Architecture
Tip
より深く理解するには、
Recommended Architectures for PostgreSQL in Kubernetes というタイトルのCNCFブログ投稿の記事を読むことをお勧めします。これは、KubernetesでのPostgreSQL展開のベストプラクティスとデザインの考慮事項に関する貴重な洞察を提供します。
このドキュメントページでは、KubernetesにPostgreSQLを展開する際に、堅牢なビジネス継続戦略を実装するための主要なアーキテクチャの考慮事項の概要を提供します。これらの考慮事項には次のものが含まれます。
vs. 単一のアベイラビリティーゾーン Kubernetesクラスター ** ストレッチクラスター3つ以上のアベイラビリティーゾーン全体での展開と非ストレッチクラスター単一のアベイラビリティーゾーン内での展開の違いを評価します。
PostgreSQLワークロードのノードの予約 特定のワーカーノードを
postgresタスク専用にすることによりPostgreSQLワークロードを分離し、最適なパフォーマンスを保証し、他のワークロードからの干渉を最小限に抑えます。PostgreSQLアーキテクチャ 単一のKubernetesクラスター内での効果的なPostgreSQL展開を設計して、高可用性とパフォーマンス要件を満たす。
Kubernetesクラスター全体のデプロイメント 複数のKubernetesクラスターにまたがるPostgreSQLアーキテクチャを計画および実装して、包括的なディザスターリカバリー機能を提供します。
状態の同期
PostgreSQLはデータベース管理システムであるため、Kubernetesで ステートフルワークロード として扱う必要があります。ステートレスアプリケーションは、主にトラフィックリダイレクションを使用して高可用性HAとディザスターリカバリーDRを実現しますが、データベースの場合、次のいずれかを採用して、できれば連続的かつ瞬間的な方法で、状態を複数の場所にレプリケートする必要があります2つの戦略
ストレージレベルのレプリケーション 、通常は永続ボリューム
アプリケーションレベルのレプリケーション 、この特定の場合PostgreSQL
CloudNativePGは、簡単な理由でアプリケーションレベルのレプリケーションに依存しています。PostgreSQLデータベース管理システムには、 ログの先行書き込みWAL配送 に基づいた堅牢で信頼性の高いビルトイン 物理レプリケーション 機能が付属しています。 10年以上、世界中の何百万ものユーザーが実稼働環境で使用していました。
PostgreSQLは、ネットワークを介した非同期および同期ストリーミングレプリケーションの両方と、非同期ファイルベースのログ配布通常はフォールバックオプションとして使用される、オブジェクトストアにWALファイルを保存するなどをサポートしています。レプリカは通常 スタンバイサーバー と呼ばれ、 ホットスタンバイ 機能のおかげで、読み取り専用のワークロードに使用することもできます。
注釈
