Benchmarking
CNPG kubectlプラグインは、CloudNativePGを使用してKubernetesでPostgreSQL展開をベンチマークする簡単な方法を提供します。
ベンチマークは、2つの側面に焦点を当てています。
注釈
pgbench および`fio` は、ステージングまたは実稼働前環境で実行する必要があります。運用環境ではこれらのプラグインを使用しないでください。データベースと、同じ共有環境で実行される他のワークロード/アプリケーションに壊滅的な結果をもたらす可能性があります。
pgbench
kubectl CNPGプラグインコマンド pgbench
は、既存のPostgresクラスターに対してユーザー定義のpgbench
ジョブを実行します。
--dry-run
フラグを介して、後の変更/実行のためにジョブのマニフェストを生成できます。
pgbench を使用した一般的なコマンド構造は次のとおりです。
kubectl cnpg pgbench \
-n <namespace> <cluster-name> \
--job-name <pgbench-job> \
--db-name <db-name> \
-- <pgbench options>
注釈
pgbench を参照してください。
ジョブで使用される特定のオプションについては、
この例では、 pgbench
OLTPのような目的で、スケールファクター1000を使用してcluster-example
という名前のCluster のapp
データベースを初期化するpgbench-init というジョブを作成します。
kubectl cnpg pgbench \
--job-name pgbench-init \
cluster-example \
-- --initialize --scale 1000
注釈
これにより、100000000レコードを含むデータベースが生成され、ディスク上に約13GBの領域が必要です。
ジョブの進行状況は次の方法で確認できます。
kubectl logs jobs/pgbench-run
次の例では、単一の接続を使用して、以前に初期化されたデータベースに対して30秒間pgbench
を実行するpgbench-run というジョブを作成します。
kubectl cnpg pgbench \
--job-name pgbench-run \
cluster-example \
-- --time 30 --client 1 --jobs 1
次の例では、 --db-name フラグとpgbench
名前空間を使用して、既存のデータベースに対してpgbench
を実行します。
kubectl cnpg pgbench \
--db-name pgbench \
--job-name pgbench-job \
cluster-example \
-- --time 30 --client 1 --jobs 1
デフォルトでは、ジョブに有効期限はありません。 --ttl
フラグを使用して自動削除を有効にできます。ジョブは指定された期間秒単位で削除されます。
kubectl cnpg pgbench \
--job-name pgbench-run \
--ttl 600 \
cluster-example \
-- --time 30 --client 1 --jobs 1
特定のワーカーノードでpgbench ジョブを実行する場合は、
--node-selector オプションを使用できます。 workload=pgbench
ラベルを持つノードで以前の初期化ジョブを実行する場合、次のことを実行できます。
kubectl cnpg pgbench \
--db-name pgbench \
--job-name pgbench-init \
--node-selector workload=pgbench \
