Replica clusters
レプリカクラスターは、別のPostgreSQLインスタンスからデータをレプリケートするように設計されたCloudNativePG
Cluster
リソースであり、理想的にはCloudNativePGによって管理されます。
通常、レプリカクラスターは、別のリージョンの別のKubernetesクラスターに展開されます。これらのクラスターは、カスケードレプリケーションを実行するように構成でき、以下で詳しく説明するように、ソースからのデータレプリケーションのオブジェクトストアに依存できます。
レプリカクラスターには、主に2つのユースケースがあります。
ディザスターリカバリーと高可用性 ディザスターリカバリーとある程度、通常は異なるリージョンにあるさまざまなKubernetesクラスターにわたるCloudNativePGクラスターの高可用性を強化します。 CloudNativePG用語では、これは 分散トポロジ と呼ばれます。
読み取り専用ワークロード レポートやオンライン分析処理OLAPなどの目的で、PostgreSQLクラスターのスタンドアロンレプリカを作成します。これらのレプリカは、主に読み取り専用ワークロード用です。 CloudNativePG用語では、これは スタンドアロンレプリカクラスター と呼ばれます。
例、以下の図 — Architecture から取得
—は、主にディザスターリカバリーの目的で機能する対称レプリカクラスターを使用した、2つのKubernetesクラスターにまたがる分散PostgreSQLトポロジを示しています。
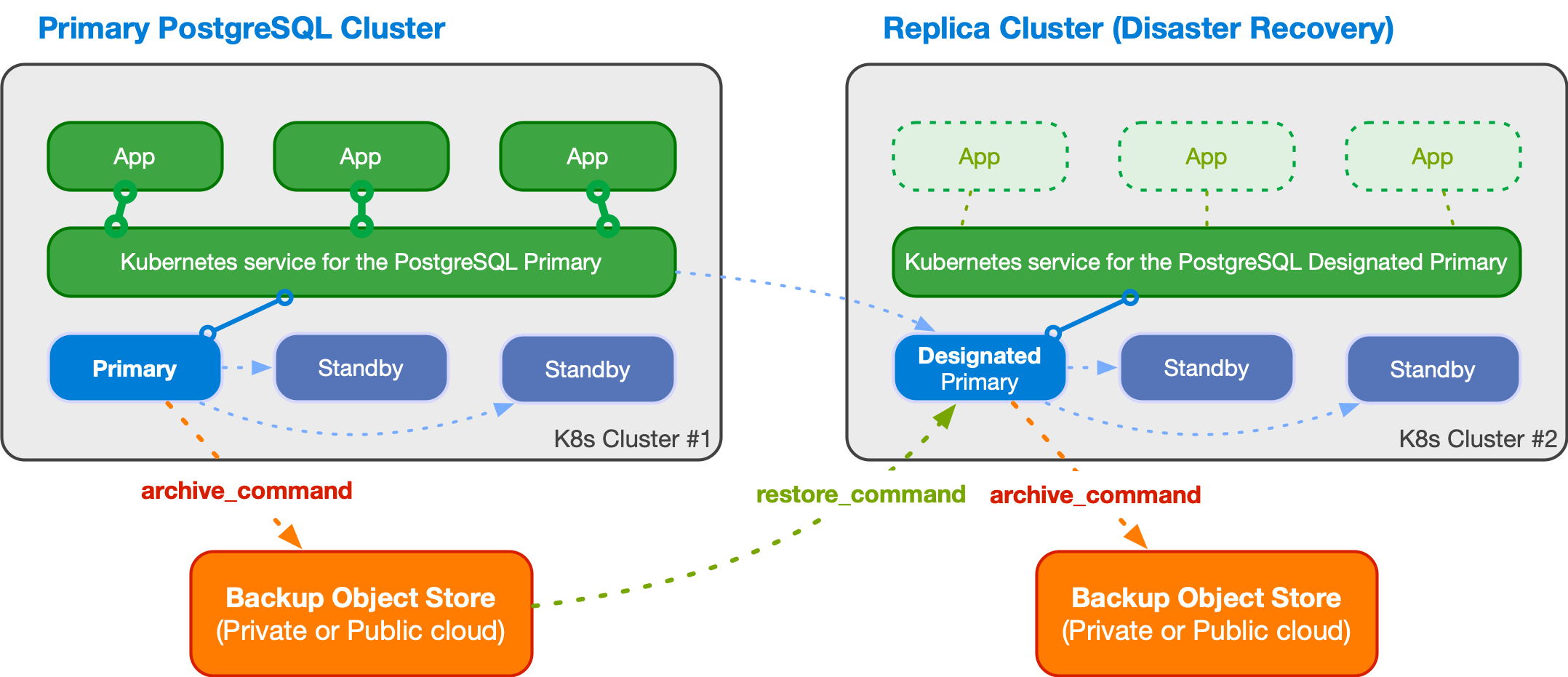
An example of multi-cluster deployment with a primary and a replica cluster
基本概念
CloudNativePGはPostgreSQLレプリケーションフレームワークをベースに構築されており、このセクションで説明するレプリカクラスター機能を使用して、既存のソースクラスターからPostgreSQLクラスターを作成および同期できます。ソースは、プライマリクラスターまたは別のレプリカクラスターカスケードレプリケーションです。
PostgreSQLのロールについて
レプリカクラスターは継続的リカバリモードで動作します。つまり、カタログを含むデータベースへの変更、およびロールやデータベースのようなグローバルオブジェクトは許可されません。これらの変更は、Cluster
がプライマリに移行するまで遅延されます。このフェーズでは、ロールなどのグローバルオブジェクトは、ソースクラスターで定義されたとおりに残ります。クラスターが昇格すると、CloudNativePGはローカル再定義を適用します。
クラスターを昇格する予定がない場合読み取り専用ワークロードの場合、またはレプリカクラスターが昇格したらソースクラスターから完全に切断する予定がある場合、アクションを実行する必要はありません。これは通常、 スタンドアロンレプリカクラスター の場合です。
ある時点でクラスターを昇格する予定がある場合、CloudNativePGは、レプリカクラスターからプライマリに移行するときに次のロールとパスワードを管理します。
アプリケーションユーザー
スーパーユーザー使用している場合
declarative interface を使用して定義されたロール
上記のロールとパスワードが変更されないことをシームレスに保証することが目的である場合、各Cluster
で上記に必要なシークレットを定義する必要があります。これは通常、
分散トポロジ の場合です。
レプリカクラスターのブートストラップ
最初のステップは、次のいずれかの方法を使用してレプリカクラスターをブートストラップすることです。
pg_basebackup経由の ストリーミングレプリケーションボリュームスナップショットからのリカバリ
オブジェクトストアの Barman Cloudバックアップからのリカバリ
pg_basebackup
ストリーミングまたはリカバリーボリュームスナップショットまたはオブジェクトストアを使用してPostgreSQLサーバーのクローンを作成する手順の詳細については、
Bootstrap を参照してください。
レプリケーションの構成
レプリカクラスターのベースバックアップが利用できるようになったら、PostgreSQL継続的リカバリーを使用してオリジンから変更をレプリケートする方法を定義する必要があります。 3つの主なオプションがあります。
