ます 。ただし、
PRAGMA ANONYMOUS_TRANSACTIONはこの手順に含まれていないことに注意してください。
現在、最後に
ROLLBACKコマンドを使用
するプロシージャには、 PRAGMA ANONYMOUS_TRANSACTIONが含まれています。これにより、プロシージャー内の
ROLLBACKコマンドの効果が分離されます。
これらの変更を
empauditlog表に挿入
する emp表に
添付されたトリガーは、次のとおりです。
PRAGMA AUTONOMOUS_TRANSACTIONを宣言セクションにインクルードすることに注意してください。
しかし、このセッション中に
ROLLBACKコマンドが与えられ
ます 。
emp表には2つの行が含まれなくなりましたが、
empauditlog表にはトリガーが暗黙的にコミットを実行し、
PRAGMA AUTONOMOUS_TRANSACTIONが呼び出しトランザクションで指定されたロールバックから独立して変更をコミットするため、
次の無名ブロックでは、オブジェクトの
insert_deptメソッドが呼び出され、無名ブロックに
ROLLBACKコマンドで終わる
挿入が deptテーブルに挿入されます。
insert_deptは自律型トランザクションとして宣言されている
ため 、部門番号60の挿入はテーブルに残りますが、ロールバックで部門50の挿入が削除されます。
動的SQLは、コマンドが実行されるまで知られていない
SQLコマンドを実行する機能を提供するテクニックです。これまでは、
SPLプログラムで示した
SQLコマンドは静的
SQLでした。プログラム以外の完全なコマンド(変数を除く)をプログラムに組み込んでおく必要があります。したがって、動的
SQLを使用すると、実行された
SQLはプログラム実行時に変更される可能性があります。
さらに、動的 SQLは、
CREATE TABLEなどのデータ定義コマンドを
SPLプログラム内から実行できる唯一の方法です。
EXECUTE IMMEDIATEコマンドが動的SQLコマンドを実行するために使用されます。
sql_expression は、 動的に実行される SQL コマンドを 含む文字列式 です。 変数 は、 sql_expressionで SQL コマンド を実行した結果として作成された 、通常は SELECT コマンド の結果セットの出力を受け取り ます 。変数の数、順序、およびタイプは、数値、順序と一致し、結果セットのフィールドと型互換性がなければなりません。あるいは、レコードのフィールドが数値、順序と一致し、結果セットと型互換性がある限り、レコードを指定することができます。 INTO 句 を使用する場合 は、結果セットに1行だけを返す必要があります。それ以外の場合は例外が発生します。 USING 句 を使用すると 、 expression の値が プレースホルダに 渡され ます。プレースホルダは、 sql_expression のSQLコマンド内に埋め込まれているように見え ますが、変数は使用できます。 名前 : - :()接頭辞 プレースホルダは、コロンと識別子が付されています 。評価式の数、順序、および結果のデータ型は、数値と順序が一致し、 sql_expression のプレースホルダと型互換性がなければなりません 。プレースホルダは SPL プログラムの どこにでも宣言されていないことに注意してください 。 これらは sql_expression にのみ表示され ます 。
次の例は、
SQL文字列のプレースホルダに値を渡す
USING句を
示しています。
次の例は、 INTO句と
USING句の
両方を示しています。
SELECTコマンドを最後に実行すると、結果が個々の変数ではなくレコードに返されることに注意してください。
BULK COLLECT句を
使用すると 、
EXECUTE IMMEDIATE文の結果セットを名前付き
コレクションにアセンブル
できます 。セクションを参照してください。 3.12.4を 、BULK COLLECT句
の 使用方法については 、COLLECT IMMEDIATE BULKを実行します。
クエリ全体を一度に実行するのではなく 、クエリをカプセル化 した カーソル を設定し、一度に 1行ずつクエリ結果セットを読み取ることができます。これにより、結果セットから行を取り出し、その行のデータを処理し、次の行を取り出してプロセスを繰り返す
SPLプログラム・ロジックを
作成できます。
name は、カーソルとその結果セットを後でプログラムで参照するために使用される識別子です。 クエリ は SQLです カーソルによって検索可能な結果セットを決定する
SELECTコマンド。
注意:この構文を拡張すると、パラメータを使用できます。これについては
3.8.8節で詳しく説明します。
name は、 SPL プログラムの 宣言セクションで以前に宣言されたカーソルの識別子です 。 OPEN文は、既にされているカーソル上で実行され、まだ開いてはいけません。
以下に 、対応するカーソル宣言を伴う
OPENステートメントを
示します。
name は、以前に開いたカーソルの識別子です。 record は、以前に定義されたレコードの識別子です(たとえば、 テーブル %ROWTYPEを使用 )。 変数 、 variable_2 ...は 、フェッチされた行からフィールドデータを受け取る SPL 変数です。 レコード または 変数 、variable_2 ... のフィールドは、 数と順序に一致している必要があり、各フィールドは、 カーソル宣言で与えられたクエリの SELECT リスト 内に返されました 。 SELECT リスト 内のフィールドのデータ型が 一致し、または レコード 内のフィールド または 変数 のデータ型 、variable_2 のデータ型に暗黙的に変換可能である必要があります ...
注:一度に複数の行をコレクションに戻すことができる
BULK COLLECT節を使用すると、
FETCH INTOのバリエーションがあります。
FETCH INTO文で
BULK COLLECT句を使用する方法の詳細は、第
3.12.4項を参照してください。
name は、現在開いているカーソルの識別子です。一旦カーソルが閉じられると、それは再び閉じられてはならない。ただし、カーソルがクローズ されると、クローズされたカーソルで OPEN 文を再度発行し、問合せ結果セットを再構築した後、 FETCH文を使用して新しい結果セットの行を取り出すことができます。
%ROWTYPE 属性 を使用 すると、カーソルまたはカーソル変数からフェッチされたすべての列に対応するフィールドを含むレコードを定義できます。各フィールドは、対応する列のデータ型を取ります。 %ROWTYPE 属性は、カーソル名またはカーソル変数名が付けられます。
レコード は レコードに 割り当てられた識別子です。 cursorは、現在のスコープ内で明示的に宣言されたカーソルです。
%ISOPEN 属性はカーソルがオープンしているかどうかをテストするために使用されます。
cursor_name は、 カーソルが開いている場合は BOOLEAN データ型 TRUE が返される カーソルの名前 、 FALSE さもないと。
%FOUND 属性は、 カーソルで FETCH 後行が指定されたカーソルの結果セットから取得されたか否かをテストするために使用されます 。
cursor_name は、 FETCHの 後にカーソルの結果セットから行が取り出された場合 に TRUEの BOOLEAN データ・タイプ が戻される カーソルの名前です 。
結果セットの最後の行が FETCH された後、次の
FETCHは
%FOUNDを返してFALSEを返します。先頭に結果セットに行がない場合は、最初の
FETCHの後にFALSEも戻されます。
カーソルがオープンされる前または閉じられた後にカーソルで
%FOUNDを
参照すると、
INVALID_CURSOR例外がスローされます。
%FOUND は 、カーソルが開いているとき、最初の FETCHの 前に参照されている場合は nullを 返し ます 。
%のNOTFOUND 属性は、FOUND%の論理的に反対です 。
cursor_name は、 FETCHの 後のカーソルの結果セットから行が検索された場合に、FALSEの BOOLEAN データ・タイプが戻される カーソルの名前です 。
結果セットの最後の行が FETCH された後、次の
FETCHは
%NOTFOUNDに
TRUEを返します。また、最初に結果セットに行がない場合は、最初の
FETCHの後に
TRUEも戻されます。
カーソルがオープンされる前、または閉じられた後に
%NOTFOUNDを
参照すると、
INVALID_CURSOR例外がスローされます。
%NOTFOUND は 、カーソルが開いているときに、最初の FETCHの 前に参照されている場合は nullを 返し ます 。
%のROWCOUNT 属性は、行の数を示す整数で 指定されたカーソルからこれまで編 FETCH 返します 。
cursor_name は、 %ROWCOUNT がそれまでに検索された行数を戻す カーソルの名前です 。最後の行は、 行の合計数に設定 %のROWCOUNTが 残って 、検索された後に カーソルが参照場合
、%ROWCOUNTは、INVALID_CURSOR 例外が
スローされ た時点でクローズされるまで戻りました 。
カーソルがオープンされる前、または閉じられた後に
%ROWCOUNTを
参照すると、
INVALID_CURSOR例外がスローされます。
%ROWCOUNT は 、カーソルが開いているときに、最初の FETCHの 前に参照されている場合は 0を 返します 。 %ROWCOUNTは また 、最初に結果セットに行がない場合
、最初の FETCHの 後に 0 を 返します 。
カーソル FORループは、以前に宣言されたカーソルをオープンし、カーソル結果セット内のすべての行を取り出してから、カーソルをクローズします。
レコード は暗黙的に宣言されたレコードに割り当てられた識別子、 カーソル %ROWTYPE です。 cursor は、以前に宣言されたカーソルの名前です。 ステートメント は、1つ以上の SPLステートメントです。少なくとも1つのステートメントが必要です。
カーソル変数は、 実際に は 、クエリ結果セットへのポインタを含むカーソルです。 結果セットは 、カーソル変数を使用したOPEN FOR文の実行によって決定されます。
REF CURSOR 型は、ストアドプロシージャとストアドプロシージャ間でパラメータとして渡すことが できます 。関数の戻り値の型は、 REF CURSOR 型であって もよい 。これは、プログラム間にカーソル変数を渡すことにより、カーソル上の操作を別々のプログラムにモジュール化する機能を提供します。
SPL は、 SYS_REFCURSOR ビルトイン・データ型と REF CURSOR 型を作成し、 その型の変数を宣言する だけでなく 、カーソル変数の宣言もサポート しています。 SYS_REFCURSOR は REF CURSOR 型で、結果セットを関連付けることができます。これは、 弱く型付けされた REFカーソル 。
SYS_REFCURSORとユーザー定義の
REF CURSOR変数
の宣言だけが異なります。カーソルを開く、カーソルに選択する、カーソルを閉じるなどの残りの使用法は、両方のカーソルタイプで同じです。この章の残りの部分では、主に
SYS_REFCURSORカーソルを使用する例を示します。ユーザー定義の
REF CURSORで動作させるために例で変更する必要があるのは、宣言セクションです。
注: 強くタイプされた REF CURSOR は、結果セットが、互換性のあるデータ型を持つフィールドの宣言された数と順序に適合することを要求し、オプションで結果セットを返すこともできます。
nameはカーソル変数に割り当てられた識別子です。
name は、以前に宣言されたカーソル変数の識別子です。 query は 、ステートメントの実行時に結果セットを決定 する SELECT コマンドです。 OPEN FOR文が実行された
後のカーソル変数の値は 、結果セットを識別します。
以下の例では 、前の例に
FETCHステートメントが追加されたので、結果セットは2つの変数に戻されて表示されます。静的カーソルのカーソル状態を決定するために使用されるカーソル属性は、カーソル変数とともに使用することもできます。カーソル属性の詳細は、
3.8.6項を参照してください。
注:静的カーソルとは異なり、カーソル変数を再度開く前に閉じる必要はありません。前回開いた結果セットは失われます。
たとえば、 プロシージャーが仮パラメーターとして宣言されたカーソル変数の OPEN FOR 、 FETCH 、および CLOSEの 3つの操作をすべて実行する場合、 そのパラメーターは IN OUT モードで 宣言する必要があり ます。
Advanced Server は、 OPEN FOR USING 文 を使用して動的クエリをサポートしてい ます 。文字列リテラルまたは文字列変数は、 OPEN FOR USING 文で SELECT コマンドに 提供され ます。