cluster-example \
-- --initialize --scale 1000
ジョブステータスは、次のコマンドを実行して取得できます。
kubectl get job/pgbench-job -n <namespace>
NAME COMPLETIONS DURATION AGE
job-name 1/1 15s 41s
ジョブが完了すると、次のことを実行して結果を収集できます。
kubectl logs job/pgbench-job -n <namespace>
fio
kubectl CNPGプラグインコマンド fio
は、デフォルト値と読み取り操作を使用してfioジョブを実行します。
--dry-run
フラグを介して、後の変更/実行のためにジョブのマニフェストを生成できます。
注釈
kubectlプラグインコマンド`fio` は、ConfigMapを使用して事前定義されたfioジョブ値を使用してデプロイメントを作成します。カスタムジョブ値を提供する場合は、 --dry-run フラグを使用してマニフェストを生成し、生成されたConfigMapでカスタムジョブ値を提供することをお勧めします。
デフォルトの使用例
kubectl cnpg fio <fio-name>
カスタム値を使用した例
kubectl cnpg fio <fio-name> \
-n <namespace> \
--storageClass <name> \
--pvcSize <size>
fio 名前空間のstandard およびpvcSize: 2Gi
という名前のStorageClass に対してfio
コマンドを実行する方法の例
kubectl cnpg fio fio-job \
-n fio \
--storageClass standard \
--pvcSize 2Gi
展開ステータスは、次のコマンドを実行して取得できます。
kubectl get deployment/fio-job -n fio
NAME READY UP-TO-DATE AVAILABLE AGE
fio-job 1/1 1 1 14s
kubectlプラグインコマンドfio を実行した後。
それは次のことを行います。
PVCを作成する
fioジョブの構成を表すConfigMapを作成します
単一のポッドで構成されるfio展開を作成し、PVCでfioを実行し、ベンチマークの完了後にグラフを作成し、ウェブサーバーで生成されたファイルの提供を開始します。そのためには、 fio-tools イメージを使用します。
デプロイメントによって作成されたポッドは、結果の提供を開始すると準備が整います。デプロイメントによって作成されるポッドのポートを転送できます
kubectl port-forward -n <namespace> deployment/<fio-name> 8000
次に、ブラウザを使用してhttp://localhost:8000/
に接続してデータを取得します。
PostgreSQLワークロードをエミュレートするために、デフォルトの8kブロックサイズが選択されました。使用可能なIOPSの量を制限するディスクは、このパラメーターを変更すると、非常に異なるスループット値を示す場合があります。
以下は、専用のKubernetesノードにマウントされたローカルディスクへのシークエンシャル書き込みの図の例1時間ベンチマーク。
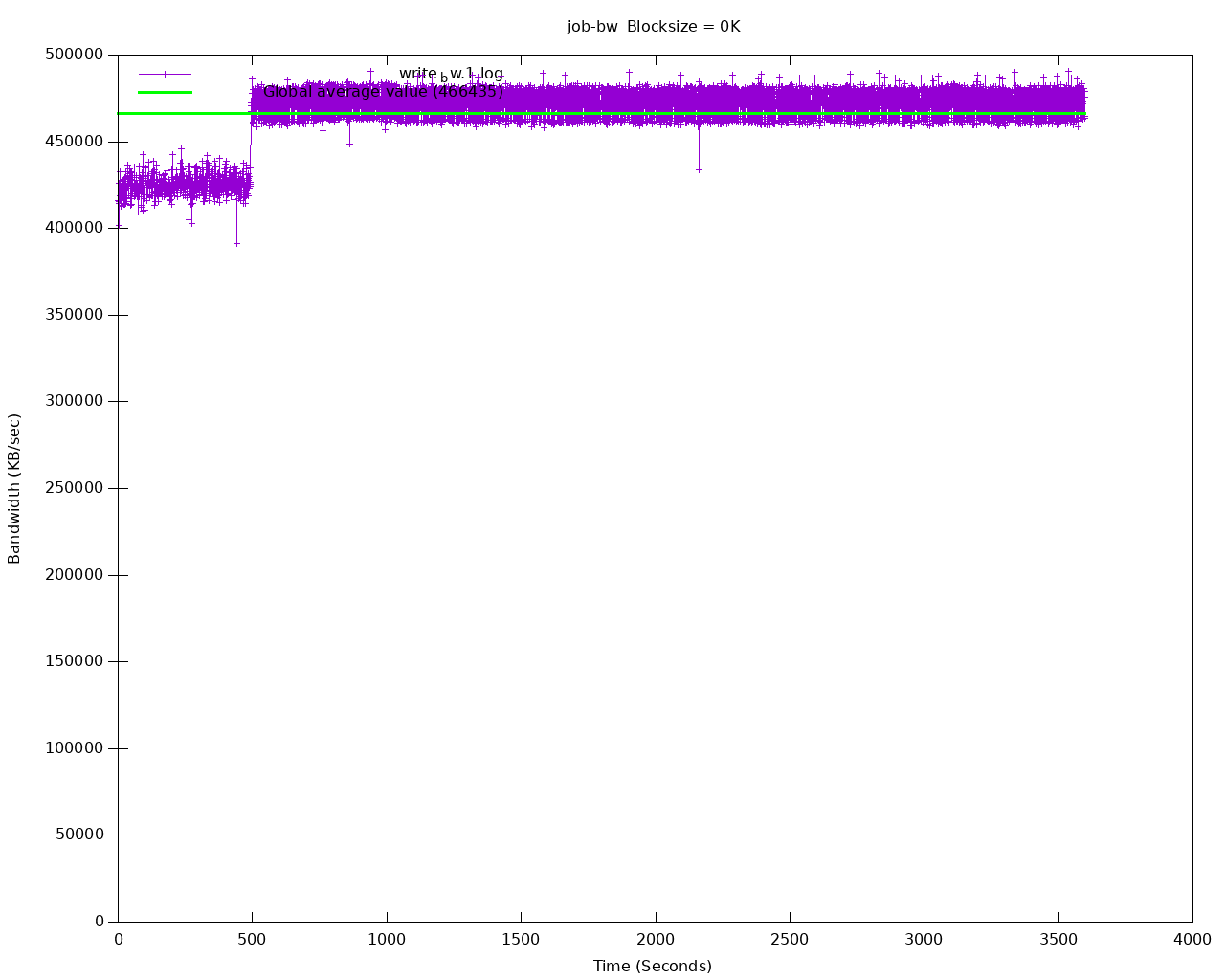
Sequential writes bandwidth
すべてのテストが完了したら、fio展開とリソースを次の方法で削除できます。
kubectl cnpg fio <fio-job-name> --dry-run | kubectl delete -f -
fio展開の作成に使用したものと同じ名前を使用して、必要に応じて名前空間を追加します。