ストリーミングレプリケーション レプリカクラスターとソース間のストリーミングレプリケーションを設定します。この方法では、ネットワーク接続を構成し、適切な管理およびセキュリティ対策を実装して、シームレスなデータ転送を保証する必要があります。
WALアーカイブ オブジェクトストアに保存されているWAL書き込み先行ログアーカイブを使用します。 WALファイルはソースクラスターからオブジェクトストアに定期的に転送され、そこから Barman Cloud のようなCNPG-Iプラグイン
restore_command を介してレプリカクラスターのそれらを取得します。
ハイブリッドアプローチ ストリーミングレプリケーションとWALアーカイブ方法の両方を組み合わせます。 PostgreSQLは、必要に応じてこれら2つのアプローチを管理および切り替えて、データの一貫性と可用性を保証できます。
外部クラスターの定義
外部クラスターを構成する場合、次のオプションがあります。
``plugin`` セクション
CNPG-I を使用したレプリカクラスターのブートストラップを有効にします
restore_job をサポートするプラグイン
および wal プロトコル. - CloudNativePGは Barman Cloud Plugin をサポートしています
オブジェクトストアからレプリカクラスターをブートストラップできるようにします。
``connectionParameters`` セクション
pg_basebackupセクションを使用したストリーミングレプリケーションを介したレプリカクラスターのブートストラップを有効にします。CloudNativePGは、指定されたプライマリインスタンスに
primary_conninfoオプションを自動的に設定し、ソースクラスターに接続してデータを受信するWALレシーバープロセスを開始します。
非推奨ですが、 ``barmanObjectStore`` セクション に引き続きアクセスできます。
CloudNativePGが指定されたプライマリインスタンスで
restore_commandを自動的に設定して、WALアーカイブの使用を有効にします。ボリュームスナップショットが実現できない場合、
recoveryセクションを使用してオブジェクトストアからレプリカクラスターをブートストラップできます。
バックアップおよびシンメトリックアーキテクチャ
レプリカクラスターは、指定されたプライマリから予約されたオブジェクトストアへのバックアップを実行でき、分散環境での対称アーキテクチャをサポートします。このアーキテクチャの選択は、制御されたデータセンターのスイッチオーバーまたは予期しないイベントに続くフェイルオーバー中にクラスターがプロモーションの準備ができるようにするため、重要です。
分散アーキテクチャの柔軟性
PostgreSQLデータベースの優先分散アーキテクチャを柔軟に設計でき、以下から選択できます。
プライベートクラウド 異なるデータセンターにある複数のKubernetesクラスターにまたがります。
パブリッククラウド さまざまなリージョンにある複数のKubernetesクラスターにまたがります。
ハイブリッドクラウド プライベートクラウドとパブリッククラウドを組み合わせます。
マルチクラウド さまざまなリージョンおよびクラウドサービスプロバイダーにまたがる複数のKubernetesクラスターにまたがります。
レプリカクラスターのセットアップ
ソースクラスターからレプリカクラスターをセットアップするには、次の手順に従ってクラスターYAMLファイルを作成し、それに応じて構成します。
外部クラスターの定義
externalClustersセクションで、レプリカクラスターを指定します。ディザスターリカバリーDRと高可用性HAを目的とした分散PostgreSQLトポロジの場合、このセクションはすべてのPostgreSQLクラスターに対して定義する必要があります分散データベースで。
レプリカクラスターのブートストラップ
ストリーミングブートストラップ ストリーミングレプリケーションを介したブートストラップには
pg_basebackupセクションを使用します。スナップショット/オブジェクトストアブートストラップ
recoveryセクションを使用してボリュームスナップショットからブートストラップまたはオブジェクトストア。
継続的リカバリ戦略
.spec.replicaスタンザで定義します。
分散トポロジ