name は、以前に宣言されたカーソル変数の識別子です。 dynamic_string は、 セミコロンを終了せずに SELECT コマンド を含む文字列リテラルまたは文字列変数です 。 bind_arg 、 bind_arg_2 ...は 、カーソル変数がオープンされたとき
に、 SELECTコマンドの
対応するプレースホルダに変数を渡すために使用されるバインド引数です 。プレースホルダは、コロン文字を前に付けた識別子です。
コレクションは、同じデータ型の注文データ項目のセットです。一般に、データ項目はスカラー項目ですが、ユーザー定義型の各フィールドを構成する構造体とデータ型が同じであれば、レコード型やオブジェクト型などのユーザー定義型でもかまいませんセット内の各要素に対してセット内の各特定のデータ項目は、一対の括弧内の添字表記を使用して参照されます。
注:マルチレベルコレクション(つまり、コレクションのデータ項目が別のコレクションである)はサポートされていません。
連想配列は値を持つ一意のキーを関連付け、コレクションの一種です。キーは数値である必要はありませんが、文字データでもかまいません。
• |
連想配列型は、 配列変数は、その配列型の宣言することができた後に定義する必要があります。データ操作は、配列変数を使用して行われます。 |
TYPEは、OF ...文のBY INDEX TABLEは、連想配列タイプを定義するために使用されます。
assoctype は配列型に割り当てられた識別子です。 datatype は、 VARCHAR2 または NUMBER などのスカラー・データ型 です。 rectypeは、以前に定義されたレコードタイプです。
objtypeは、以前に定義されたオブジェクト型です。
nは文字キーの最大長です。
配列を使用するには、その配列型で
変数を宣言する必要があります。配列変数を宣言する構文は次のとおりです。
配列 は、連想配列に割り当てられた識別子です。 assoctypeは、あらかじめ定義された配列型の識別子です。
array は、以前に宣言された配列の識別子です。 n はキー値で、 INDEX BY 句で 指定されたデータ型と型互換性があります 。 アレイ の配列型は、 レコード型またはオブジェクト型から定義されている 場合 、[。 フィールド ]は、配列タイプが定義されているオブジェクトタイプ内のレコードタイプまたは属性内の個々のフィールドを参照する必要があります。あるいは、レコード全体を参照するには、[。 フィールド ]をクリックします。
EMPの%ROWTYPE 属性は、 以下に示すように emp_rec_typ レコードタイプを 使用して代わりのを emp_arr_typ 定義するために使用することができます 。
ネストされたテーブルの値と正の整数を関連付けるコレクションの一種です。ネストした表には、次の特性があります。
• |
ネストした表型は、 ネストされたテーブル変数は、そのネストした表型の宣言することができた後に定義する必要があります。データ操作は、ネストした表変数、または単純に「表」を使用して行われます。 |
• |
コンストラクタは、テーブル内の要素の数を設定します。 EXTEND方法は、テーブルに追加要素を追加します。収集方法については、 3.11節を参照してください。 注意:コンストラクタを使用して表の要素数を設定し、 EXTENDメソッドを使用して表に要素を追加する方法は、Oracleでは必須ですが、SPLではオプションです。 |
TYPEは、TABLE文がSPLプログラムの宣言セクション内にネストされたテーブル・タイプを定義するために使用されています 。
tbltype は、ネストした表の型に割り当てられた識別子です。 datatype は、 VARCHAR2 または NUMBER などのスカラー・データ型 です。 rectypeは、以前に定義されたレコードタイプです。
objtypeは、以前に定義されたオブジェクト型です。
注意: CREATE TYPEコマンドを使用して、データベース内のすべてのSPLプログラムで使用可能なネストした表の型を定義できます。
CREATE TYPEコマンドの詳細は、「Oracle Developer Reference Guide」のデータベース互換性を参照してください。
表を使用するには、そのネストした表の型の
変数を宣言
する必要があります。以下は、表変数を宣言するための構文です。
table は、ネストした表に割り当てられた識別子です。 tbltypeは、以前に定義されたネストしたテーブル型の識別子です。
tbltypeは、ネストした表の型と同じ名前のネストした表の型のコンストラクタの識別子です。
expr1 、
expr2 、...は、テーブルの要素型と型互換性のある式です。
NULLが指定された場合、対応する要素はnullに設定されます。パラメータ・リストが空の場合、空のネストした表が戻されます。これは、表に要素がないことを意味します。表がオブジェクト型から定義されている場合、
exprnはそのオブジェクト型のオブジェクトを返す必要があります。オブジェクトは、関数またはオブジェクト型のコンストラクタの戻り値にすることも、同じ型の別のネストした表の要素にすることもできます。
EXISTS 以外の収集メソッドを初期化されていないネストした表に適用すると、
COLLECTION_IS_NULL例外がスローされます。収集方法については、
3.11節を参照してください。
table は、以前に宣言されたテーブルの識別子です。 n は正の整数です。 テーブル のテーブルタイプは、 レコード・タイプまたはオブジェクト・タイプから定義されている 場合 、[。 要素 ]は、ネストした表の型が定義されているオブジェクト型内のレコード型または属性内の個々のフィールドを参照する必要があります。あるいは、レコードまたはオブジェクト全体を参照するには、[。 要素 ]。
注意:ネストした表のコンストラクタ
dept_tbl_typを構成するパラメータは、オブジェクト型のコンストラクタ
dept_obj_typへのコールです。
VARRAYまたは可変サイズアレイは、値が正の整数を関連付けるコレクションの一種です。多くの点で、ネストした表に似ています。
• |
VARRAY型は、最大サイズの制限と一緒に定義されなければなりません。 VARRAY型が定義されると、そのVARRAY型のVARRAY型変数を宣言できます。データ操作は、varray変数、または単に「varray」を使用して行われます。 VARRAYの要素数は、VARRAY型定義で設定されている最大サイズ制限を超えることはできません。 |
TYPEは、VARRAYステートメントはSPLプログラムの宣言セクション内のVARRAY型を定義するために使用されています 。
varraytype は、VARRAY型に割り当てられた識別子です。 datatype は、 VARCHAR2 または NUMBER などのスカラー・データ型 です。 maxsize は、その型のVARRAYで許される要素の最大数です。 objtype は、以前に定義されたオブジェクト型です。
注: CREATE TYPEコマンドを使用して、データベース内のすべての
SPLプログラムで使用可能なVARRAYタイプを定義することができます。 VARRAYを使用するには、VARRAY型の
変数を宣言
する必要があります。次に、VARRAY変数を宣言するための構文を示します。
varray は、 VARRAYに 割り当てられた識別子です。 varraytypeは、あらかじめ定義されたVARRAY型の識別子です。
varraytypeは、VARRAY型のコンストラクタの識別子で、VARRAY型と同じ名前を持ちます。
expr1 、
expr2 、...は、VARRAYの要素型と型互換性のある式です。
NULLが指定された場合、対応する要素はnullに設定されます。パラメータリストが空の場合、空のVARRAYが返されます。つまり、VARRAYには要素がありません。 VARRAYがオブジェクト型から定義されている場合、
exprnはそのオブジェクト型のオブジェクトを返す必要があります。オブジェクトは、関数の戻り値、またはオブジェクト型のコンストラクタの戻り値です。オブジェクトは、同じVARRAY型の別のVARRAYの要素でもあります。
EXISTS 以外の収集メソッドを初期化されていないVARRAYに適用すると、
COLLECTION_IS_NULL例外がスローされます。収集方法については、
3.11節を参照してください。
varray は、以前に宣言されたVARRAYの識別子です。 n は正の整数です。 VARRAY のVARRAY型は、 オブジェクトタイプから定義されている 場合 、[。 要素 ] は、VARRY型が定義されているオブジェクト型内の属性を参照する必要があります。あるいは、 [。]を 省略してオブジェクト全体を参照することもできます 。 要素 ] 。
コレクションメソッドは、コレクション内のデータの処理を支援するコレクションに関する有用な情報を提供する関数およびプロシージャです。次のセクションでは、Advanced Serverでサポートされている収集方法について説明します。
COUNT は、コレクション内の要素の数を返すメソッドです。 COUNT を使用するための構文 は次のとおりです。
DELETEメソッドは、コレクションからエントリを削除します。 DELETEメソッドは、3つの異なる方法で呼び出すことができます。
第三の形態を使用コレクションから
(first_subscriptと
last_subscriptのエントリを含む
)first_subscriptと
last_subscriptで指定された範囲内にあるエントリを削除する
DELETEメソッドを。
コレクション .DELETE( 最初の _ 添字 、 最後の _ 添字 )
first_subscriptおよび
last_subscriptが存在しない要素を参照する
場合 、指定された添字間の範囲にある要素が削除されます。
first_subscriptが last_subscriptよりも大きい場合、またはあなたが引数のいずれかに
NULL値を指定した場合、
削除した場合は効果がありません。
COUNTは、
DELETEメソッドの前にコレクションに
5つの要素があったことを示します。
DELETEメソッドが呼び出された後、コレクションには
4つの要素が含まれます。
この方法は、添字がコレクション内に存在することを確認しEXISTS。 EXISTSは、添え字が存在する場合はTRUEを返します。添え字が存在しない場合、 EXISTSはFALSEを返します 。このメソッドは単一の引数をとります。あなたがテストしている添字 。構文は次のとおりです。
添え字はあなたがテストしている値です。値に
NULLを指定すると、
EXISTSは
falseを返し
ます 。
EXTENDメソッドは、コレクションのサイズを増大させます。 EXTENDメソッドには3つのバリエーションがあります。最初のバリエーションは、単一のNULL要素をコレクションに追加します 。最初のバリエーションの構文は次のとおりです。
次の例は、 EXTENDメソッドを使用して単一のnull要素をコレクションに追加する方法を
示しています。
COUNTは、
EXTENDメソッドの前にコレクションに
5つの要素があったことを示します。
EXTENDメソッドが呼び出された後、コレクションには
6つの要素が含まれます。
countは、コレクションの末尾に追加されたヌル要素の数です。
次の例は、 EXTENDメソッドを使用して複数のnull要素をコレクションに追加する方法を
示しています。
COUNTは、
EXTENDメソッドの前にコレクションに
5つの要素があったことを示します。
EXTENDメソッドが呼び出された後、コレクションには
8つの要素が含まれます。
コレクション .EXTEND( count 、 index_number )
countは、コレクションの最後に追加された要素の数です。
COUNTは、
EXTENDメソッドの前にコレクションに
5つの要素があったことを示します。
EXTENDメソッドが呼び出された後、コレクションには
8つの要素が含まれます。
注: EXTENDメソッドは、ヌルまたは空のコレクションでは使用できません。
FIRSTは、コレクション内の最初の要素の添字を返すメソッドです。
FIRSTを使用するための構文は次のとおりです。
LASTは、コレクション内の最後の要素の添字を返すメソッドです。
LASTを使用するための構文は次のとおりです。
LIMIT は、コレクション内で許可される要素の最大数を返すメソッドです。 LIMIT はVARRAYにのみ適用されます。 LIMIT を使用するための構文 は次のとおりです。
初期化されたVARRAYの場合、 LIMITはVARRAY型定義によって決定される最大サイズ制限を戻します。 VARRAYが初期化されていない場合(つまり、VARRAYがNULLの場合)、例外がスローされます。
NEXTは、指定された添え字に続く添え字を返すメソッドです。このメソッドは単一の引数をとります。あなたがテストしている
添字 。
次の例は、 NEXTを
使用して、連想配列
sparse_arrの下付き文字
10に続く添字を返します。