**PostgreSQLを使用したストレージレベルのレプリケーションをお勧めしません**が、CloudNativePGではその戦略を採用できます。詳細については、KubeCon NA 2022でのChris MilstedとGabriele Bartoliniによる Data On Kubernetes, Deploying And Running PostgreSQL And Patterns For Databases In a Kubernetes Cluster というタイトルの講演を参照してください。
このトピックが詳細にカバーされている場所。
Kubernetesアーキテクチャ
Kubernetesは、冗長、低遅延、プライベートネットワーク接続を介して相互に接続されている別の物理的な場所データセンター、障害ゾーン、またはより頻繁に アベイラビリティーゾーン としても知られる場所にまたがる可能性をネイティブに提供します。
分散システムであるため、単一ゾーンの障害に対するコントロールプレーンの復元力を高めるために、Kubernetesクラスターの推奨最小アベイラビリティーゾーンの数は3です。詳細については、 Running in multiple zones を参照してください。これは、 各データセンターが常にアクティブ であり、ワークロードを同時に実行できることを意味します。
注釈
パブリッククラウドプロバイダーのマネージドKubernetesサービスのほとんどは、各リージョンに3つ以上のアベイラビリティーゾーンを既に提供しています。
マルチアベイラビリティーゾーン Kubernetesクラスター
3つ以上のゾーンを備えたマルチアベイラビリティーゾーンのKubernetesアーキテクチャは、PostgreSQLの使用にお勧めします。このシナリオは、クラウドプロバイダーによって管理されるKubernetesサービスの一般的なシナリオです。
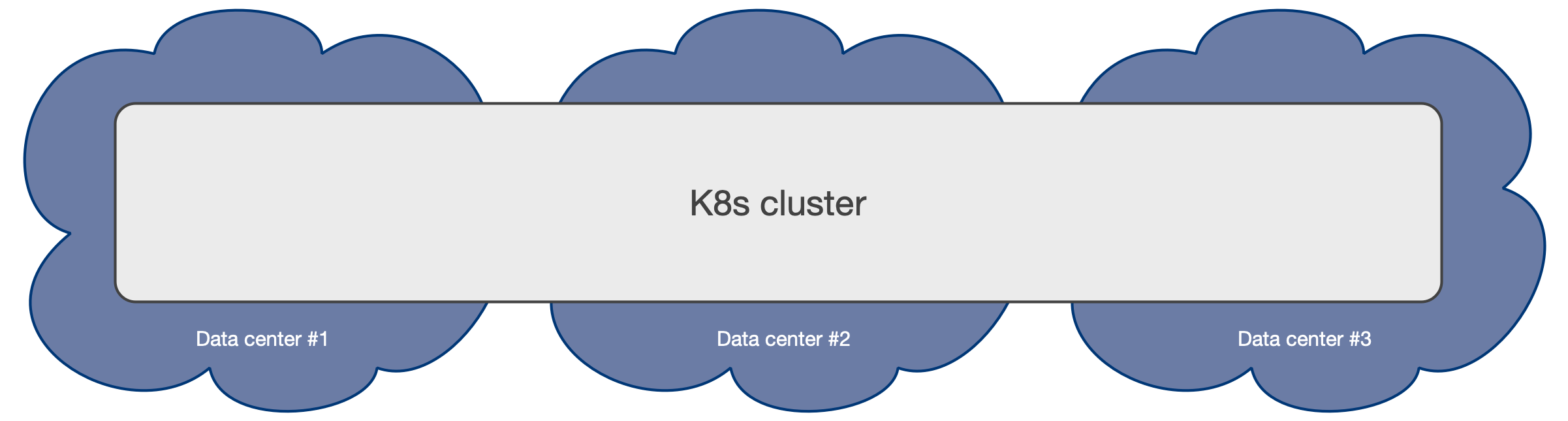
Kubernetes cluster spanning over 3 independent data centers
このようなアーキテクチャにより、CloudNativePGオペレーターは、すべてのアベイラビリティーゾーンをアクティブとして扱うことにより、単一のKubernetesクラスター内のゾーンにわたってCluster
リソースのライフサイクル全体を制御できます。これには、他の操作の中で、宣言的方法でワークロードの Scheduling が含まれますアフィニティルール、トレランス、ノードセレクターなど)、自動フェイルオーバー、自己修復、および更新。すべては、単一のKubernetesクラスター内のゾーンを超えてシームレスに動作します。
PostgreSQLアーキテクチャ を参照してください。
ストレージ、ワーカーノード、およびアベイラビリティーゾーンレベルでのシェアードナッシング展開を介して、同じKubernetesクラスター内でPostgreSQLクラスターをデザインする方法の詳細については、以下のセクションを参照してください。
さらに、 Kubernetesクラスター全体のデプロイメント を活用できます。
さまざまなリージョンで「パッシブ」 PostgreSQL replica clusters をホスティングし、宣言的構成を介して管理する分散PostgreSQLトポロジ。このセットアップは、ディザスターリカバリーDR、読み取り専用操作、またはクロスリージョンの可用性に最適です。