externalClustersで定義された分散トポロジとともに、primary、source、およびselfフィールドを使用して構成します。これにより、CloudNativePGは、プライマリクラスターの降格と、その後のプロモーショントークンを使用したレプリカクラスターのプロモーションを宣言的に制御できます。スタンドアロンレプリカクラスター
enabledオプションを使用して継続的リカバリーを有効にし、sourceフィールドをポイントするように設定しますexternalClusters名前。この構成は、主に読み取り専用ワークロードを目的としたレプリカの作成に適しています。
継続的リカバリーのための分散トポロジーとスタンドアロンレプリカクラスター戦略の両方を以下で徹底的に説明します。
分散トポロジ
分散PostgreSQLデータベースの計画
ドワイト・アイゼンハワーの有名な言葉「計画がすべてです」。これは、KubernetesでのPostgreSQLアーキテクチャの設計にも当てはまります。
最初に、分散トポロジを紙の上で概念化し、それをCloudNativePG API構成に変換します。この構成には、主に次のものが含まれます。
externalClustersセクション。分散PostgreSQLセットアップ内のすべてのCluster定義に含める必要があります。.spec.replicaスタンザ、具体的にはprimary、source、およびオプションのselfフィールド。
たとえば、南ヨーロッパと中央ヨーロッパにある2つのKubernetesクラスターに分散されたPostgreSQLクラスターを展開するとします。
このシナリオでは、南ヨーロッパのKubernetesクラスターにCloudNativePGがインストールされており、プライマリとして機能するcluster-eu-south
という名前のPostgreSQL Cluster
を使用していることを前提としています。このクラスターには、ローカルオブジェクトストアで構成された継続的バックアップがあります。このオブジェクトストアには、中央ヨーロッパのKubernetesクラスターにインストールされているcluster-eu-central
という名前のPostgreSQL Cluster
からもアクセスできます。最初に、cluster-eu-central
はレプリカクラスターとして機能します。対称的なアプローチに従い、継続的バックアップ用のローカルオブジェクトストアも持っています。これは、
cluster-eu-south によって読み取られる必要があります。
この例では、復旧はWALシッピングのみを介して実行され、2つのクラスター間のストリーミングレプリケーションは行われません。ただし、 “Configuring replication” で説明しているように、ストリーミングレプリケーションを単独で使用するか、ハイブリッドアプローチつまりフォールバックとしてWALシッピングを使用したストリーミングレプリケーションを採用するようにセットアップを構成できます。
セクション。
次に、オブジェクトストアのBarman
Cloudプラグインに依存して、両方のCluster
リソースのexternalClusters セクションを構成する方法を示します。
## Distributed topology configuration
externalClusters:
- name: cluster-eu-south
plugin:
name: barman-cloud.cloudnative-pg.io
parameters:
barmanObjectName: cluster-eu-south
serverName: cluster-eu-south
- name: cluster-eu-central
plugin:
name: barman-cloud.cloudnative-pg.io
parameters:
barmanObjectName: cluster-eu-central
serverName: cluster-eu-central
cluster-eu-south PostgreSQLプライマリCluster
の.spec.replica スタンザは次のように構成する必要があります。
replica:
primary: cluster-eu-south
source: cluster-eu-central
一方、 cluster-eu-central PostgreSQLレプリカCluster
の.spec.replica スタンザは次のように構成する必要があります。
replica:
primary: cluster-eu-south
source: cluster-eu-south
この構成では、 primary フィールドがCluster