従来の方法は、 コレクション内の指定の添字の前の添字を返します。 このメソッドは単一の引数をとります 。あなたがテストしている添字 。 構文は次のとおりです。
指定された添え字に 先行 文字がない場合、 PRIOR は NULLを 返し ます 。指定された添え字がコレクション内の最後の添え字より大きい場合、このメソッドは最後の添え字を返します。 NULL 添字 を指定すると 、 PRIOR は値を返しません。
TRIM方法は、コレクションの末尾から要素または要素を除去します。 TRIMメソッドの構文は次のとおりです。
countは、コレクションの最後から削除された要素の数です。
countが
0より小さいか、コレクション内の要素の数よりも多い場合、Advanced Serverはエラーを返します。
COUNTは、
TRIMメソッドの前にコレクションに
5つの要素があったことを示します。
TRIMメソッドが呼び出された後、コレクションには
4つの要素が含まれます。
COUNTは、
TRIMメソッドの前にコレクションに
5つの要素があったことを示します。
TRIMメソッドが呼び出された後、コレクションには
3つの要素が含まれます。
TABLE() 関数を 使用して 、配列のメンバーを一連の行に変換します。署名は次のとおりです。
表() 関数は、テーブル形式にコレクションのネストされた内容を拡張します。 通常のテーブル式を使用する場所であれば 、 TABLE() 関数を使用できます。
表() 関数は SETOFを 返します ANYELEMENT (任意の型の値の集合)。たとえば、この関数に渡された引数が 日付の 配列である 場合、 TABLE() は SETOF 日付 。この関数に渡された引数が パスの 配列である 場合、 TABLE() は SETOF パス 。
TABLE() 関数を 使用する と、コレクションの内容を表形式に展開 できます 。
MULTISET UNION演算子は、第三のコレクションを形成するために、2つのコレクションを兼ね備えています。署名は次のとおりです。
coll_1と
coll_2は結合するコレクションの名前を指定します。
重複する要素(
coll_1と
coll_2の両方に存在する要素)を元のコレクションに存在するたびに1回ずつ結果に表示するように指定するに
は、 ALLキーワードを
含めます 。これは、
MULTISET UNIONのデフォルトの動作です。
重複した要素を結果に1回だけ
含めるように指定するに
は、 DISTINCTキーワードを
含め ます 。
次の例は、 MULTISET UNION演算子を
使用して、2つのコレクション(
collection_1および
collection_2 )を3番目のコレクション(
collection_3 )に結合
する方法を示しています 。
コレクションを使用すると、
DELETE 、
INSERT 、または
UPDATEコマンドの繰り返し実行に使用するすべての値を、新しい値で
DMLコマンドを反復的に呼び出すのではなく、データベース・サーバーに渡すことで、
DMLコマンド
をより効率的に処理できます。このように処理される
DMLコマンドは、
FORALL文で指定されます。さらに、コマンドが実行されるたびに異なる値が代入される
DMLコマンドには、1つ以上のコレクションが指定されてい
ます 。
インデックスが insert_stmtで指定されたコレクション内の位置であり
、update_stmt、または
DML delete_stmt UPPER_BOUND含むまで
LOWER_BOUNDとして整数値から反復が与えられたコマンド。
注:例外は
FORALL文の任意の反復中に発生した場合は
、FORALL文の実行の開始以降に発生したすべての更新が自動的にロールバックされます。この動作は
Oracleデータベースと互換性がありません。
Oracleでは、
COMMITまたは
ROLLBACKコマンドを明示的に使用して、例外の前に発生した更新をコミットまたはロールバックするかどうかを制御できます。
FORALL文は、ループを作成します-ループの各反復は、 インデックス変数を(あなたは、通常のコレクションのメンバーを選択するには、ループ内のインデックスを使用)インクリメント。反復回数は、 lower_bound .. upper_bound節によって制御されます 。ループはlower_boundとupper_boundの間の整数ごとに1回実行され、インデックスは各反復ごとに1つずつインクリメントされます。例えば:
次の例では、
emp表の空のコピーで
ある表( emp_copy )を
作成します。この例では、配列
emp_tblを宣言します。この型は、配列
empの作成に使用される列定義で構成される配列の各要素が複合型である配列です。この例では、
emp_tbl型の索引も作成します。
t_empは、
emp_tbl型の連想配列
です 。
SELECTステートメントでは、
BULK COLLECT INTOコマンドを使用して
t_emp配列に値を設定します。
t_emp配列が移入された後、
FORALL文は
t_emp配列索引の値(
i )を反復し、各レコードの行を
emp_copyに挿入し
ます 。
多数の行からなる結果セットを返す
SQLコマンドは、結果セット全体を転送するためにデータベースサーバとクライアントの間で行われなければならない定数的な切り替えのため、できるだけ効率的に動作しない可能性があります。この非効率性は、コレクションを使用して、クライアントがアクセスできるメモリー内の結果セット全体を収集することによって軽減できます。
BULK COLLECT句を使用して、結果セットの集約をコレクションに指定します。
BULK句を収集 INTO FETCHとIMMEDIATEコマンドを実行し、DELETE、INSERT、およびUPDATEコマンドのRETURNING INTO句で、SELECT INTOで使用することができます。これらのそれぞれについて以下のセクションで説明します。
次のように
BULK COLLECT句は
、SELECT INTO文で使用することができます。
SELECT INTO文の詳細は、
3.4.3項を参照してください。
シングルコレクションが指定されている場合は、その コレクションは 、単一のフィールドの集合体であってもよいし、レコード型の集合であってもよいです。複数のコレクションが指定されている場合、各
コレクションは単一のフィールドで構成されている必要があります。
select_expressionsは、ターゲットコレクション内のすべてのフィールドの番号、順序、型互換性が一致する必要があります。
BULK COLLECT句は
、FETCH文で使用することができます。 (
FETCH文の詳細は、
3.8.3項を参照してください。)
FETCH BULK COLLECTは、結果セットから一度に1つの行を戻す代わりに、結果セットからすべての行を指定されたコレクションに戻します。
LIMIT句。
シングルコレクションが指定されている場合は、その コレクションは 、単一のフィールドの集合体であってもよいし、レコード型の集合であってもよいです。複数のコレクションが指定されている場合、各
コレクションは単一のフィールドで構成されている必要があります。
名前で識別されるカーソルの
SELECTリスト内の式は、ターゲットコレクション内のすべてのフィールドの番号、順序、型互換性が一致する必要があります。
LIMIT nを指定すると、各
FETCHのコレクションに戻される行の数は
nを超えません。
次の例では、 FETCH BULK COLLECTステートメントを使用して行を連想配列に
戻します。
BULK COLLECT句は、返される行を受信するコレクションを指定するには、EXECUTE IMMEDIATE文で使用することができます。
|
•
|
INのバインド _ タイプは、 バインドが _ 引数が SQL _ 式に渡された値が含まれていることを指定します。 |
• |
OUTのバインド _ タイプは、 バインドが _ 引数が SQL _ 式から値を受け取ることを指定します。 |
• |
、IN OUTのバインド _ タイプは のbind_argumentが sql_expressionに渡されることを指定し、SQL _ 式の戻り値を格納します。 |
bind_argumentは (INの
bind_typeで指定
)sql_expressionに渡されたいずれかの値が含まれているパラメータを指定する、またはそれは
、(OUTの
bind_typeで指定
)sql_expressionから値を受け取り、またはその両方
(INの
bind_typeで指定します
OUT )。
BULK COLLECT句は
、DELETE、INSERT、または
UPDATEコマンドの
INTO句
RETURNINGに添加することができます。 (
RETURNING INTO句の詳細は、
3.4.7項を参照してください。)
INSERT 、
UPDATE 、および
DELETEコマンドは、
3.4.4項、
3.4.5項および
3.4.6項でそれぞれ説明した
挿入 、
更新および
削除です。シングルコレクションが指定されている場合は、その
コレクションは 、単一のフィールドの集合体であってもよいし、レコード型の集合であってもよいです。複数のコレクションが指定されている場合、各
コレクションは単一のフィールドで構成されている必要があります。
RETURNINGキーワードの後に続く式は、ターゲットコレクション内のすべてのフィールドの数、順序、および型互換性で一致する必要があります。
*を指定すると、影響を受ける表のすべての列が戻されます。
(*の使用は、Advanced Serverの 拡張機能 であり 、Oracleデータベースと互換性が ない ことに注意してください 。)
以下に示すように、EMP表をコピーして作成したclerkempテーブルは、このセクションの残りの実施例で使用されています。
メッセージを報告 するには、 DBMS_OUTPUT.PUT_LINE 文を 使用し ます。
特殊変数 SQLCODE および SQLERRMに は、最後に 発行された SQL コマンドの 結果を記述する数値コードおよびテキスト・メッセージがそれぞれ含まれています 。ゼロ除算のような他のエラーがプログラムで発生した場合、これらの変数にはエラーに関する情報が含まれます。
この章では 、 Advanced Serverの トリガ について説明 し ます 。プロシージャと関数と同様に、トリガは SPL 言語で 記述され ます。
トリガーは、 テーブルに関連付けられてデータベースに格納され た名前付き SPL コードブロックです。関連するテーブルで指定されたイベントが発生すると、 SPL コードブロックが実行されます。トリガは 、コードブロックが実行され
たとき
に 起動 されると言われます 。
Advanced Server は、 行レベル と 文レベルの トリガーの 両方をサポートし ます。行レベルのトリガーは、トリガー・イベントの影響を受ける行ごとに1回発生します。たとえば、削除が表のトリガー・イベントとして定義され、表から5つの行を削除
する1つの DELETEコマンドが発行された場合、トリガーは各行に対して1回5回起動します。
トリガーアクションが影響を受ける各列に対して実行される前に、 前にロー・レベル・トリガ、トリガコードブロックが実行されます。 before文レベル・トリガーでは、トリガー・コード・ブロックは、トリガー・ステートメントのアクションが実行される前に実行されます。
トリガーアクションが影響を受ける各列に対して行われた後、行レベルのトリガ後に 、トリガコードブロックが実行されます。 afterステートメント・レベル・トリガーでは、トリガー・コード・ブロックは、トリガー・ステートメントのアクションが実行された後に実行されます。
TRIGGER コマンド定義と名称データベースに格納されるトリガーを 作成 。
CREATE TRIGGERは新しいトリガーを定義します。
CREATE OR REPLACE TRIGGERは新しいトリガーを作成するか、既存の定義を置き換えます。
あなたが使用している場合、新しいトリガを作成するには
、CREATE TRIGGERのキーワードを、新しいトリガの名前が同じテーブルに定義されている既存のトリガーと一致してはいけません。新しいトリガーは、トリガー・イベントが定義されている表と同じスキーマに作成されます。
conditionはトリガーが実際に実行されるかどうかを決定するブール式です。
conditionが
TRUEと評価された場合、トリガが起動します。
トリガ定義に FOR EACH ROWキーワードが
含まれている場合、 WHEN句は
OLDを記述して古い行および/または新しい行の値の列を参照できます。
列 _ 名前または
NEW 。
列 _ 名をそれぞれ指定します。
INSERTトリガーは
OLDを参照できず、
DELETEトリガーは
NEWを参照できません。
トリガーに INSTEAD OFキーワードが
含まれている場合は、
WHEN句が含まれていない可能性があります。
古いものとして古いものを 参照する | NEW AS 新しいです } ...