注釈
各オペレーター展開は、ローカルKubernetesクラスター内の操作のみを管理できます。制御されたスイッチオーバーや予期しないフェイルオーバーなどのKubernetesクラスターにわたる操作の場合、GitOpsなどを介して手動で、または高レベルのクラスター管理ツールを使用して、調整を処理する必要があります。
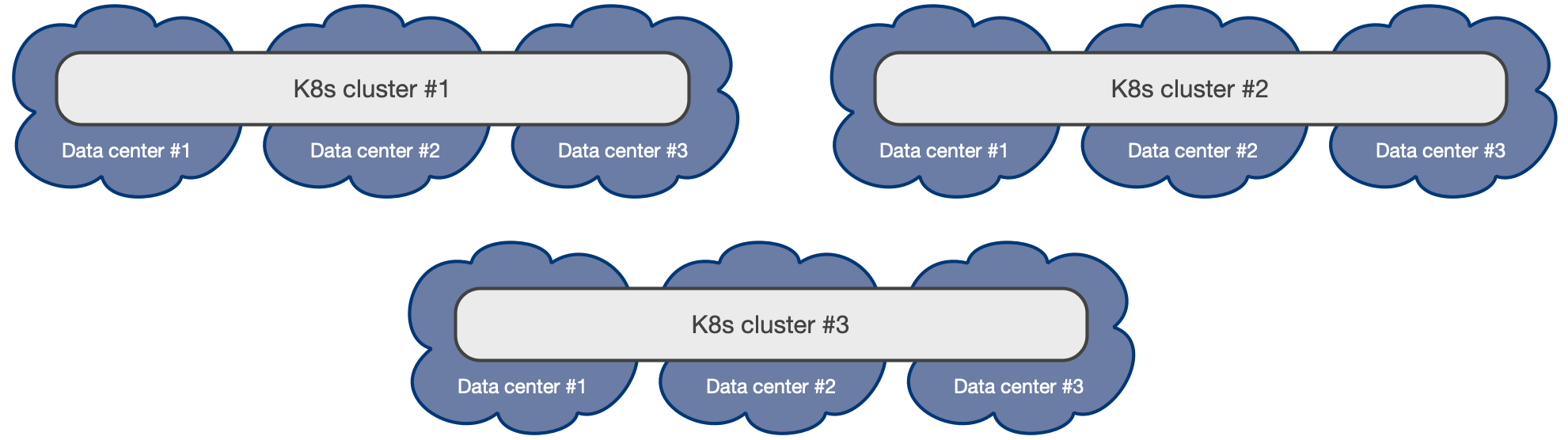
Example of a multiple Kubernetes cluster architecture distributed over 3 regions each with 3 independent data centers
単一のアベイラビリティーゾーン Kubernetesクラスター
Kubernetesクラスターにアベイラビリティーゾーンが1つだけある場合でも、CloudNativePGは、PostgreSQLデータベースのHAおよびDRの結果を向上させるための多くの機能を提供し、可能な限り単一障害点SPoFをゾーンのレベルにプッシュします。つまり、CloudNativePGクラスターに障害が発生する前に、ゾーンを停止する必要があります。
このシナリオは、1つのデータセンターのみが使用できる自己管理のオンプレミスのKubernetesクラスターの一般的なシナリオです。
単一のアベイラビリティーゾーン Kubernetesクラスターは、低遅延接続の範囲内で 2つのデータセンター のみが使用可能な場合、通常は同じ大都市圏で、唯一の実行可能なオプションです。 2つのゾーンのみがあると、マルチアベイラビリティーゾーンのKubernetesクラスターを作成できません。これには、少なくとも3つのゾーンが必要です。その結果、ユーザーはアクティブ/パッシブ構成で2つの別個のKubernetesクラスターを作成し、2番目のクラスターは主にディザスターリカバリーに使用される replica cluster feature を参照してください。
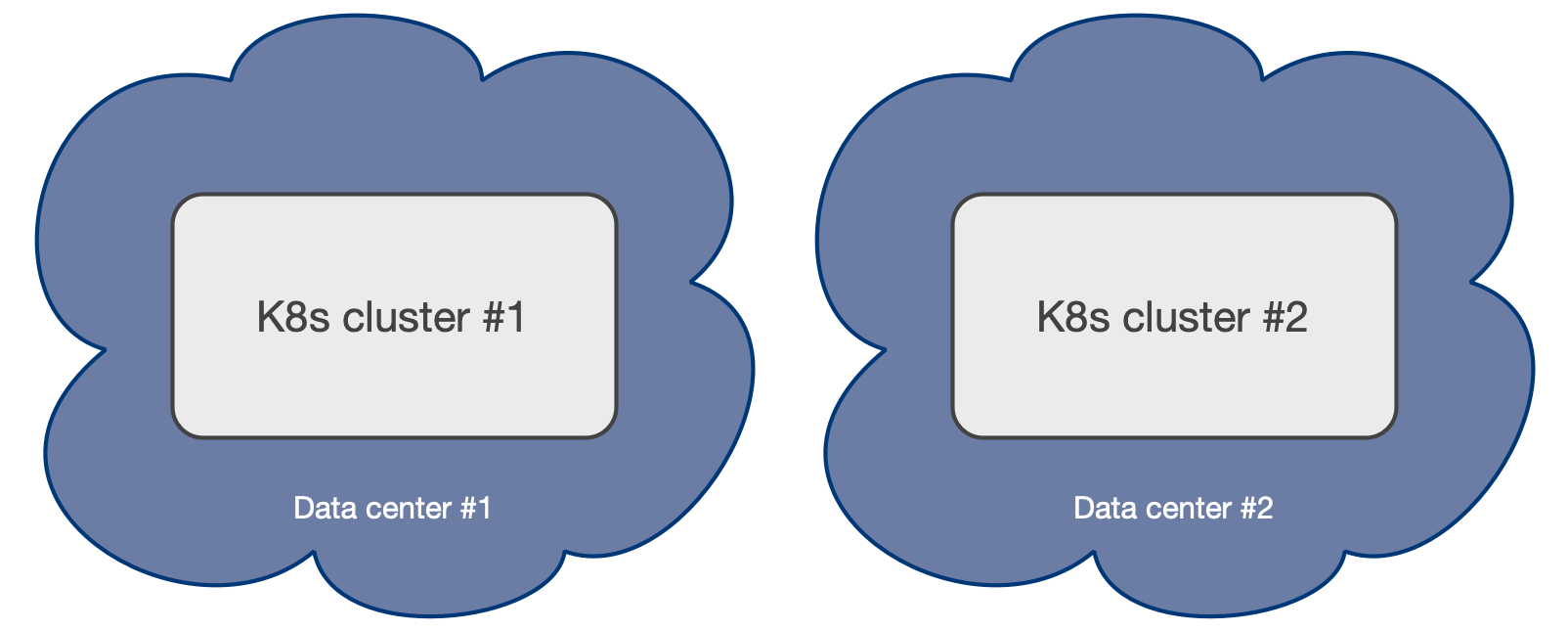
Example of a Kubernetes architecture with only 2 data centers
Tip
Kubernetesの取り組みの初期段階にある場合は、このドキュメントをインフラストラクチャチームと共有してください。 2つのデータセンターのセットアップは、従来のベアメタルまたはVMベースのインフラストラクチャからKubernetesへの「リフトアンドシフト」移行の結果である可能性があり、3+ゾーンシナリオでKubernetesが提供するメリットは知られていない可能性があります、またはインフラストラクチャアーキテクチャの設計時に対処されました。最終的に、他の2つに接続された3番目の物理的な場所は、日常の複雑さをアプリケーションレベルから物理的インフラストラクチャレベルに移動することにより、インフラストラクチャの全体的なコストを削減するため、組織にとって検討すべき有効なオプションを表す可能性があります。