リソースまたは別のものが使用される場合は.spec.replica.self
の名前と一致する場合、現在のクラスターは分散トポロジのプライマリと見なされます。それ以外の場合、source
この場合、
Barmanオブジェクトストアを使用してからのレプリカとして設定されます。
この設定により、複数のKubernetesクラスターにわたる分散PostgreSQLアーキテクチャを効率的に管理でき、宣言的構成を使用したプライマリPostgreSQLクラスターの制御されたスイッチオーバーを介して、高可用性とディザスターリカバリーの両方を保証します。
分散トポロジにおける制御されたスイッチオーバーは、以下を含む2段階のプロセスです。
プライマリクラスターのレプリカクラスターへの降格
レプリカクラスターのプライマリクラスターへのプロモーション
これらのプロセスについては、次のセクションで説明します。
注釈
続行する前に、必ずご確認ください PostgreSQLのロールについて
上記であり、分散トポロジに参加しているすべてのCluster
オブジェクトでシークレットを含む同一のロール定義を使用します。
プライマリのレプリカクラスターへの降格
CloudNativePGは、プライマリクラスターをレプリカクラスターに降格する機能を提供します。このアクションは、通常、プライマリロールをあるデータセンターから別のデータセンターに移行するときに計画されます。このプロセスには、現在のプライマリクラスターたとえばcluster-eu-south
をレプリカクラスターに降格し、その後、完全に同期したときに指定されたレプリカクラスターcluster-eu-central
をプライマリに昇格させることが含まれます。
新しいプライマリになるように選択されたレプリカクラスターをポイントする現在のプライマリCluster
リソースで外部クラスターを定義している場合、次のようにprimary
フィールドを変更するだけです。
replica:
primary: cluster-eu-central
source: cluster-eu-central
プライマリPostgreSQLクラスターが降格されると、書き込み操作は可能でなくなります。 CloudNativePGの場合
シャットダウンチェックポイントを含むWALファイルをWALアーカイブの
.partialファイルとしてアーカイブします。ステータスに
demotionToken、システム識別子、タイムスタンプ、タイムラインID、REDOロケーション、最新のチェックポイントのREDO WALファイルなど、pg_controldataからの関連情報を含むbase64エンコードされたJSON構造を生成します。
最初のステップは、WALアーカイブのみを使用して継続的リカバリプロセスにフィードを与えるために降格/プロモートする必要がありますストリーミングレプリケーションなしで。
2番目のステップ .status.demotionToken の生成
は、データの損失や元のプライマリをリビルドすることなく、スムーズな降格/プロモーションプロセスを保証します。
この段階で、元のプライマリはレプリカクラスターに移行し、新しいグローバルプライマリ
cluster-eu-central からのWALデータを待機しています。
他のクラスターの昇格を続行するには、次のコマンドを使用してcluster-eu-south
からdemotionToken を取得する必要があります。
kubectl get cluster cluster-eu-south \
-o jsonpath={.status.demotionToken}
cnpg
プラグインを使用して、クラスターのステータスを確認してdemotionToken
を取得できます。トークンはDemotion token
セクションの下にリストされています。
注釈
cluster-eu-south から取得した`demotionToken` は、cluster-eu-central の`promotionToken` になります。
cnpg
プラグインを使用して、クラスターのステータスを確認して、ロールの変更を確認できます。
kubectl cnpg status cluster-eu-south
レプリカのプライマリクラスターへの昇格
PostgreSQLレプリカクラスターcluster-eu-central
などをプライマリクラスターに昇格させ、指定されたプライマリを実際のプライマリインスタンスにするには、次の手順を同時に実行する必要があります。