REFERENCING節は古い行と新しい行を参照しますが、
oldは
oldやそれ以外のすべての小文字で保存された識別子で置き換えられます(たとえば、
REFERENCING OLD AS old 、
REFERENCING OLD AS OLD 、
REFERENCING OLD AS "古い" )。また、
新しいだけ
で (例えば
、NEW AS NEWを参照する 、
新しいAS NEWを参照するか
、「新しい」としてNEWを参照 )
新しい名前付き識別子またはすべて小文字に保存されている任意の等価に置き換えることができます。
OLD AS oldおよび
NEW AS newの いずれか、または両方を REFERENCING節に指定することができます(たとえば、
REFERENCING NEW AS OLD AS NEWと同様に
REFERENCING )。
これらの識別子が古い行と新しい行を参照するための疑似レコード名としてどのように使用されるかについては、
3.4 項を参照してください 。
変数、型、 REF CURSOR 、またはサブプログラムの宣言。
サブプログラム宣言が含まれている場合は、他のすべての変数、型、および REF CURSOR 宣言の 後に宣言する必要があり ます 。
SPLプログラム文です。 DECLARE-BEGIN-ENDブロックはSPLステートメントとみなされます。したがって、トリガー本体にネストされたブロックが含まれることがあります。
NEWは、疑似レコード名で、行レベルのトリガーでの挿入操作と更新操作の新しい表行を指します。この変数は、文レベルのトリガーおよび行レベルのトリガーの削除操作には適用されません。
その使用法は次の とおりです。
:NEW 。
カラムは、トリガが定義されているテーブルの列の名前である
列 。
の最初の内容 :NEW 。
列は、挿入される新しい行の名前付き列の値です。行レベルの前のトリガーで使用された場合は、新しい行の名前が古い行を置き換えます。行レベルの後のトリガーで使用すると、影響を受けた行ですでにアクションが発生しているため、この値はすでに表に保管されています。
トリガコードブロックでは、 :NEW 。
列は、他の変数と同様に使用することができます。値が
NEWに割り当てられている場合。
列は 、前の行レベルトリガのコードブロックに、割り当てられた値は、新たな挿入または更新された行で使用されます。
OLDは、行レベル・トリガーの更新および削除操作のために古い表の行を参照する擬似レコード名です。この変数は、文レベルのトリガーおよび行レベルのトリガーの挿入操作には適用されません。
その使用法は:: OLD 。
カラムは、トリガが定義されているテーブルの列の名前である
列 。
初期の内容 :OLD 。
columnは、削除される行の指定された列の値、または行レベルの前のトリガーで使用されたときに新しい行に置き換えられる古い行の値です。行レベル・トリガー後に使用すると、影響を受けた行ですでにアクションが発生しているため、この値は表に保管されなくなります。
トリガーコードブロックでは :OLD 。
列は、他の変数と同様に使用することができます。値の割り当て
:OLD 。
列は、トリガの動作に影響を与えません。
INSERTING は、 挿入操作によってトリガーが発生した場合 は true を戻す条件式です 。 それ以外の場合は falseを 戻し ます 。
UPDATING は、 更新操作によってトリガが発生した場合 は true を返す条件式です 。 それ以外の場合は falseを 返し ます 。
DELETING は、 削除操作によってトリガーが発生した場合 は true を戻す条件式で 、そうでない場合は falseを 戻し ます 。
次の INSERT は、コマンドの1回の実行時にいくつかの新しい行が挿入されるように構成されています。従業員IDが7900〜7999の行ごとに、従業員IDを1000ずつ増やした新しい行が挿入されます。次に、3つの新しい行が挿入されたときにコマンドを実行した結果を示します。
新規従業員を追加しようとしている というメッセージは 、結果が3つの新しい行 が追加され ているにも関わらず、トリガーの起動によって1回表示されます。
次の一連のコマンドでは、2 つの INSERT コマンド を使用 して emp テーブル に2つの行が挿入され ます。 両方の行 の sal および comm 列は、1つの UPDATE コマンドで 更新され ます。最後に、両方の行が1つの DELETE コマンドで 削除され ます。
empauditlog 表 の内容には 、トリガーが2回挿入された回数、1回更新(2回の行が変更された場合でも)および削除の1回(2つの行が削除された場合でも)に発生した回数が示されます。
以下に示す最初のコマンドシーケンスでは、2人の従業員が2つの別々の INSERT コマンド を使用して追加され 、その後両方とも1つの UPDATE コマンド を使用して更新され ます。 求職者 テーブル の内容には、 影響を受けた各行のトリガーアクションが表示されます.2人の新しい従業員の2つの新しい雇用エントリと、2人の従業員の更新されたコミッションの2つの変更されたコミッションレコードです。また、 empchglog 表には、トリガーが合計で4回発射されたことが示されています。
最後に、両方の従業員が1つの DELETE コマンドで 削除され ます。 empchglog テーブルは現在、トリガーが削除された各従業員のために1回、2回解雇された示しています。
Advanced Serverは、Oracleパッケージとの互換性を提供するパッケージのコレクションを提供します 。
パッケージ識別子- パッケージは、 一般的な修飾子を使用して参照されている関数、プロシージャ、変数、カーソル、ユーザー定義のレコードタイプ、およびレコードの名前付きコレクションです。 パッケージには次の特徴があります。
• |
パッケージ内の特定の関数、プロシージャ、変数、型などは public として宣言できます 。パブリック・エンティティーは表示され、パッケージに対する EXECUTE特権が与えられている他のプログラムから参照できます。パブリック関数とプロシージャーの場合、プログラム名、パラメーター(存在する場合)、関数の戻り値のタイプのみが表示されます。これらのファンクションとプロシージャの SPLコードには他人からアクセスできないため、パッケージを利用するアプリケーションは、手続き型ロジック自体ではなく、シグネチャで利用可能な情報のみに依存します。 |
この章では、オブジェクト指向プログラミング手法を SPLで どのように活用できるかについて説明します 。 JavaやC ++などのプログラミング言語に見られるオブジェクト指向プログラミングは、オブジェクトの概念を中心にしています。
オブジェクトは、人、場所、物などの実世界のエンティティの表現です。例えば、人物などの特定のオブジェクトの一般的な記述または定義は、
オブジェクトタイプと呼ばれる。 「ジョー」や「サリー」などの特定の人物
は、オブジェクトタイプ 、人物、またはそれと同等にオブジェクトタイプ、人物、または単に人物オブジェクトの
インスタンスであると言われています。
注:この時点までにこの文書で使用されていた「データベースオブジェクト」および「オブジェクト」という用語を、この章で使用されているオブジェクトタイプおよびオブジェクトと混同しないでください。これらの用語の以前の使用法は、表、ビュー、索引、ユーザーなどのデータベースに作成できるエンティティに関連しています。この章では、オブジェクト型およびオブジェクトは、
SPLプログラミングでサポートされる特定のデータ構造を参照しますオブジェクト指向の概念を実装するための言語です。
注意: Oracleでは、PL / SQLのオブジェクト型を記述するために
抽象データ型 (ADT)という用語が使用されています。オブジェクト型のSPL実装は、Oracle抽象データ型との互換性を目的としています。
注: Advanced Serverは、オブジェクト指向プログラミング言語のいくつかの機能をまだサポートしていません。この章では、実装されている機能についてのみ説明します。
• |
属性 - オブジェクトインスタンスの特定の特性を記述するフィールド。人物の場合、名前、住所、性別、生年月日、身長、体重、目の色、職業などがその例です。 |
• |
メソッド - オブジェクトに対して何らかのタイプの機能または操作を実行するプログラム、またはオブジェクトに関連するプログラム。 personオブジェクトの場合、その例は、その人の年齢の計算、personの属性の表示、personの属性に割り当てられた値の変更などです。 |
• |
メンバメソッド - オブジェクトインスタンスのコンテキスト内で動作するプロシージャまたは関数。メンバメソッドは、それらが動作しているオブジェクトインスタンスの属性にアクセスし、変更することができます。 |
• |
静的メソッド - 特定のオブジェクトインスタンスとは独立して動作するプロシージャまたは関数。静的メソッドは、オブジェクトインスタンスの属性にアクセスすることはできず、オブジェクトインスタンスの属性を変更することもできません。 |
• |
コンストラクタメソッド - オブジェクト型のインスタンスを作成するために使用される関数。オブジェクト型が定義されると、デフォルトのコンストラクタメソッドが常に提供されます。 |
• |
オブジェクトタイプの仕様 -これは、オブジェクト・タイプの属性およびメソッドのシグネチャを特定するパブリックインターフェースです。 |
• |
オブジェクト型体 -これはオブジェクトタイプの仕様で指定されたメソッドの実装を含んでいます。 |
ここで、 method_specは次のとおりです。
ここで、 subprogram_specは次のとおりです。
注: 現在、 OR REPLACE オプションを使用して 、既存のオブジェクト型の属性
を追加、削除、または変更することはできません 。既存のオブジェクトタイプを最初に削除するには、
DROP TYPEコマンドを使用します。
OR REPLACEオプションを使用すると、既存のオブジェクト型のメソッドを追加、削除、または変更できます。
注: PostgreSQL形式の
ALTER TYPE ALTER ATTRIBUTEコマンドを使用すると、既存のオブジェクト型の属性のデータ型を変更できます。ただし、
ALTER TYPEコマンドはオブジェクト型の属性を追加または削除できません。
nameは、オブジェクト型に割り当てられた識別子(オプションでスキーマ修飾名)です。
場合 AUTHID 句が省略されているか DEFINERが 指定されている、オブジェクト型の所有者の権利は、データベース・オブジェクトへのアクセス権限を決定するために使用されています。 CURRENT_USERが 指定されている 場合 、オブジェクトにメソッドを実行し、現在のユーザーの権限は、アクセス権限を決定するために使用されます 。
属性は、オブジェクト型の属性に割り当てられた識別子です。
CREATE TYPE定義
の閉じ括弧に続いて 、
[NOT] FINALは、このオブジェクト型からサブタイプを派生できるかどうかを指定します。デフォルトの
FINALは、このオブジェクト型からサブタイプを派生できないことを意味します。このオブジェクト型でサブタイプを定義できるようにする場合は、
NOT FINALを指定します。
注: NOT FINALの指定が
CREATE TYPEコマンドで受け入れられても、SPLは現時点ではサブタイプの作成をサポートしていません。
[NOT] INSTANTIABLE は、 CREATE TYPE定義
の閉じ括弧の後に、このオブジェクト型のオブジェクトインスタンスを作成できるかどうかを指定します。
INSTANTIABLE (デフォルト)は、このオブジェクト型のインスタンスを作成できることを意味します。このオブジェクトタイプが、他の特殊なサブタイプを定義する親 "テンプレート"としてのみ使用される場合は、
NOT INSTANTIABLEを指定します。
NOT INSTANTIABLEが指定されている場合は、
NOT FINALも指定する必要があります。オブジェクト型のいずれかのメソッドに
NOT INSTANTIABLE修飾子が含まれている場合、オブジェクト型自体は
NOT INSTANTIABLEおよび
NOT FINALで定義する必要があります。
注: NOT INSTANTIABLEの指定が
CREATE TYPEコマンドで受け入れられても、SPLは現時点ではサブタイプの作成をサポートしていません。
メソッドの定義の前に、 [NOT] FINALは、そのメソッドがサブタイプでオーバーライドできるかどうかを指定します。
NOT FINALは、メソッドがサブタイプでオーバーライドできるデフォルトの意味です。
メソッドの定義の前に、メソッドがスーパータイプ内の同じ名前のメソッドをオーバーライドする場合は、
OVERRIDINGを 指定します 。オーバーライドするメソッドは、同一のデータ型とパラメーター・モードを持つ同名のメソッド・パラメーターと同じ数の同じ順序で、スーパー・タイプで定義されている同じ戻りタイプ(メソッドが関数の場合)を持たなければなりません。
メソッドの定義の前に、 [NOT] INSTANTIABLEは、オブジェクト型定義がメソッドの実装を提供するかどうかを指定します。
INSTANTIABLEが指定されている場合、オブジェクト型の
CREATE TYPE BODYコマンドは、メソッドの実装を指定する必要があります。
NOT INSTANTIABLEが指定されている場合、オブジェクト型の
CREATE TYPE BODYコマンドにメソッドの実装が含まれていてはなりません。後者の場合、このオブジェクト型のメソッドをオーバーライドして、サブタイプにメソッドの実装が含まれているとみなされます。オブジェクト型に
NOT INSTANTIABLEメソッドがある場合、オブジェクト型定義自体は、オブジェクト型指定の終了括弧の後に
NOT INSTANTIABLEおよび
NOT FINALを指定する必要があります。デフォルトは
INSTANTIABLEです。
subprogram_specは、手続きまたは関数の指定を表し、
MEMBERまたは
STATICのいずれかの指定で始まります。特定のオブジェクト・インスタンスに対してメンバ・サブプログラムを起動する必要がありますが、静的サブプログラムは任意のオブジェクト・インスタンスに対して起動しません。
proc_nameはプロシージャの識別子です。
SELFパラメーターが指定されている場合、
nameは
CREATE TYPEコマンドで指定されたオブジェクト・タイプ名です。指定すると、
parm1 、
parm2 、...はプロシージャの仮パラメータです。
datatype1 、
datatype2 、...はそれぞれ
parm1 、
parm2 、...のデータ型です。
IN 、
IN OUT 、および
OUTは、各仮パラメータの可能なパラメータ・モードです。指定されていない場合、デフォルトは
INです。
value1 、
value2 、...は
INパラメータに指定できるデフォルト値です。
コンストラクタ関数を定義するには 、 CONSTRUCTOR キーワードと関数定義を 含めます 。
func_name は関数の識別子です。 SELF パラメーターが指定されている 場合 、 name は CREATE TYPE コマンドで 指定され たオブジェクト・タイプ名 です。指定すると、 parm1 、 parm2 、...は関数の仮パラメータです。
datatype1 、
datatype2 、...はそれぞれ
parm1 、
parm2 、...のデータ型です。
IN 、
IN OUT 、および
OUTは、各仮パラメータの可能なパラメータ・モードです。指定されていない場合、デフォルトは
INです。
value1 、
value2 、...は
INパラメータに指定できるデフォルト値です。
return_typeは、関数が返す値のデータ型です。
SELFは、現在メソッドを呼び出すオブジェクトインスタンスを参照します。
SELFは、パラメータリスト内の
INまたは
IN OUTパラメータとして明示的に宣言できます(たとえば、
MEMBER FUNCTION(SELF IN OUT object_type ...)など) 。
場合 SELFは明示的に宣言され
、SELFは、パラメータリストの最初のパラメータでなければなりません。
SELFが明示的に宣言されていない場合、そのパラメーター・モードのデフォルトはメンバー・プロシージャーの場合は
IN OUT 、メンバー関数の場合は
INになります。
ここで、 method_specは次のとおりです。
そして subprogram_specは以下の通りであります:
name は、オブジェクト型に割り当てられた識別子(オプションでスキーマ修飾名)です。
method_specは、
CREATE TYPEコマンドで指定されたインスタンス化可能なメソッドの実装を示します。
CREATE TYPEコマンドの
method_specで
INSTANTIABLEが指定または省略された
場合 、
CREATE TYPE BODYコマンドにはこのメソッドの
method_specが必要です。
場合は 、NOT INSTANTIABLEは 、CREATE TYPEコマンドの
method_specに指定されました、そして
TYPEをCREATE BODYコマンドで、この方法には
method_specがあってはなりません。
subprogram_specは、手続きまたは関数の指定を表し、
MEMBERまたは
STATICのいずれかの指定で始まります。
CREATE TYPEコマンドの
subprogram_specで指定されているのと同じ修飾子を使用する必要があります。
proc_nameは、
CREATE TYPEコマンドで指定されたプロシージャーのIDです。パラメータ宣言は
、TYPEをCREATEコマンドについて説明したのと同様の意味を持ち、そして
TYPEのCREATE コマンド で指定したのと同じ
方法で
、CREATE TYPEのBODYコマンドで指定する必要があります
。
コンストラクタ関数を定義するには 、 CONSTRUCTOR キーワードと関数定義を 含めます 。
func_name は、 CREATE TYPE コマンドで 指定された関数のIDです 。パラメータ宣言は 、TYPEをCREATEコマンド
について説明したのと同様の意味を持ち 、そして
TYPEのCREATEコマンドで指定したのと同じ方法で
、CREATE TYPEのBODYコマンドで指定する必要があります。
return_typeは、関数が返す値のデータ型であり、
CREATE TYPEコマンドで指定された
return_typeと一致する必要があります。
宣言 は、変数、カーソル、型、または副プログラムの宣言です。サブプログラム宣言が含まれている場合は、他のすべての変数宣言、カーソル宣言、および型宣言の後に宣言する必要があります。
あなたは使用することができ 、オブジェクト型本体を作成するには 、オブジェクト型の仕様を作成するために、TYPEコマンドを 作成し 、CREATE TYPEのBODY コマンド 。このセクションでは、 CREATE TYPE および CREATE タイプ BODY コマンド。
最初の例では、 属性のみを含みメソッドは含まない addr_object_type オブジェクト型を 作成し ます。
オブジェクト型 emp_obj_typには、
display_empという名前のメンバ・メソッドが含まれています。
display _
empは、メソッドが呼び出されたオブジェクトインスタンスを渡す
SELFパラメータを使用します。
SELFパラメータは、データ型が定義されているオブジェクトタイプのものであるパラメータです。 SELFは、常にメソッドを呼び出すインスタンスを参照します。 SELFパラメーターは、パラメーター・リストで明示的に宣言されているかどうかに関係なく 、メンバー・プロシージャーまたは関数の最初のパラメーターです。
オブジェクトタイプ本体で
SELFパラメータを
使用することもできます。
SELFパラメータが
CREATE TYPE BODYコマンドでどのように使用されるかを説明するために、前のオブジェクト型本体を次のように記述することができます。
Sの tatic方法はへのアクセス権を持たない、およびオブジェクト・インスタンスの属性を変更することができず、典型的にはタイプのインスタンスでは動作しません。
オブジェクト型本体 dept_obj_typは get_dnameと
display_deptという名前のメンバ手順名前静的関数を定義します。
静的関数 get_dnameには 、
SELFへの参照はありません。静的関数は任意のオブジェクトインスタンスから独立して呼び出されるため、任意のオブジェクト属性への暗黙的なアクセスはありません。
メンバー・プロシージャーの display_deptは、
SELFパラメーターで渡されたオブジェクト・インスタンスの
deptno属性にアクセスできます。
display_deptパラメータリストで
SELFパラメータを明示的に宣言する必要はありません。
display_deptプロシージャ
の最後の DBMS_OUTPUT.PUT_LINE文には、静的関数
get_dname (オブジェクト型名
dept_obj_typで修飾 )のコールが含まれています。
たとえば、 address という名前の型を定義すると 、各コンストラクタの名前は
addressになります 。同じ名前で異なる引数型を持つ1つ以上の異なるコンストラクタ関数を作成して、コンストラクタをオーバーロードすることができます。
object は、オブジェクト変数に割り当てられた識別子です。
[ 新規 ] obj_type ({expr1 | NULL} [、 {expr2 | NULL} ] [、...])