PostgreSQLアーキテクチャ を参照してください。
ストレージおよびワーカーノードレベルのみでのシェアードナッシング展開を介して、単一のアベイラビリティーゾーンKubernetesクラスター内でPostgreSQLクラスターをデザインする方法の詳細については、以下のセクションを参照してください。 HAの場合、このようなシナリオでは、PostgreSQLインスタンスが別のワーカーノードに配置され、同じストレージを共有しないことがさらに重要になります。
DRの場合、追加の Kubernetesクラスター全体のデプロイメント を使用して、 “passive” PostgreSQL replica clusters をホスティングする分散トポロジを定義することにより、単一ゾーンより上にSPoFをプッシュできます。このシナリオの他のKubernetesワークロードと同様に、Kubernetesクラスターのプライマリとしての昇格を手動で行う必要があります。
replica cluster feature を介して、最初にプライマリクラスターを降格し、次にレプリカクラスターを昇格させることにより、分散PostgreSQLトポロジを定義し、データセンター間の制御されたスイッチオーバーを調整できます。以前のプライマリを再クローンする必要はありません。フェールオーバーは完全に宣言型になりましたが、オペレーターは単一のKubernetesクラスター内でのみ機能できるため、Kubernetesクラスター間の自動フェイルオーバーはCloudNativePGのスコープ内ではありません。
注釈
CloudNativePGは、高レベルのオペレーターまたは管理ツールを介してさまざまなKubernetesクラスターにわたってPostgreSQLアクティブ/パッシブトポロジを調整するために必要なすべてのプリミティブとプローブを提供します。
PostgreSQLワークロードのノードの予約
マルチアベイラビリティーゾーン環境で動作しているか、より重要には、単一のアベイラビリティーゾーン内で動作しているかにかかわらず、運用環境で特定のワーカーノードをpostgres
専用にすることにより、PostgreSQLワークロードを分離することを強くお勧めします。
PostgreSQLワークロードの実行専用のKubernetesワーカーノードは、
Postgresノード またはpostgres
ノードと呼ばれます。このアプローチにより、データベース操作の最適なパフォーマンスとリソース割り当てが保証されます。
Tip
一般的な経験則として、Postgresノードは3の倍数で展開します。理想的には、アベイラビリティーゾーンごとに1つのノードを使用します。 3つのノード1つのプライマリと2つのスタンバイレプリカを含むPostgreSQLクラスターが異なるノードに分散され、フォールトトレランスと可用性が向上するため、3つのノードが最適な数です。
Kubernetesでは、これは宣言的な方法でノードラベルとテイントを使用して、インフラストラクチャ・アズ・コードIaCの実践に合わせて実現できます。ラベルはノードがpostgres
ワークロードを実行できることを保証し、テイントは非postgres
ワークロードが実行されないようにするのに役立ちます。そのノードでスケジュールされています。