.spec.replica.primaryを、昇格する現在のレプリカクラスターの名前に設定しますcluster-eu-centralなど。.spec.replica.promotionTokenを、以前のプライマリクラスターから取得した値で設定します プライマリのレプリカクラスターへの降格 を参照してください。
cluster-eu-central の仕様の更新されたreplica
セクションは次のようになります。
replica:
primary: cluster-eu-central
promotionToken: <PROMOTION_TOKEN>
source: cluster-eu-south
警告
変更を`primary` および`promotionToken` フィールドに同時に適用することが重要です。プロモーショントークンを省略すると、フェールオーバーがトリガーされ、以前のプライマリのリビルドが必要になります。
これらの調整を行った後、CloudNativePGは、レプリカクラスターのプライマリクラスターへのプロモーションを開始します。最初に、CloudNativePGは、指定されたプライマリクラスターが、トークンに含まれる指定されたログシーケンス番号LSNまでのすべての書き込み先行ロギングWAL情報をレプリケートするのを待機します。この目標を達成すると、プロモーションプロセスが開始されます。新しいプライマリクラスターは、タイムラインを切り替え、履歴ファイルと新しいWALをアーカイブすることにより、レプリカとして動作するcluster-eu-south
クラスターのレプリケーションプロセスのブロックを解除します。
ロールの変更を確認するには、 cnpg
プラグインを使用して、クラスターのステータスを確認します。
kubectl cnpg status cluster-eu-central
このコマンドは、cluster-eu-central
の現在のステータスを提供し、プライマリへの昇格を確認します。
これらの手順に従うことで、スムーズで制御されたプロモーションプロセスを保証し、中断を最小限に抑え、PostgreSQLクラスター全体でデータの整合性を維持できます。
スタンドアロンレプリカクラスター
注釈
スタンドアロンレプリカクラスターは、CloudNativePG 1.24で分散トポロジ戦略を導入する前は、レプリカクラスターと呼ばれていました。
CloudNativePGでは、スタンドアロンレプリカクラスターは、次の構成で継続的にリカバリーしているPostgreSQLクラスターです。
.spec.replica.enabledをtrueに設定.spec.replica.sourceフィールドを介して定義された物理レプリケーションソース、externalClusters名前を指す
.spec.replica.enabled がfalse
に設定されている場合、レプリカクラスターは継続的リカバリモードを終了し、プライマリクラスターになり、元のソースから完全に分離されます。
警告
レプリケーションの無効化は、**不可逆的な**オペレーションです。レプリケーションが無効になり、指定されたプライマリがプライマリに昇格すると、レプリカクラスターとソースクラスターは決定的に2つの独立したクラスターになります。
注釈
スタンドアロンレプリカクラスターは、主に読み取り専用のワークロードが関係するいくつかのユースケースに適しています。ディザスターリカバリーソリューションのセットアップを予定している場合は、上記の「分散トポロジ」を確認してください。
分散トポロジとの主な違い
スタンドアロンレプリカクラスターは、ディザスターリカバリーの目的で使用できますが、いくつかの重要な点で「分散トポロジ」戦略とは異なります。
分散データベース概念の欠如 スタンドアロンレプリカクラスターは、単純な形式2つのクラスターまたはより複雑な構成たとえば、円形トポロジの3つのクラスターなど、分散データベースの概念をサポートしていません。
グローバルプライマリクラスターなし スタンドアロンレプリカクラスターには、グローバルプライマリクラスターの概念がありません。
制御されたスイッチオーバーなし スタンドアロンレプリカクラスターは、プライマリにのみ昇格できます。制御されたスイッチオーバーは不可能であるため、以前のプライマリクラスターは再クローンを作成する必要があります。
フェールオーバーは両方の戦略で同じであるため、元のプライマリが復旧した場合は再クローンを作成する必要があります。
pg_basebackup を使用したスタンドアロンレプリカクラスターの例