obj_typeは、オブジェクト型のコンストラクタメソッドの識別子です。コンストラクタ・メソッドは、以前に宣言されたオブジェクト型と同じ名前を持ちます。
expr1 、
expr2 、...は、オブジェクト型の最初の属性、オブジェクト型の2番目の属性などと型互換性のある式です。属性がオブジェクト型の場合、対応する式は
NULL 、オブジェクト初期化式、またはそのオブジェクト型を返す式。
変数( v_emp )は、以前に定義された
EMP _
OBJ _
TYPEというオブジェクト型で宣言されます。ブロックの本体は、
emp_obj_typおよび
addr_obj_typeコンストラクタを使用して変数を初期化します。
ブロックの本文にオブジェクトの新しいインスタンスを作成する場合
は、 NEWキーワード
を含めることができます 。
NEWキーワードは、指定された引数と一致するシグネチャを持つオブジェクトコンストラクタを呼び出します。
次の例では、 mgrと
emp という2つの変数を宣言しています 。変数は両方とも
EMP_OBJ_TYPEです。
mgrオブジェクトは宣言で初期化され、empオブジェクトは宣言で
NULLに初期化され、本文に値が割り当てられます。
注意: Advanced Serverでは、コンストラクタメソッドの代わりに次の代替構文を使用できます。
ROWは、括弧で囲まれたカンマ区切りのリスト内に複数の用語が指定されている場合、オプションのキーワードです。用語が1つしか指定されていない場合、
ROWキーワードの指定は必須です。
objectは、オブジェクト変数に割り当てられた識別子です。
属性は、オブジェクト型属性の識別子です。
場合 属性は 、それ自体が、オブジェクト型である場合、参照は形を取る必要があります。
objectは、オブジェクト変数に割り当てられた識別子です。
prog_nameは、プロシージャーまたは関数のIDです。
object_typeは、オブジェクト型に割り当てられた識別子です。
prog_nameは、プロシージャーまたは関数のIDです。
dept_obj_typで 定義された静的関数は、オブジェクト型名で次のよう
に 修飾することで直接
呼び出すことができます。
objtypeは、削除するオブジェクト型の識別子です。
objtypeの定義自体にオブジェクト型またはコレクション型の属性が含まれている場合、これらの入れ子になったオブジェクト型またはコレクション型を最後に削除する必要があります。
次の例では、この章の前半で作成し
た emp_obj_typおよび
addr_obj_typオブジェクト型を
削除します。
emp_obj_typは属性としてその定義内に
addr_obj_typを含むため、最初に
削除する必要があります。
以前は今、アプリケーション・コードを変更せずに、最小限にEDBのPostgres Advanced ServerまたはOracleデータベースのいずれかで動作することができ、「固定」されたアプリケーション- オープンクライアントライブラリでは、Oracle Call Interfaceのでアプリケーションの相互運用性を提供します。 Open Client LibraryのEnterpriseDB実装はC言語で記述されています。
次の図は、 Open Client Libraryと
Oracle Call Interfaceのアプリケーション・スタックを
比較したものです。
オラクル・カタログ・ビューは、Oracleデータ・ディクショナリ・ビューと互換性のある方法で、データベースオブジェクトに関する情報を提供します。サポートされているビューに関する情報は、 Oracle Developer's Reference GuideのDatabase Compatibilityで入手できます。
注意: この文書とこの章で説明特にパーティショニングは、PostgreSQL の宣言型のパーティショニングは、Oracleデータベースと互換性のある表のパーティション化に加えて、高度なサーバー10にサポートされていることをPostgreSQLバージョン10注意して導入された 宣言型のパーティショニング 機能を、 説明しません この章で説明します。宣言型パーティショニングの詳細については、次のURLにあるPostgreSQLのコアドキュメントを参照してください。
PostgreSQL 9.6 INSERT ... ON CONFLICT DO NOTHING / UPDATE句(一般にUPSERTとして知られています)は、Oracleスタイルのパーティションテーブルではサポートされていません。パーティション表にデータを追加するために
INSERTコマンドを呼び出すときに
ON CONFLICT DO NOTHING / UPDATE文節を組み込むと、サーバーはエラーを戻します。
パーティション表を作成するときは、 LIST 、
RANGE 、または
HASHの区画化規則
を指定します 。パーティション化ルールは、各パーティションに格納されているデータを定義する一連の制約を提供します。新しい行がパーティション表に追加されると、サーバーはパーティション化ルールを使用して、各行を含むパーティションを決定します。
Advanced Serverのクエリプランナは、 パーティション プルーニングを使用して、
SELECT文の
WHERE句で指定された条件に一致する行を特定する効率的な計画を計算します。
WHERE句は、実行計画からパーティションを正常にプルーニングするには、パーティション化された表の作成時に指定されたパーティション化キー列と比較される情報を制約する必要があります。 aを照会するとき:
制約 _ 除外パラメータは、制約による除外を制御します。 制約 _ 除外パラメータは、 オン 、 オフ 、またはパーティションの値を有することができます。制約除外を有効にするには、パラメータをpartitionまたはonの いずれかに設定する必要があります。デフォルトでは、パラメータはpartitionに設定されています。
WHERE句を含ま
ない SELECT文
を実行する場合 、クエリプランナはテーブル全体を検索する実行計画を推奨する必要があります。あなたが
WHERE句を含ま
ない SELECT文を実行すると、クエリプランナは、その行が格納されるであろうパーティションに決定し、実行計画からその行を含めることができませんでしたパーティションをプルーニング、そのパーティションにクエリフラグメントを送信します。パーティション表を使用していない場合、制約除外を使用不可にすると、パフォーマンスが向上する可能性があります。
(
PARTITIONアメリカのVALUES( 'US'、 'CA'、 'MX')、
PARTITION europe VALUES( 'BE'、 'NL'、 'FR')、
PARTITION asia VALUES( 'JP'、 'PK'、 'CN')、
PARTITIONその他の値VALUES(DEFAULT)
)
最初に与えられた 国=「米国」:これらのパーティションは、修飾子を満たす行を保持することはできませんので
、WHERE句、高速の剪定は、パーティション
ヨーロッパ 、
アジア 、および
他を排除するであろう。
第二与えられたこれらのパーティションは、
国が NULL ISの行を保持することはできませんので
、WHERE句、高速の剪定は、パーティションの
米州 、
欧州 、
アジアを排除するであろう。
WHERE節で
指定された演算子は、等号(
= )または分割列のデータ型に適した等価演算子でなければなりません。
EXPLAIN文は、文の実行計画を表示します。 EXPLAIN文を使用すると、Advanced Serverがクエリの実行計画からパーティションをプルーニングすることを確認できます。
PARTITION "2012" VALUES LESS THAN('01 -JAN-2013' )
CREATE TABLEコマンド
の PARTITION BY句を
使用して、 1つ以上のパーティション(およびサブパーティション)に分散されたデータを含むパーティション表を作成します。コマンド構文は次の形式で提供されます。
( list_partition_definition [、list_partition_definition] ... );
where list_partition_definition 次のとおりです。
CREATE TABLE [ スキーマ 。 ] テーブル名
table_definition
PARTITION BY RANGE( 列 [、 列 ] ...)
( range_partition_definition [、range_partition_definition] ... );
どこ range_partition_definitionは以下
のとおりです。
PARTITION BY HASH( 列 [、 列 ] ...)
[SUBPARTITION BY {RANGE | LIST | HASH}( 列 [、 列 ] ...)]