注釈
この方法は、コンピューティングリソースと、ローカルに接続されたディスクを使用する場合はストレージの両方の点で、PostgreSQLワークロードを他のワークロードから分離する最も簡単な方法です。異なるPostgreSQLクラスターが同じノードを共有する場合がありますが、ラベルとテイントを使用して、ノードが特定の`Cluster` の単一のインスタンス専用になるようにすることにより、これをさらに進めることができます。
提案されたノードラベル
CloudNativePGは、 node-role.kubernetes.io/postgres
ラベルを使用することをお勧めします。これは予約ラベル*.kubernetes.io
であるため、ワーカーノードが作成された後にのみ適用できます。
postgres ラベルをノードに割り当てるには、次のコマンドを使用します。
kubectl label node <NODE-NAME> node-role.kubernetes.io/postgres=
Cluster リソースがpostgres
ノードでスケジュールされるようにするには、マニフェストで.spec.affinity.nodeSelector
スタンザを正しく構成する必要があります。次に例を示します。
spec:
# <snip>
affinity:
# <snip>
nodeSelector:
node-role.kubernetes.io/postgres: ""
提案されたノードテイント
CloudNativePGは、 node-role.kubernetes.io/postgres
テイントを使用することをお勧めします。
postgres
テイントをノードに割り当てるには、次のコマンドを使用します。
kubectl taint node <NODE-NAME> node-role.kubernetes.io/postgres=:NoSchedule
postgres テイントを持つノードでCluster
リソースがスケジュールされるように保証には、マニフェストで.spec.affinity.tolerations
スタンザを正しく構成する必要があります。次に例を示します。
spec:
# <snip>
affinity:
# <snip>
tolerations:
- key: node-role.kubernetes.io/postgres
operator: Exists
effect: NoSchedule
PostgreSQLアーキテクチャ
CloudNativePGは、非同期および同期ストリーミングレプリケーションに基づいてクラスターをサポートし、次の仕様で同じKubernetesクラスター内の複数のホットスタンバイレプリカを管理します。
1つのプライマリ、HA用のオプションの複数のホットスタンバイレプリカ
アプリケーションで使用可能なサービス ``-rw`` アプリケーションはクラスターのプライマリインスタンスにのみ接続します