この 最初の例 は、ブートストラップと継続的リカバリーの両方でストリーミングレプリケーションを使用して、スタンドアロンレプリカクラスターを定義します。レプリカクラスターは、TLS認証を使用してソースクラスターに接続します。
samples/ サブディレクトリ。
ソースクラスターを指しているbootstrap およびreplica
セクションに注意してください。
bootstrap:
pg_basebackup:
source: cluster-example
replica:
enabled: true
source: cluster-example
前述の構成では、アプリケーションデータベースとその所有ユーザーがデフォルトのapp
に設定されていることを前提としています。リストアするPostgreSQLクラスターが別の名前を使用している場合、
アプリケーションデータベースの構成 の文書に従ってそれらを指定する必要があります。また、元のクラスターからアプリケーションユーザーシークレットをコピーし、ソースとの同期を維持することを検討する必要があります。詳細は、
PostgreSQLのロールについて を参照してください。
externalClusters セクションでは、 connectionParameters
サブセクションのホストに対応した適切な名前空間を使用することに注意してください。レプリカクラスターが別の名前空間にある場合、
-replication および-ca
シークレットは、必要に応じてコピーしておく必要があります。
externalClusters:
- name: <MAIN-CLUSTER>
connectionParameters:
host: <MAIN-CLUSTER>-rw.<NAMESPACE>.svc
user: streaming_replica
sslmode: verify-full
dbname: postgres
sslKey:
name: <MAIN-CLUSTER>-replication
key: tls.key
sslCert:
name: <MAIN-CLUSTER>-replication
key: tls.crt
sslRootCert:
name: <MAIN-CLUSTER>-ca
key: ca.crt
オブジェクトストアからのスタンドアロンレプリカクラスターの例
2番目の例 は、 recovery
セクションと継続的リカバリーを使用してオブジェクトストアからブートストラップするレプリカクラスターを定義します。ストリーミングレプリケーションと特定のオブジェクトストアの両方を使用します。ストリーミングレプリケーションの場合、レプリカクラスターは基本認証を使用してソースクラスターに接続します。
samples/ サブディレクトリにあります。
ソースクラスターを指しているbootstrap およびreplica
セクションに注意してください。
bootstrap:
recovery:
source: cluster-example
replica:
enabled: true
source: cluster-example
前述の構成では、アプリケーションデータベースとその所有ユーザーがデフォルトのapp
に設定されていることを前提としています。リストアするPostgreSQLクラスターが別の名前を使用している場合、
アプリケーションデータベースの構成 の文書に従ってそれらを指定する必要があります。また、元のクラスターからアプリケーションユーザーシークレットをコピーし、ソースとの同期を維持することを検討する必要があります。詳細については、
PostgreSQLのロールについて を参照してください。
externalClusters セクションでは、 endpointURL
およびconnectionParameters.host
で適切な名前空間を使用するように注意してください。また、必要に応じて必要なシークレットがコピーされていること、およびソースクラスターのバックアップが既に作成されていることを確認してください。
externalClusters:
- name: <MAIN-CLUSTER>
# Example with Barman Cloud Plugin
plugin:
name: barman-cloud.cloudnative-pg.io
parameters:
barmanObjectName: <MAIN-CLUSTER>
serverName: <MAIN-CLUSTER>
…
connectionParameters:
host: <MAIN-CLUSTER>-rw.default.svc