( hash_partition_definition [、 hash_partition_definition ] ...);
どこで hash_partition_definitionは次の
とおりです。
{ list _ subpartition | 範囲 _ サブパーティション | hash_subpartition }
ここで、 list _ サブパーティションは次のとおりです。
どこ 範囲 _ サブパーティションは次
のようになります。
ここで、 hash_subpartitionは次の
とおりです。
コマンドBY CREATE TABLE ... PARTITIONは、1つ以上のパーティションを持つ表を作成します。各パーティションは1つ以上のサブパーティションを持つことができます。定義されたパーティションの数に上限はありませんが、 PARTITION BY句を含める場合は、少なくとも1つのパーティション化ルールを指定する必要があります。結果として得られるテーブルは、それを作成するユーザが所有します。
指定された列に入力された値に基づいて、表を区画に分割
するには、 PARTITION BY LIST節を
使用します。各パーティション化ルールでは、少なくとも1つのリテラル値を指定する必要がありますが、指定可能な値の数に上限はありません。指定されていない行を指定されたパーティションに
送るDEFAULTという一致する値を指定するルールを組み込みます。
DEFAULTキーワードの使用方法の詳細は、第
10.4項を参照してください。
パーティションを作成する境界ルールを指定
するには、 PARTITION BY RANGE句を
使用します。各パーティション化ルールには、2つの演算子(つまり、より大きいまたは等しい演算子、およびより小さい演算子)を持つデータ型の列が少なくとも1つ含まれている必要があります。範囲境界は、
LESS THAN節に対して評価され、非包含的である。 2013年1月1日の日付の境界には、2012年12月31日以前の日付の値のみが含まれます。
範囲パーティションのルールは、昇順で指定する必要があります。パーティション分割ルールに
MAXVALUEの値を指定する境界ルールが含まれていない限り、範囲パーティション化テーブルの最上位境界を超える値を持つ行を格納する
INSERTコマンドは失敗します
。 MAXVALUEパーティション化ルールを含めない場合、境界ルールで指定された最大限度を超える行はエラーになります。
PARTITIONを 使用する によって HASH 句を使用してハッシュ・パーティション表を作成します。 ハッシュ ・パーティション表 では 、データは、分割構文で指定された列のハッシュ値に基づいて、同じサイズのパーティション間で分割されています。 HASH パーティションを 指定するとき は、できるだけ一意に近い列(または列の組み合わせ)を選択して、データがパーティション間で均等に分散されるようにします。パーティション化列(または列の組み合わせ)を選択するときは、パフォーマンスを最大限にするために頻繁に一致するものを頻繁に検索する列を選択します。
TABLESPACEキーワードを
使用して、パーティションまたはサブパーティションが存在する表スペースの名前を指定します。表領域を指定しないと、パーティションまたはサブパーティションはデフォルト表領域に常駐します。
表定義に SUBPARTITION BY句が
含まれている場合、その表内の各パーティションには少なくとも1つのサブパーティションが存在します。各サブパーティションは、明示的に定義することも、システム定義することもできます。
• |
SUBPARTITION 場合 、デフォルトの サブパーティション BY 節は LISTを 指定します 。
|
• |
SUBPARTITION であれば MAXVALUE サブ パーティション BY 節は RANGEを 指定します 。 |
値を
使用して、表エントリをパーティションにグループ化する引用符付きリテラル値(またはリテラル値のコンマ区切りリスト)を指定します。各パーティション化ルールは少なくとも1つの値を指定する必要がありますが、ルール内で指定された値の数に制限はありません。
値は
NULL 、
DEFAULT (
LISTパーティションを指定する場合)、または
MAXVALUE (
RANGEパーティションを指定する場合)です。
リスト・パーティション表のルールを指定するときは、最後のパーティション・ルールに
DEFAULTキーワードを
組み込んで 、 不一致の行を指定されたパーティションに転送します。
DEFAULTの値を含むルールを含めない場合、少なくとも1つのパーティションの指定されたルールと一致しない行を追加しようとする
INSERTステートメントは失敗し、エラーを返します。
リスト・パーティション表のルールを指定するときは、最後のパーティション・ルールに
MAXVALUEキーワードを
組み込んで、分類されていない行を指定されたパーティションに誘導してください。
MAXVALUE区画を含めない場合、区画キーが指定された最大値より大きい行を追加しようとする
INSERT文は失敗し、エラーが戻されます。
次の例では 、
PARTITION BY LIST句を使用して
パーティション表( sales )を
作成します 。
sales表は、3つのパーティション(
ヨーロッパ 、
アジア 、
南北アメリカ )で情報を格納します。
• |
値を持つ行 の国の欄で 、米国や カナダは アメリカのパーティションに格納されています。 |
• |
国の列にある INDIAまたは PAKISTANの 値を持つ行は、 asiaパーティションに格納されます。 |
• |
国の列 に FRANCEまたは ITALYの 値を持つ行は、 ヨーロッパの区画に格納されます。 |
次の例では 、
PARTITION BY RANGE句を使用して
パーティション表( sales )を
作成します 。
salesテーブルは、4つのパーティション(
q1_2012 、
q2_2012 、
q3_2012 、および
q4_2012 )に情報を格納します。
• |
2012年4月1日より前 の 日付列の 値を持つ行は、 q1_ 2012という名前のパーティションに格納されます。 |
• |
2012年7月1日より前 の 日付列の 値を持つ行は、 q2_ 2012という名前のパーティションに格納されます。 |
|
•
|
2012年10月1日より前 の 日付列の 値を持つ行は、 q3_ 2012という名前のパーティションに格納されます。 |
• |
2013年1月1日より前 の 日付列の 値を持つ行は、 q4_ 2012という名前のパーティションに格納されます。 |
次の例では 、
PARTITION BY HASH節を使用して
パーティション表( sales )を
作成します 。
salesテーブルは、3つのパーティション(
p1 、
p2 、および
p3 :
次の例では 、トランザクション日によって最初にパーティション化され
たパーティション表( sales )を
作成します。範囲
列 (
q1_2012 、
q2_2012、q3_2012 、および
q4_2012 )は、
国の列の値を使用してリストサブパーティション化されます。
行がこの表に追加されると、 日付列の値が範囲区画化規則で指定された値と比較され、サーバーは行が常駐すべき区画を選択します。
国の列の値は、リストのサブパーティション化ルールで指定された値と比較されます。サーバーが値の一致を検出すると、行は対応するサブパーティションに保管されます。
既存のパーティション表にパーティションを追加
するには、 ALTER TABLE ...
ADD PARTITIONコマンドを
使用します。構文は次のとおりです。
ここで、 partition_definitionは次のとおりです。
{ list_partition | range_partition }
そして リスト _ パーティションは次のとおりです。
そして range_partitionは以下
のとおりです。
{ list _ subpartition | 範囲 _ サブパーティション| hash_subpartition }
そして リスト _ サブパーティションは以下
のとおりです。
そして 範囲 _ サブパーティションは次
のようになります。
ALTER TABLEは... PARTITIONコマンドを追加し、既存のパーティション表にパーティションを追加します。パーティション化された表には、定義された区画の数に上限はありません。
ALTER TABLE ...
ADD PARTITIONステートメントを
使用して、表の既存の行と追加する区画の値との間に競合する値がない限り、
DEFAULT規則を持つ表に区画を追加する
ことができます 。
ALTER TABLE ...
ADD PARTITIONステートメントを
使用して、
MAXVALUEルールを持つ表にパーティションを追加する
ことはできません 。
または、 ALTER TABLE ...
SPLIT PARTITIONステートメントを
使用して既存のパーティションを分割し、効果的にテーブル内のパーティション数を増やすことができます。
RANGEパーティションは昇順で指定する必要があります。
RANGEパーティション表の既存のパーティションに先行する新しいパーティションを追加することはできません。
新しいパーティションが存在するテーブルスペースを指定するには
、 TABLESPACE句を
含めます。表領域を指定しない場合、そのパーティションはデフォルトの表領域に常駐します。
ALTER TABLE ... ADD PARTITIONコマンド
を使用するには 、表の所有者であるか、スーパーユーザー(または管理者)権限が必要です。
値を
使用して、行がパーティションに分散される引用符付きリテラル値(またはリテラル値のカンマ区切りリスト)を指定します。各パーティション化ルールは少なくとも1つの
値を指定する必要がありますが、ルール内で指定された値の数に制限はありません。
値は
NULL 、
DEFAULT (
LISTパーティションを指定する場合)、または
MAXVALUE (
RANGEパーティションを指定する場合)でもかまいません。
ALTER TABLEは... SUBPARTITIONコマンドを追加し、既存のサブパーティションのパーティションにサブパーティションを追加します。構文は次のとおりです。
ALTER TABLE table _ name MODIFY PARTITION パーティション _ name
ADD SUBPARTITION サブパーティション _ 定義;
ここで、 subpartition_definitionは次のとおりです。
{ list_subpartition | range_subpartition }
そして リスト _ サブパーティションは以下
のとおりです。
そして range_subpartitionは以下
のとおりです。
ALTER TABLEは... SUBPARTITIONコマンドを追加し、既存のパーティションにサブパーティションを追加します。パーティションはすでにサブパーティション化されている必要があります。定義されたサブパーティションの数に上限はありません。
あなたは使用することができます ALTER TABLEを ...限り、追加する既存のテーブルの行とサブパーティションの値の間に矛盾する値が存在しないように
、デフォルトのルールを持つテーブルにサブパーティションを追加する
SUBPARTITION文を
追加します 。
MAXVALUEルールを持つ表にサブパーティションを追加
するには、 ALTER TABLE ...
ADD SUBPARTITIONステートメントを
使用することはできません 。
サブパーティションが存在する表領域を指定するには
、 TABLESPACE句を
含めます。表領域を指定しないと、サブパーティションはデフォルトの表領域に作成されます。
ALTER TABLE ... ADD SUBPARTITIONコマンド
を使用するには 、テーブル所有者であるか、スーパーユーザー(または管理者)権限を持っている必要があります。
値を
使用して、表エントリをパーティションにグループ化する引用符付きリテラル値(またはリテラル値のコンマ区切りリスト)を指定します。各パーティション化ルールは少なくとも1つの値を指定する必要がありますが、ルール内で指定された値の数に制限はありません。
値は
NULL 、
DEFAULT (
LISTパーティションを指定する場合)、または
MAXVALUE (
RANGEパーティションを指定する場合)でもかまいません。
次の例では、 RANGEサブパーティションをリスト分割された
sales表に
追加します。
salesテーブルは次のコマンドで作成されました。
sales表には3つのパーティション、名前のヨーロッパ、アジア、 南北アメリカを持っています。各パーティションには、2つの範囲定義されたサブパーティションがあります。
次の例では、 LISTサブパーティションを
RANGEパーティション化された
sales表に
追加します。
salesテーブルは次のコマンドで作成されました。
PARTITION second_half_2012 VALUES LESS THAN('01-JAN-2013 ') (
上記のコマンドを実行すると、 salesテーブルには
first_half_2012と
second_half_2012の 2つのパーティションがあり
ます 。
first_half_2012パーティションは、
ヨーロッパと
アメリカという名前の2つのサブパーティションを、有し、
第2 _ _
半分 2012パーティションは、
アジアという名前の、一つのパーティションがあります。
ALTER TABLE ...
SPLIT PARTITIONコマンドを
使用して 、1つのパーティションを2つのパーティションに分割し、新しいパーティション間でパーティションの内容を再配布します。コマンド構文には2つの形式があります。
最初の形式は、 RANGEパーティションを2つのパーティションに分割します。
ALTER TABLE table _ name SPLIT PARTITION パーティション _ name
AT( 範囲 _ 部分 _ 値 )
に
(
PARTITION new_part1
[TABLESPACE tablespace_name ] 、
PARTITION new_part2
[TABLESPACE tablespace_name ]
);
ALTER TABLE table _ name SPLIT PARTITION パーティション _ name
VALUES( 値 [、 値 ] ...)
に
(
PARTITION new_part1
[TABLESPACE tablespace_name ] 、
PARTITION new_part2
[TABLESPACE tablespace_name ]
);
ALTER TABLE ... SPLIT PARTITION の コマンドは、既存のリストまたは範囲パーティション表にパーティションを追加します。 ALTER TABLE ... SPLIT PARTITIONコマンドは、パーティションをHASHパーティション表に追加できないことに注意してください。表が持つ可能性があるパーティションの数に上限はありません。
ALTER TABLE ... SPLIT PARTITIONコマンド
を実行すると 、Advanced Serverは2つの新しいパーティションを作成し、それらの間に古いパーティションの内容を再分配します(パーティション化ルールによって制約されます)。
パーティションが存在する表領域を指定するには
、 TABLESPACE句を
含めます。表領域を指定しない場合、そのパーティションはデフォルトの表領域に常駐します。
ALTER TABLE ... SPLIT PARTITIONコマンド
を使用するには 、テーブル所有者であるか、スーパーユーザー(または管理者)権限を持っている必要があります。
new_part1は、
ALTER TABLE ... SPLIT PARTITIONコマンドで指定されたパーティション制約を満たす行を受け取ります。
new_part2は、
ALTER TABLE ... SPLIT PARTITIONコマンドで指定されたパーティション化制約によって
new_part1に行が
送られることはありません。
range_part_valueを
使用して、新しいパーティションを作成する境界の規則を指定します。パーティション化ルールには、2つの演算子(つまり、より大きいか等しい演算子、およびより小さい演算子)を持つデータ型の列が少なくとも1つ含まれている必要があります。範囲境界は、
LESS THAN節に対して評価され、非包含的である。 2010年1月1日の日付境界には、2009年12月31日以前の日付値のみが含まれます。
値を
使用して、行がパーティションに分散される引用符付きリテラル値(またはリテラル値のカンマ区切りリスト)を指定します。各パーティション化ルールは少なくとも1つの値を指定する必要がありますが、ルール内で指定された値の数に制限はありません。
次のコマンドは、 americasパーティションを
usと
canadaという2つのパーティションに分割します。
SELECT文では、行が再配布されていることを確認しました。
この例では、レンジ・パーティション化された
sales表
の q4_2012パーティションを2つのパーティションに分割し、パーティションの内容を再配布します。
salesテーブルを作成するには、次のコマンドを使用します。
SELECT文では、期待通りに行がパーティション間で分散されていることを確認しました。
次のコマンドは、 q4_2012パーティションを
q4_2012_p1と
q4_2012_p2の 2つのパーティションに分割し
ます 。
SELECT文では、行が新しいパーティションに再分散されていることを確認しました。
ALTER TABLE ...
SPLIT SUBPARTITIONコマンドを
使用して 、単一のサブパーティションを2つのサブパーティションに分割し、サブパーティションの内容を再配布します。コマンドには2つのバリエーションがあります。
ALTER TABLE table _ name SPLIT SUBPARTITION サブパーティション _ name
AT( 範囲 _ 部分 _ 値 )
に
(
SUBPARTITION new _ subpart1
[TABLESPACE 表スペース _ 名前 ]、
SUBPARTITION new _ subpart2
[TABLESPACE tablespace _ name ]
);
ALTER TABLE table _ name SPLIT SUBPARTITION サブパーティション _ name
VALUES( 値 [、 値 ] ...)