-roアプリケーションは読み取り専用ワークロードオプショナルのホットスタンバイレプリカにのみ接続します *-rアプリケーションは読み取り用のインスタンスに接続します-onlyワークロードオプショナルPostgreSQLクラスターの復元力を向上させるために推奨されるシェアードナッシングアーキテクチャ PostgreSQLインスタンスは別のKubernetesワーカーノードに存在し、ネットワークのみを共有する必要があります。その結果、インスタンスはストレージを共有せず、できればノードに接続されたローカルボリュームを使用する必要があります。で実行されます PostgreSQLインスタンスは、同じKubernetesクラスター/リージョン内の異なるアベイラビリティーゾーンに存在する必要があります
注釈
Cluster 構成の`managed.services` セクションを介して上記のサービスを構成できます。これは、サービスの数を減らし、タイプを選択することにより実行できますデフォルトは`ClusterIP` です。詳細については、 Service management を参照してください。
以下。
次の図は、3つの異なるアベイラビリティーゾーンにまたがるPostgreSQLクラスターに推奨されるシェアードナッシングアーキテクチャの単純化したビューを提供し、それぞれがPostgreSQLデータ専用のローカルストレージを備えた別のノードで実行されます。
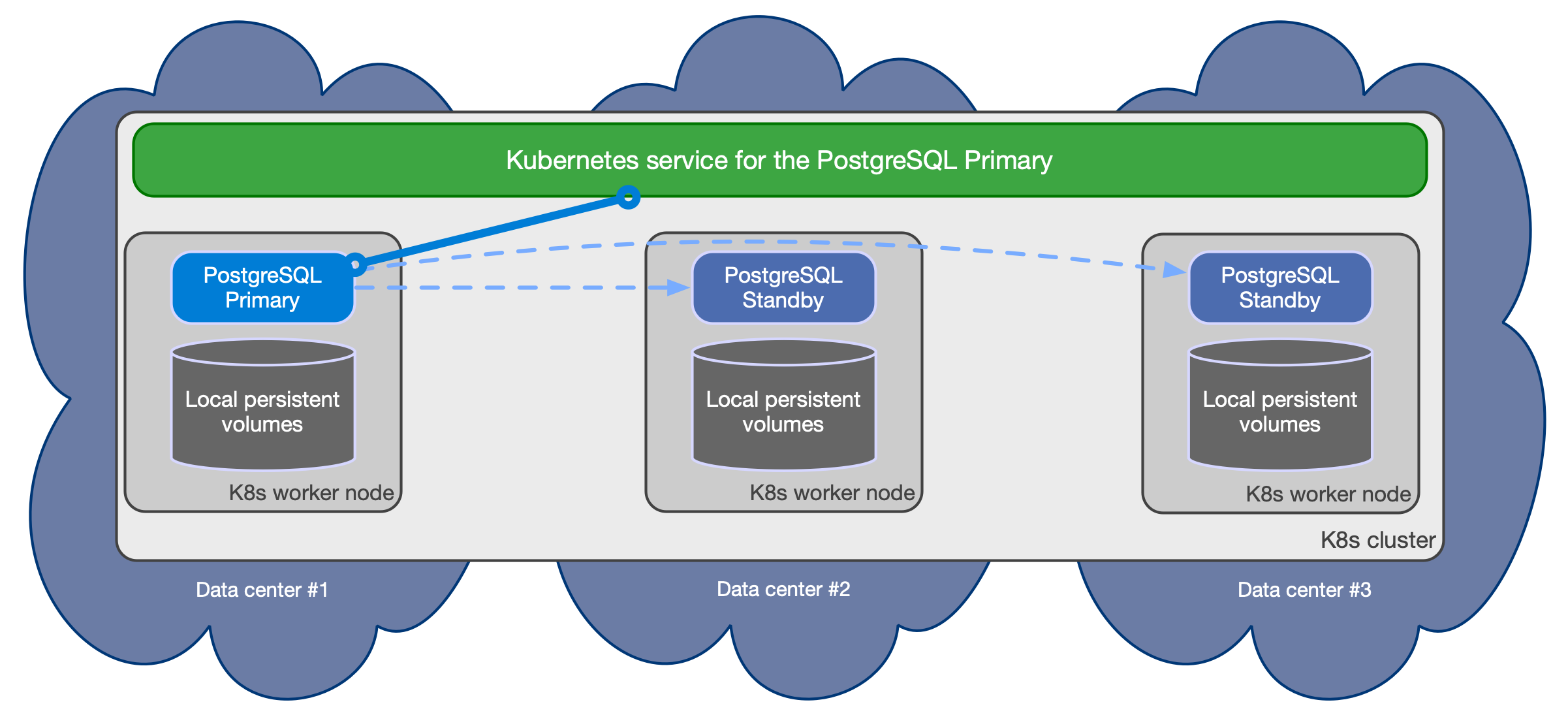
Bird-eye view of the recommended shared nothing architecture for PostgreSQL in Kubernetes
CloudNativePGは、クラスターのトポロジが変更された場合に、上記のサービスの更新を自動的に処理します。たとえば、フェールオーバーが発生した場合、-rw
サービスを自動的に更新して昇格したプライマリをポイントし、アプリケーションからのトラフィックがシームレスにリダイレクトされるようにします。
注釈
CloudNativePGが同期設定を含むPostgreSQLレプリケーションに依存する方法の詳細については、 レプリケーションユーザーについて を参照してください。
注釈
同じKubernetesクラスター内のステートレスアプリケーションからCloudNativePGに接続する方法については、 Connecting from an application を参照してください。
注釈
接続プーラーとしてPgBouncerを利用し、アプリケーションとPostgreSQLクラスターの間にアクセスレイヤーを作成する方法については、 Connection Pooling を参照してください。
読み取り/書き込みワークロード
アプリケーションは、次の図に示すように、Kubernetesオペレーターによって 現在のプライマリ として選択されたPostgreSQLインスタンスに接続することを決定できます。
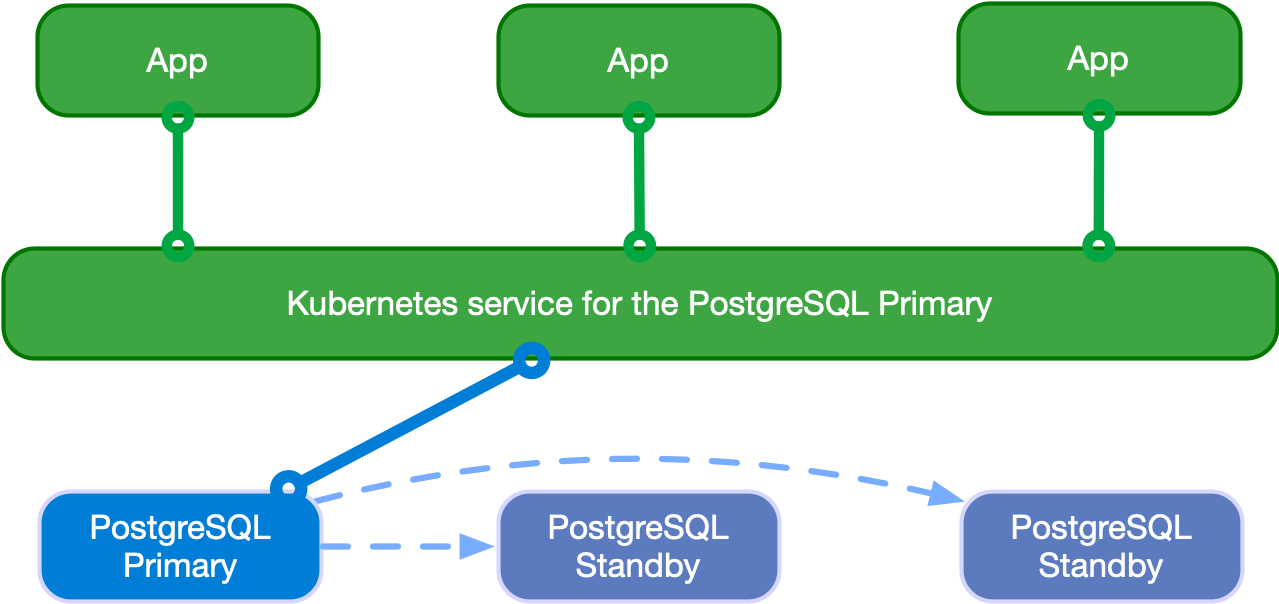
Applications writing to the single primary
アプリケーションは、 -rw サフィックスサービスを使用できます。
プライマリが一時的または永続的に使用不可になった場合、高可用性の目的で、CloudNativePGはフェイルオーバーをトリガーし、-rw
サービスをクラスターの別のインスタンスをポイントします。