user: postgres
dbname: postgres
password:
name: <MAIN-CLUSTER>-superuser
key: password
注釈
ソースクラスターとレプリカクラスター間でストリーミングレプリケーションを使用するには、2つのクラスター間のネットワーク接続があることを確認し、パスワードまたは証明書を保持する必要なシークレットがすべて事前に適切に作成されていることを確認する必要があります。
ボリュームスナップショットを使用した例
ボリュームスナップショットを使用し、ストレージクラスがスナップショットクラスター間の可用性を提供する場合、それを活用して、ソースクラスターのボリュームスナップショットを介してレプリカクラスターをブートストラップできます。
3番目の例 は、 recovery
セクションを使用してボリュームスナップショットからブートストラップするレプリカクラスターを定義します。ストリーミングレプリケーション基本認証を介して、オブジェクトストアを使用してWALファイルを取得します。
samples/ サブディレクトリにあります。
この例では、アプリケーションデータベースとその所有ユーザーがデフォルトのapp
に設定されていることを前提としています。リストアするPostgreSQLクラスターが別の名前を使用している場合、
Configure theapplication database の文書に従ってそれらを指定する必要があります。また、元のクラスターからアプリケーションユーザーシークレットをコピーし、ソースとの同期を維持することを検討する必要があります。詳細については、
PostgreSQLのロールについて を参照してください。
遅延レプリカ
CloudNativePGは、 PostgreSQLの recovery_min_apply_delay を活用して、 .spec.replica.minApplyDelay を介して 遅延レプリカ の作成をサポートしています。
遅延レプリカは、指定された時間プライマリデータベースより意図的に遅延するように設計されています。この遅延は、
PostgreSQLの基になるrecovery_min_apply_delay
パラメーターにマップする.spec.replica.minApplyDelay
オプションを使用して構成できます。
遅延レプリカの主な目的は、プライマリデータベースでの意図しないSQLステートメントの実行の影響を軽減することです。これは、
UPDATE やDELETE などの操作が適切なWHERE
句なしで実行されるシナリオで特に役立ちます。
レプリカクラスターで遅延を構成するには、 .spec.replica.minApplyDelay
オプションを調整します。このパラメーターは、レプリカがプライマリからどれくらいの時間を決定します。例
# ...
replica:
enabled: true
source: cluster-example
# Enforce a delay of 8 hours
minApplyDelay: 8h
# ...
上記の例では、8時間のバッファ期間を提供して、問題がレプリカに伝播する前に検出および修正することにより、誤ったデータの変更に対する安全対策に役立ちます。
目標復旧時間と意図しないプライマリデータベース操作の潜在的な影響に基づいて、必要に応じて遅延を監視および調整します。
遅延レプリカの主な使用ケースは次のように要約できます。
人的エラーの軽減 プライマリデータベースでの意図しないSQL操作に起因するデータの破損または損失のリスクを削減します。
復旧時間の最適化 変更が他のレプリカに適用される前に問題を特定および修正できる遅延レプリカを使用することにより、意図しない変更からの迅速な復旧を促進します。
データ保護の強化 不要な変更の伝播を介入および防止する機会を提供する時間バッファを導入することにより、重要なデータを保護します。
警告
遅延レプリカの`minApplyDelay` オプションは、promotionToken と組み合わせて使用することはできません。
遅延レプリカをレプリケーション戦略に統合することにより、PostgreSQL環境の復元力とデータ保護機能を強化できます。特定のニーズとデータの重要度に基づいて、遅延期間を調整します。
注釈
常に目標を測定します。環境によっては、より迅速な結果を得るには、ボリュームスナップショットベースのリカバリーに依存する方が効率的である場合があります。独自の要件とインフラストラクチャに最適なアプローチを評価および選択します。