に
(
SUBPARTITION new _ subpart1
[TABLESPACE 表スペース _ 名前 ]、
SUBPARTITION new _ subpart2
[TABLESPACE tablespace _ name ]
);
ALTER TABLE ... SPLITの SUBPARTITIONコマンドは、既存のサブパーティションテーブルにサブパーティションを追加します。定義されたサブパーティションの数に上限はありません。 ALTER TABLE ... SPLIT SUBPARTITIONコマンドを実行すると、Advanced Serverは2つの新しいサブパーティションを作成し、指定されたサブパーティション・ルールによって制約された値を含む行をnew_subpart1に 、残りの行をnew_subpart2に移動します。
新しいサブパーティションが存在する表領域を指定するには
、 TABLESPACE句を
含めます。表領域を指定しないと、サブパーティションはデフォルトの表領域に作成されます。
ALTER TABLE ... SPLIT SUBPARTITIONコマンド
を使用するには 、テーブル所有者であるか、スーパーユーザー(または管理者)権限を持っている必要があります。
new_subpart1は、
ALTER TABLE ... SPLIT SUBPARTITIONコマンドで指定されたサブパーティション化制約を満たす行を受け取り
ます 。
new_subpart2は、行が
、ALTER TABLE ... SPLIT SUBPARTITIONコマンドで指定されたサブパーティションの制約により
new_subpart1するように指示されていない受信します。
値を
使用して、表エントリをパーティションにグループ化する引用符付きリテラル値(またはリテラル値のコンマ区切りリスト)を指定します。各パーティション化ルールは少なくとも1つの値を指定する必要がありますが、ルール内で指定された値の数に制限はありません。
値は、
NULL 、
DEFAULT (
LISTサブパーティションを指定する場合)、または
MAXVALUE (
RANGEサブパーティションを指定する場合)でもかまいません。
PARTITION second_half_2012 VALUES LESS THAN('01-JAN-2013 ') (
sales表には2つのパーティション、名前のfirst_half_2012、およびsecond_half_2012を持っています。各パーティションには、 国の列の値に基づいてパーティションの内容をサブパーティションに配布する2つの範囲定義されたサブパーティションがあります。
SELECT文では、行が正しくサブパーティション間で分散されていることを確認しました。
次のコマンドは、 p2_americasサブパーティションを2つの新しいサブパーティションに
分割し 、内容を再配布します。
コマンドを呼び出した後、 p2_americasサブパーティションが削除されました。その代わりに、サーバーは2つの新しいサブパーティション(
p2_usと
p2_canada )を作成しました。
照会 売上テーブルは
p2_americasサブパーティションの内容が再配布されていることを示しています。
sales表は、3つのパーティション( ヨーロッパ、アジア、 南北アメリカを )持っています。各パーティションには、 日付の列の値によってパーティションの内容をサブパーティションにソートする2つの範囲定義されたサブパーティションがあります。
SELECT文では、行がサブパーティション間で分散されていることを確認しました。
次のコマンドは、 americas_2012サブパーティションを2つの新しいサブパーティションに
分割し 、内容を再配布します。
コマンドを呼び出した後、 americas_2012サブパーティションが削除されました。その代わりに、サーバーは2つの新しいサブパーティション(
americas_p1_2012および
americas_p2_2012 )を作成しました。
sales表の
問合せは 、サブパーティションの内容が再配布されていることを示しています。
ALTER TABLEは... EXCHANGE PARTITIONのコマンド は、パーティションを既存のテーブルを交換します。 パーティション化された表に大量のデータを追加する場合は、 ALTER テーブル ... エクスチェンジ PARTITION コマンドを使用してバルクロードを実装します。 ALTERを 使用することもできます テーブル ... エクスチェンジ PARTITION コマンドを使用して、古いデータまたは不要なデータを保存用に削除します。
ALTER TABLE target_table
EXCHANGE PARTITION target_partition
WITH TABLE source_table
[(含む|除外する)インデクス]
ALTER TABLE target_table
交換 サブジェクトtarget_subpartition
WITH TABLE source_table
[(含む|除外する)インデクス]
ときに ALTER TABLE ...
EXCHANGE PARTITION の コマンドが完了し、元々
target_partitionに配置されたデータは
、SOURCE_TABLEに配置され、元々
SOURCE_TABLEに配置されたデータは
target_partitionに配置されます。
ALTER TABLE ... EXCHANGE PARTITION の コマンドは、LIST、RANGEまたはHASHパーティション表にパーティションを交換することができます。 source_tableの構造はtarget_tableの構造と一致していなければなりません(両方のテーブルが一致する列とデータ型を持たなければなりません)。また、テーブルに含まれるデータはパーティション制約に従わなければなりません。
場合 INCLUDING INDEXES句は
交換PARTITIONで指定され、その後
、target_partitionと
SOURCE_TABLEで一致するインデックスがスワップされます。
source_tableに一致のない
target_partition内のインデックスは再構築され、その逆も同様です(つまり、
target_partitionに一致しない
source_tableのインデックスも再構築されます)。
EXCHUDGE PARTITIONを指定し
て EXCLUDING INDEXES句を指定すると、
target_partitionと
source_tableの一致する索引がスワップされますが、
source_tableで一致しない
target_partition索引は無効として、逆も同様です(
source_tableの索引は一致しません
target_partitionの中にも無効としてマークされています)。
以前に使用された 照合索引用語は、照合順序、昇順または降順方向、最初のNULLの順序付けまたは最後のNULLの順序付けなど、
CREATE INDEXコマンドによって決定される同じ属性を持つ索引を指します。
INCLUDING INDEXESと
EXCLUDING INDEXの 両方が省略されている場合、デフォルトアクションは
除外索引の動作です。
照会 販売テーブルは1行のみ
アメリカパーティションに存在することを示しています。
照会 売上テーブルは
n_americaテーブルの内容は、
アメリカのパーティションの内容のために交換されたことを示しています。
照会 n_americaテーブルは、以前
アメリカパーティションに格納された行が
n_americaテーブルに移動されたことを示しています。
パーティションを別の表スペースに移動
するには、 ALTER TABLE ...
MOVE PARTITIONコマンドを
使用します。このコマンドには2つの形式があります。
ALTER TABLE テーブル _ 名前
MOVE PARTITION パーティション _ 名前
TABLESPACE 表スペース _ 名前 ;
ALTER TABLE テーブル _ 名前
MOVE SUBPARTITION サブパーティション _ name
TABLESPACE 表スペース _ 名前 ;
ALTER TABLE ... MOVE PARTITION コマンドは、パーティションを現在の表領域から別の表領域に移動します。 ALTER TABLE ... MOVE PARTITION コマンドは、 LIST 、 RANGE または HASH パーティション表の パーティションを移動でき ます。
照会 ALL _ _
TAB パーティションビューは、パーティションが期待されるサーバおよび表領域に常駐していることを確認します:
ターゲット表領域を準備した後、起動 ts_3という表領域に
TS_2という名前の表領域から
q1_2013パーティションを移動するには
、ALTER TABLE ...
MOVE PARTITION の コマンドを:
ALTER TABLE セールス MOVE PARTITION q1_2013 TABLESPACE ts_3;
照会 ALL _ _
TAB パーティションビューは、移動が成功したことを示しています。
ALTER TABLE ... RENAME PARTITIONコマンドを
使用して 、表パーティションの名前を変更します。構文には2つの形式があります。
ALTER TABLE テーブル _ 名前 RENAME PARTITION パーティション _ 名前 TO new _ name ;
ALTER TABLE テーブル _ 名前 RENAME SUBPARTITION サブパーティション _ name TO new _ name ;
ALTER TABLE ... PARTITIONコマンドの名前を変更するには、パーティションの名前を変更します。
前述の同じ動作が、
RENAME SUBPARTITION句で使用される
subpartition_nameに 適用され ます 。
照会パーティション名を表示するには
ALL _ _
TAB パーティションビューを:
ALTER TABLEの 売上 n_america TO PARTITIONの アメリカの 名前 を 変更 します 。
照会 ALL _ _
TAB パーティションビューは、パーティションが正常に名前が変更されていることを示しています。
PostgreSQLの DROP TABLEコマンドを
使用して 、パーティションテーブル定義、パーティションとサブパーティションを削除し、テーブルの内容を削除します。構文は次のとおりです。
DROP TABLEコマンドは、テーブル全体を削除し、そのテーブルに存在するデータ。表を削除すると、その表のパーティションまたはサブパーティションも削除されます。
DROP TABLEコマンド
を使用するには、パーティション・ルートの所有者、表を所有するグループのメンバー、スキーマ所有者、またはデータベース・スーパーユーザーである必要があります。
詳細については DROP TABLE コマンド 、でPostgreSQLのコアのドキュメントを参照してください。
パーティション定義とそのパーティションに格納されているデータを削除
するには、 ALTER TABLE ...
DROP PARTITIONコマンドを使用します。構文は次のとおりです。
ALTER TABLE ... DROP PARTITIONのコマンドは、パーティションとそのパーティションに保存されているすべてのデータが削除されます。 ALTER TABLE ... DROP PARTITIONコマンドは、 LISTまたはRANGEパーティション表のパーティションを削除できます。このコマンドはHASHパーティションテーブルでは機能しません。パーティションを削除すると、そのパーティションのサブパーティションも削除されます。
DROP PARTITION句
を使用するには、パーティショニング・ルートの所有者であるか、テーブルを所有するグループのメンバーであるか、データベースのスーパーユーザー権限または管理者権限が必要です。
照会 ALL _ _
TAB パーティションビューはパーティション名が表示されます。
照会 ALL _ _
TAB パーティションビューは、パーティションが正常に削除されたことを示しています。
サブパーティション定義とそのサブパーティションに格納されているデータを削除
するには、 ALTER TABLE ...
DROP SUBPARTITIONコマンドを
使用し ます 。構文は次のとおりです。
ALTER TABLE table _ name DROP SUBPARTITION サブパーティション _ name;
ALTER TABLE ... DROP SUBPARTITIONのコマンドは、サブパーティション、およびそのサブパーティションに格納されたデータを削除します。 DROP SUBPARTITION句を使用するには、パーティショニング・ルートの所有者であるか、テーブルを所有するグループのメンバーであるか、スーパーユーザー権限または管理者権限が必要です。
10.3.11.1 例 - サブパーティションの 削除
PARTITION second_half_2012 VALUES LESS THAN('01-JAN-2013 ')
);
照会 ALL _ _
TAB SUBPARTITIONSビューは、サブパーティション名が表示されます。
sales表から
americasサブパーティション
を削除するには 、次のコマンドを実行します。
照会 ALL _ _
TAB SUBPARTITIONSビューは、サブパーティションが正常に削除されていることを示しています。
TRUNCATE TABLEコマンドを
使用して 、テーブル定義を保持したままテーブルの内容を削除します。表を切り捨てると、その表のパーティションまたはサブパーティションも切り捨てられます。構文は次のとおりです。
TRUNCATE TABLEコマンドは、テーブル全体を削除し、そのテーブルに存在するデータ。表を削除すると、その表のパーティションまたはサブパーティションも削除されます。
TRUNCATE TABLEコマンド
を使用するには、パーティション・ルートの所有者、表を所有するグループのメンバー、スキーマ所有者、またはデータベース・スーパーユーザーである必要があります。
sales表を
照会すると、パーティションにデータが移入されたことが示されます。
さて、 salesテーブルを
照会すると、データは削除されていますが、構造は損なわれていないことがわかります:
詳細については TRUNCATE TABLE コマンドにてPostgreSQLのドキュメントを参照してください。
ALTER TABLE ...
TRUNCATE PARTITIONコマンドを
使用して 、指定されたパーティションからデータを削除し、パーティション構造はそのまま残します。構文は次のとおりです。
ALTER TABLE table_name TRUNCATE PARTITION partition_name
[{DROP | REUSE} STORAGE]
ALTER TABLE ...
TRUNCATE PARTITIONコマンドを
使用して 、指定されたパーティションからデータを削除し、パーティション構造はそのまま残します。パーティションを切り捨てると、そのパーティションのサブパーティションも切り捨てられます。
ALTER TABLEを ...
TRUNCATE PARTITION の は発射するテーブルのために存在する可能性があります
ON DELETEトリガ
を発生しませんが、それが引き金
TRUNCATE 火災ます。パーティションに対して
ON TRUNCATEトリガーが定義されている場合は、すべての
BEFORE TRUNCATEトリガーが切断される前に起動され、最後の切り捨て後にすべての
AFTER TRUNCATEトリガーが起動されます。
ALTER TABLE ...
TRUNCATE PARTITIONを呼び出すには、表に対して
TRUNCATE特権
が必要です。
DROP STORAGEと
REUSE STORAGEは互換性のためにのみ含まれています。句は解析され無視されます。
sales表を
照会すると、パーティションにデータが移入されたことが示されます。
次に、 salesテーブルを
照会すると、
americasパーティションの内容が削除されたことが示されます。
ALTER TABLE ...