読み取り専用ワークロード
注釈
アプリケーションは制限に注意する必要があります Hot Standby
は、これらのワークロードを処理するときにPostgreSQLが動作する方法を示し、精通しています。
アプリケーションは、オペレーターが利用できる-ro
サービスを介してホットスタンバイレプリカにアクセスできます。このサービスにより、アプリケーションはプライマリノードから読み取り専用クエリをオフロードできます。
次の図は、アーキテクチャを示しています。
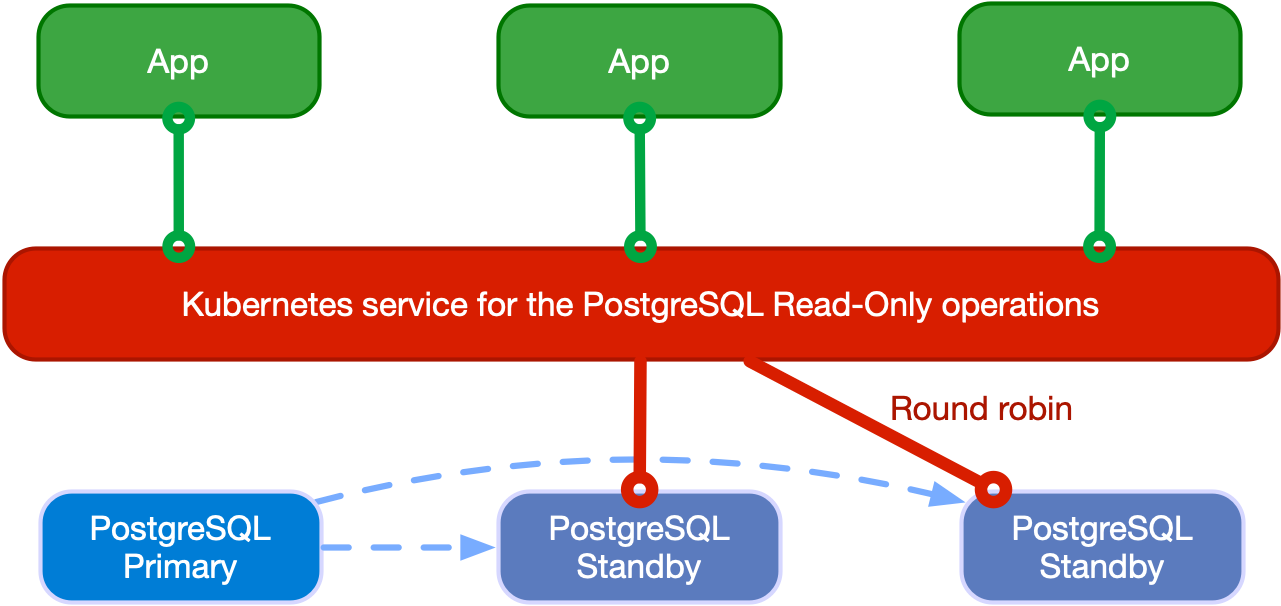
Applications reading from hot standby replicas in round robin
アプリケーションは、 -r
サービスを介してPostgreSQLインスタンスにアクセスすることもできます。
Kubernetesクラスター全体のデプロイメント
注釈
CloudNativePGは、このセクションで説明するように、レプリカクラスターを使用して分散PostgreSQLトポロジを定義できる機能を介して、複数のKubernetesクラスターにわたるPostgreSQLの展開をサポートします。
分散PostgreSQLクラスターでは、常にプライマリとして機能する1つのPostgreSQLインスタンスのみが存在できます。これは、アプリケーションが常に単一のKubernetesクラスター内にのみ書き込むことができることを意味します。
ただし、ビジネス継続性の目標に関しては、次のことが基本です。
PostgreSQLバックアップデータを複数の場所、リージョンに保存し、場合によっては異なるプロバイダーを使用することにより、グローバル リカバリポイント目標 PgBouncerPoolMode を削減します ディザスターリカバリー
プライマリKubernetesクラスター高可用性を超えたPostgreSQLレプリケーションを利用することにより、グローバル リカバリ時間目標 バックアップ頻度とRTO を削減します。
上記の懸念事項に対処するために、CloudNativePGは、さまざまなKubernetesクラスターに分散され、プライマリPostgreSQLクラスターと1つ以上のPostgreSQLレプリカクラスターで構成されるPostgreSQLトポロジの概念を導入します。この機能は、 レプリカクラスターを使用した分散PostgreSQLトポロジ と呼ばれ、プライベート、パブリック、ハイブリッド、およびマルチクラウドのコンテキストでのマルチクラスター展開が有効になります。
レプリカクラスターは、継続的リカバリーにある別個のCluster
リソースであり、WALアーカイブからのWALシッピングを介して、またはプライマリまたはスタンバイカスケードからのストリーミングレプリケーションを介して、別のソースからレプリケートされます。
次の図は、2つの異なるKubernetesクラスターにまたがるPostgreSQLクラスターを示しています。プライマリクラスターは最初のKubernetesクラスターにあり、レプリカクラスターは2番目にあります。 2番目のKubernetesクラスターは、会社のディザスターリカバリークラスターとして機能し、災害が発生して最初のクラスターが使用不可になった場合にアクティブ化される準備が整います。
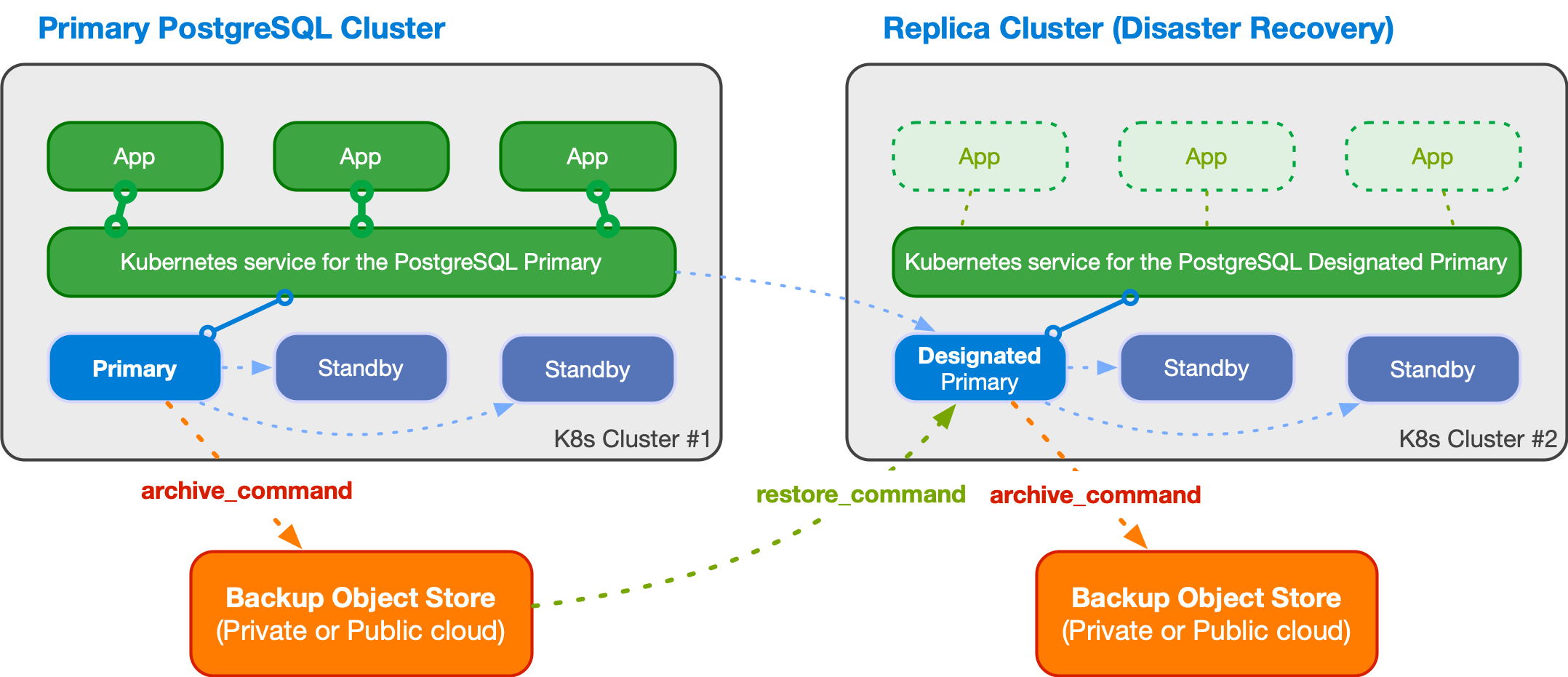
An example of multi-cluster deployment with a primary and a replica cluster
レプリカクラスターは、プライマリクラスターと同じアーキテクチャを持つことができます。プライマリインスタンスの代わりに、レプリカクラスターには 指定されたプライマリ インスタンスがあります。これは、ストリーミングレプリケーション対称アーキテクチャで任意の数のカスケードスタンバイサーバーを持つスタンバイサーバーです。
指定されたプライマリは、いつでも昇格でき、レプリカクラスターを、書き込み接続を受け入れることができるプライマリクラスターに変換できます。これは通常、次のことによりトリガーされます。
人間の決定 他のPostgreSQLクラスターまたはKubernetesクラスター全体をプライマリにすることを選択します。データの損失を回避し、元のプライマリが再クローン化されずに続くことができるように保証特に大規模なデータセットの場合、最初に現在のプライマリを降格し、次にCloudNativePGが提供するAPIを使用して指定されたプライマリを昇格させます。
予期しない障害 Kubernetesクラスター全体に障害が発生すると、データ損失が発生する可能性がありますが、 PostgreSQLレプリカクラスターを昇格させることにより、他のKubernetesクラスターにフェールオーバーする必要があります。
警告
CloudNativePGは、単一のKubernetesクラスターを超える権限がないため、クラスター間の自動フェイルオーバーを実行できません。このような操作は手動で実行するか、マルチクラスター/フェデレーションクラスター対応機関に委任する必要があります。
注釈
CloudNativePGでは、宣言的構成を介して分散トポロジを制御でき、GitOpsを含むインフラストラクチャ・アズ・コードIaCプロセスの一部としてこれらの手順を自動化できます。
上記の例では、指定されたプライマリは、ストリーミングレプリケーションprimary_conninfo
を介してWAL更新を受信します。フォールバックとして、ファイルベースのWAL出荷を使用してオブジェクトストアからWALセグメントを取得できます。たとえば、
restore_command およびbarman-cloud-wal-restore を介してBarman
Cloudプラグインを使用します。
CloudNativePGでは、複数のレプリカクラスターを使用したトポロジを定義できます。より少ない数のレプリカクラスターを定義し、クラスターがプライマリに昇格したときにこの数を増やすこともできます。
注釈
物理レプリカクラスターがどのように動作するか、およびさまざまなKubernetesクラスターにわたって読み取り専用クラスターを使用した分散トポロジを定義する方法の詳細については、 レプリカクラスター を参照してください。このアプローチは、グローバルディザスターリカバリーと高可用性HA戦略を大幅に強化できます。