TRUNCATE SUBPARTITIONコマンドを
使用して 、指定されたサブパーティションからすべてのデータを削除し、サブパーティション構造をそのまま残します。構文は次のとおりです。
ALTER TABLE table_name
TRUNCATE SUBPARTITION subpartition_name
[{DROP | REUSE} STORAGE]
ALTER TABLE ... TRUNCATE SUBPARTITION の コマンドは、完全なサブパーティションの構造を残して、指定されたサブパーティションからすべてのデータを削除します。
ALTER TABLEを ...
TRUNCATE SUBPARTITIONを発射するテーブルのために存在する可能性があります
ON DELETEトリガ
を発生しませんが、それが引き金
TRUNCATE 火災ます。サブパーティションに対して
ON TRUNCATEトリガーが定義されている場合は、すべての
BEFORE TRUNCATEトリガーがトリガーされる前にトリガーされ、すべての
AFTER TRUNCATEトリガーは最後のトランケーションが発生した後にトリガーされます。
ALTER TABLE ...
TRUNCATE SUBPARTITIONを呼び出すには、表
に対するTRUNCATE権限
が必要です。
DROP ストレージ と REUSE STORAGE句は、互換性のためだけに含まれています。句は解析され無視されます。
PARTITION "2012" VALUES LESS THAN('01 -JAN-2013' )
sales表を
照会すると、行がサブパーティションに分散されていることが示されます。
2012_americasパーティションの
内容を削除するには 、次のコマンドを呼び出します。
次に、 salesテーブルを
照会すると、
americas_2012パーティションの内容が削除されたことが示されます。
DEFAULTまたはMAXVALUEパーティションまたはサブパーティションには、テーブルに定義された他のパーティショニングのルールを満たしていない任意の行をキャプチャします。
DEFAULTパーティションはLISTパーティション(またはサブパーティション)表内の他のパーティションに適合していない任意の行をキャプチャします。 DEFAULTルールを含まない場合、パーティション制約内の値の1つに一致しない行はエラーになります。各LISTパーティションまたはサブパーティションには、独自のDEFAULTルールが設定されている場合があります。
どこ PARTITION_NAMEは、他のパーティションに指定したルールに一致しないすべての行を格納するパーティションまたはサブパーティションの名前を指定します。
DEFAULTパーティション
をテストするには、パーティション制約で指定されている国のいずれかと一致しない
国の列に値を含む行を追加します。
sales表の
内容を 照会すると、以前に拒否された行が
sales_others区画に保管されていることが確認されます。
• |
ALTER TABLE ... ADD PARTITIONコマンドを 使用して、テーブル内の既存の行と追加するパーティションの値との間に競合する値がない限り、 DEFAULTルールを持つテーブルにパーティションを追加できます。代わりに、 ALTER TABLE ... SPLIT PARTITIONコマンドを使用して、既存のパーティションを分割することもできます。例は、この箇条書きリストの後に示されています。 |
• |
ALTER TABLE ... ADD SUBPARTITIONコマンドを 使用して、表の既存の行と追加するサブパーティションの値との間に競合する値がない限り、 DEFAULT規則を持つ表にサブパーティションを追加 できます 。あるいは、 ALTER TABLE ... SPLIT SUBPARTITIONコマンドを使用して、既存のサブパーティションを分割することができ ます 。 |
このセクションの冒頭に示さ
れている CREATE TABLE salesコマンドで
作成されたテーブルを使用して 、次の例では、
ALTER TABLE ... ADD PARTITIONコマンドを使用して、テーブル内の既存の行と追加するパーティションの値:
edb=# INSERT INTO sales (dept_no, country) VALUES (1,'FRANCE'),(2,'INDIA'),(3,'US'),(4,'SOUTH AFRICA'),(5,'NEPAL');
Row (4、 'SOFTH AFRICA')は、
ALTER TABLE ... ADD PARTITIONステートメントの
VALUESリストと競合し、エラーが発生します。
次の例では、 DEFAULTパーティションを分割し、2つの新しいパーティション間でパーティションの内容を再配布します。このセクションの冒頭に示す
CREATE TABLE salesコマンドを使用してテーブルを作成しました。
INSERT INTO sales VALUES
(10、 '4519b'、 'FRANCE'、'17-Jan-2012 '、' 45000 ')、
(10、'9519b '、' ITALY '、'07-Jan-2012'、 '15000')、
(20、 '3788a'、 'INDIA'、'01-Mar-2012 '、' 75000 ')、
(20、 '3788a'、 'PAKISTAN'、'04-Jun-2012 '、' 37500 ')、
(30、'9519b '、' US '、'12-Apr-2012'、 '145000')、
(30、 '7588b'、 'CANADA'、'14 -Dec-2012 '、' 50000 ')、
(40、 '4519b'、 '南アフリカ'、'08-apr-2012 '、' 120000 ')、
(40、 '4519b'、 'KENYA'、'08-Apr-2012 '、' 120000 ')、
(50、 '3788a'、 'CHINA'、'12-May-2012 '、' 4950 ');
次のコマンドは、 DEFAULT その他のパーティションを
africaなどの2つのパーティションに分割し
ます 。
パーティションには アフリカのパーティションと
DEFAULT その他のパーティション
が含まれています:
MAXVALUEパーティション (またはサブパーティション)は、レンジ・パーティション(またはサブパーティション)の表に、他のパーティションに適合していない任意の行をキャプチャします。 MAXVALUEルールを含まない場合、パーティション化ルールで指定された最大限度を超える行はエラーになります。各パーティションまたはサブパーティションには、それぞれ独自のMAXVALUEパーティションがあります。
どこ PARTITION_NAMEは、他のパーティションに指定したルールに一致しないすべての行を格納するパーティションの名前を指定します。
次の CREATE TABLEコマンドは同じテーブルを作成しますが、パーティションは
MAXVALUEです。エラーをスローするのではなく、サーバーは以前のパーティション制約と一致しない行を
他のパーティションに格納します。
MAXVALUEパーティション
をテストするには、パーティション化ルールにリストされている最後の日付値を超える
日付列に値を含む行を追加します。サーバーは、
他のパーティションに行を格納します。
sales表の
内容を 照会すると、以前に拒否された行が
sales_others区画に保管されていることが確認されます。
• |
あなたは使用することはできません MAXVALUEルールを表にパーティションを追加するために PARTITION文を 追加 ... ALTER TABLE をしていますが、既存のパーティションを分割するには 、ALTER TABLE ... SPLIT PARTITION 文を使用することができます。 |
• |
ALTER TABLE ... ADD SUBPARTITION文を 使用して、 MAXVALUEルールを持つ表にサブパーティションを追加することはできませんが、既存のサブパーティションを ALTER TABLE ... SPLIT SUBPARTITION文で分割 できます 。 |
sale_month列の
値が 8で、
sales_year列の値が
2012である
行は
すべてq3_2012パーティションに格納されるため、Advanced Serverはそのパーティションのみを検索します。
ここで、 view_nameは、表パーティション・ビューの名前を指定します。
• |
Oracleデータベースと互換性 のある CALL 文。 |
どこ バージョンは libclntsh のバージョン番号です 。 そう ライブラリ。例えば:
Linux(またはWindowsの場合は
PATH )
の LD_LIBRARY_PATH環境変数をOracleクライアントのインストールディレクトリの
libディレクトリに設定します。
Windowsの場合のみ、 oracle_home構成パラメータの
値を postgresql.confファイルに設定できます。
oracle_home構成パラメーターで指定された値は、Windows
PATH環境変数よりも優先されます。
Advanced Serverを起動するたびに、Linux
の LD_LIBRARY_PATH環境変数(
PATH環境変数またはWindowsの
oracle_home構成パラメータ)を正しく設定する必要があります。
Windowsの場合のみ: postgresqlに oracle _
home構成パラメータを設定します。
confファイルを編集し、次の行を追加してファイルを編集します。
設定後 のOracle _
ホーム設定
パラメータを、変更を有効にするには、サーバーを再起動する必要があります。 Windowsサービスコンソールからサーバーを再起動します。
dblink_ora_connect() 関数は、ユーザが指定した接続情報を使用してOracleデータベースへの接続を確立します。 この関数には2つの形式があります。最初の形式の署名は次のとおりです。
dblink_ora_connect( conn_name 、 server_name 、 service_name 、 user_name 、 password 、 port 、 asDBA )
Oracleサーバーで
SYSDBA権限を要求する場合は、
asDBAは
Trueです。
このパラメータはオプションです。省略された場合、デフォルト値は FALSE です。 dblink_ora_connect() の最初の形式 は、 TEXT 値を 返し ます。
Oracleサーバーで
SYSDBA権限を要求する場合は、
asDBAは
Trueです。
このパラメータはオプションです。省略された場合、デフォルト値は FALSE です。 dblink_ora_connect() 関数 の2つ目の形式では 、サーバーへの接続を確立するときに、あらかじめ定義された外部サーバーの接続プロパティを使用できます。
dblink_ora_connect() 関数 の2番目の形式を呼び出す前に 、 CREATE SERVER コマンドを使用して、システム・テーブルへのリンクの接続プロパティを格納します。 dblink _ ora _ connect() 関数 を呼び出すとき は、 CREATEで 指定されたサーバー名を使用します SERVER コマンドを使用して、リンク名を指定します。
dblink_ora_connect() の2番目の形式 は、 TEXT 値を 返し ます。
dblink_ora_status() 関数は、データベース接続のステータスを返します。 署名は次のとおりです。
dblink_ora_disconnect() 関数は、データベース接続を閉じます。 署名は次のとおりです。
dblink_ora_record() 関数は、データベースから情報を検索します。 署名は次のとおりです。
query_text Oracleサーバー上で呼び出されるSQL
SELECT文のテキストを指定します。
dblink_ora_call() 関数は、Oracle データベース上の 非 SELECT 文を 実行 し、結果セットを返します。 署名は次のとおりです。
コマンド Oracleサーバー上で呼び出されるSQL文のテキストを指定します。
dblink_ora_exec() プロシージャは、リモート・データベースでのDMLまたはDDL文を実行します。 署名は次のとおりです。
コマンド Oracleサーバー上で呼び出される
INSERT 、
UPDATE 、または
DELETE SQLステートメントのテキストを指定します。
dblink_ora_copy( conn_name 、 command 、 schema_name 、 table_name 、 truncate 、 count )
コマンド Oracleサーバー上で呼び出されるSQL
SELECT文のテキストを指定します。
truncate は、 コピーする前に サーバが テーブル を TRUNCATE する かどうかを指定します 。 TRUE を 指定する と、サーバーが 表 を TRUNCATE する 必要が あります。 切り捨て はオプションです。省略された場合、値は FALSEになります 。
countは、
nレコードごとにステータス情報を報告するようにサーバーに指示します(
nは指定された番号です)。
この機能の実行中、アドバンストサーバは カウントの繰り返しごと に重大度 INFOの 通知を 発行 します。たとえば、FeedbackCountが 10の 場合 、 dblink_ora_copy() は 10 レコード ごとに通知を 発行し ます。 カウント はオプションです。省略された場合、値は 0 です。
この例では 、ユーザー名が hr 、パスワードが pwdの ポート 1521 ( localhost上 )で 実行さ れている xe という名前のサービスに接続し ます 。 他のdblink_ora関数を呼び出すときは 、接続名 acctgを
使用してこの接続を
参照できます。
次のコマンドは、使用して Advanced Serverの名前付き as_acctg のインスタンス上の public スキーマ にあるテーブルに ora_acctg という名前(Oracleサーバー上の)テーブルから EMPID と DEPTNO 列を コピーする edb_conn という名前の接続を介して dblink_ora_copy() 関数を 。 TRUNCATE オプション が適用され、そして 3 のフィードバックカウントが 指定されています。
次の SELECT 文は、 dblink_ora_record() 関数と acctg 接続を使用してOracleサーバーから情報を取得します。
PostgreSQLの8.3、8.4、9.0、9.1、9.2、9.3、9.4、9.5、9.6、10、及び11は、PostgreSQL文書に共通するこのガイドの部分のためのベースラインを提供し、ここに認められています。
この EnterpriseDBソフトウェアおよびドキュメンテーションの
一部は 、以下の著作物を使用することができ、その使用はここで認められます。
PostgreSQLはPostgreSQLグローバル開発グループ
の著作権©1996-2018に基づき、以下のカリフォルニア大学ライセンスの条件に基づいて配布されています。
ザ カリフォルニア州立大学は、商品性および特定目的への適合性の黙示的な保証を含む(ただしこれらに限定されない)いかなる保証も特に断ります。本契約に基づいて提供される本ソフトウェアは、現状のままであり、カリフォルニア州立大学は、保守、サポート、更新、拡張または改変を提供する義務を負いません。