Frequently Asked Questions (FAQ)
KubernetesでのPostgreSQLの実行
**PostgreSQLのようなステートフルワークロードはKubernetesでは実行できないことは誰もが知っています。なぜ逆に言うのですか?*
2021年9月の *independent research survey commissioned by the Data on KubernetesCommunity* では、回答者の半数が運用ワークロードのほとんどをKubernetesで実行していることが明らかになりました。 90%がKubernetesがステートフルワークロードに対応する準備ができていると考えており、70%が本番環境でデータベースを実行しています。 Postgresのようなデータベース。しかし、彼らによると、知識ギャップ一般にKubernetesとクラウドネイティブは急な学習曲線を持っていますや、Kubernetesオペレーターの品質など、重要な課題が残っています。後者は、CloudNativePGのようなオペレーターがプロジェクトの成功に大きく貢献すると信じる理由です。
私たちのようなデータベース愛好家にとって、真のゲームチェンジャーは、 *Kubernetes 1.14 in April 2019* でのローカル永続ボリュームのサポートの導入でした。
CloudNativePGは、不変のアプリケーションコンテナに基づいて構築されています。それはどういう意味ですか?
マイクロサービスアーキテクチャパターンによると、コンテナは単一のアプリケーションまたはプロセスを実行するように設計されています。その結果、このようなコンテナイメージは、メインアプリケーションを単一のエントリポイントいわゆるPID 1プロセスとして実行するようにビルドされます。
Kubernetesの用語では、アプリケーションはワークロードと呼ばれます。ワークロードは、Webアプリケーションサーバーのようなステートレスまたはデータベースのようなステートフルにすることができます。この概念をPostgreSQLにマッピングすると、不変アプリケーションコンテナは、実行され、単一の特定のバージョン不変コンテナイメージ内のバージョンに関連付けられている単一の「postgres」プロセスです。
SSH、systemd、またはsyslogなどの他のプロセスは許可されません。
不変のアプリケーションコンテナは、依然としてコンテナを解釈して使用する非常に一般的な方法である可変システムコンテナとは対照的です。
不変とは、コンテナがその存続期間中に変更されないことを意味します。更新、パッチ、構成変更はありません。アプリケーションコードを更新するか、パッチを適用する必要がある場合は、新しいイメージをビルドして再展開します。不変性により、展開がより安全で反復可能になります。
詳細については、 *"Why EDB chose immutable application containers"* を参照してください。
クラウドネイティブとはどういう意味ですか?
Cloud Native Computing Foundationは、用語「 *Cloud Native* 」を定義しています。ただし、2ndQuadrantでCloud Native PostgreSQL / CloudNativePGオペレーターが開始されて以来、開発チームはクラウドネイティブを3つの主要なコンセプトとして解釈してきました。
人、および原則とプロセスに基づいた、既存の健全で、本物の、豊かなDevOps文化。これにより、チームと組織がチームのチームとして継続的に変化し、結果と成果の提供を革新および加速できます。より安全、より効率、そしてより魅力的な方法でビジネスの価値を引き出します
不変のアプリケーションコンテナに基づいたマイクロサービスアーキテクチャ
Kubernetesなどのこれらのコンテナを管理およびオーケストレーションする方法
現在、コンテナオーケストレーションのデファクト標準はKubernetesであり、クラウドネイティブアプリケーションの展開、管理、およびスケーラビリティを自動化します。
私たちの共鳴をもたらすクラウドネイティブのもう1つの定義は、 *"Kubernetes Patterns", published by O'Reilly* でIbryamとHußによって定義されたものです。
コンテナ化されたマイクロサービスを大規模に自動化するための原則、パターン、ツール
ベアメタルKubernetesでCloudNativePGを実行できますか?
はい、確かに。ベアメタルでKubernetesを実行できます。また、ローカルに接続されたストレージを使用する1つ以上の物理ワーカーノードをPostgreSQLワークロード専用にすると、最大かつ予測可能なI/Oパフォーマンスを実現できます。
CloudNativePGの元となる実際のクラウドネイティブPostgreSQLプロジェクトは、同じベアメタルサーバー上のストレージとPostgreSQLを、最初にLinuxで直接、次にKubernetes内でベンチマークした2019年のパイロットプロジェクトの後に生まれました。予想されたように、実験では、ローカル永続ボリュームを介してKubernetesで実行されているコンテナによってもたらされたパフォーマンスへのごくわずかな影響のみが示されたため、クラウドネイティブイニシアチブを続行できます。
ファイルシステムレプリケーションの代わりにPostgreSQLレプリケーションを使用する必要があるのはなぜですか?
Architecture: Synchronizing the state をお読みください
セクション。
PostgreSQLをコンテナとして実行する代わりに、オペレーターを使用する必要があるのはなぜですか?
KubernetesでPostgreSQLを実行するための最も基本的なアプローチは、Kubernetesでの展開の最小単位であるポッドを使用し、レプリカのないPostgresコンテナを実行することです。 Postgresデータディレクトリをホスティングするボリュームはポッドにマウントされ、通常はネットワークストレージにあります。この場合、Kubernetesは問題が発生した場合にポッドを再起動するか、別のKubernetesノードに移動します。
最も洗練されたアプローチは、演算子を使用してPostgreSQLを実行することです。オペレーターはKubernetesコントローラーの拡張機能であり、ビジネス継続性のコンテキストで複雑なアプリケーションがどのように動作するかを定義します。演算子パターンは、この目的のためのKubernetesの現在最先端の技術です。オペレーターは、自動化されたプログラム的な方法で人間のオペレーターの作業をシミュレートします。
Postgresは複雑なアプリケーションであり、オペレーターはクラスターを展開する最初のステップだけでなく、予期しないイベントの後に適切に対応する必要があります。典型的な例は、フェイルオーバーの例です。
オペレーターは、自己修復、スケーラビリティ、レプリケーション、高可用性、バックアップ、リカバリー、更新、アクセス、リソース制御、ストレージ管理などの機能でKubernetesに依存しています。また、ログ管理および監視インフラストラクチャへのPostgreSQLクラスターの統合も促進します。
CloudNativePGは、宣言的構成を介してPostgreSQLクラスターの目的の状態を定義できます。 Kubernetesは、Kubernetesコントローラによって開始される調整ループを介して、インフラストラクチャの現在の状態が目的の状態と一致することを継続的に確認します。目的の状態と実際の状態が一致しない場合、調整ループは自己修復プロシージャーをトリガーします。そこで、CloudNativePGのようなオペレーターが登場します。
Postgresの他の演算子はありますか?
はい、もちろんです。そして、私たちのアドバイスは、決定を行う前に、それらをすべて見てCloudNativePGと比較することです。これらのオペレーターのほとんどは、外部フェールオーバー管理ツールPatroniまたは同様のツールを使用し、StatefulSetに依存していることがわかります。
これは、GitHubでの公開からの時系列での非完全なリストです。
Stackgres 2020
edb_lk_asis_102021
edb_lk_asis_112021
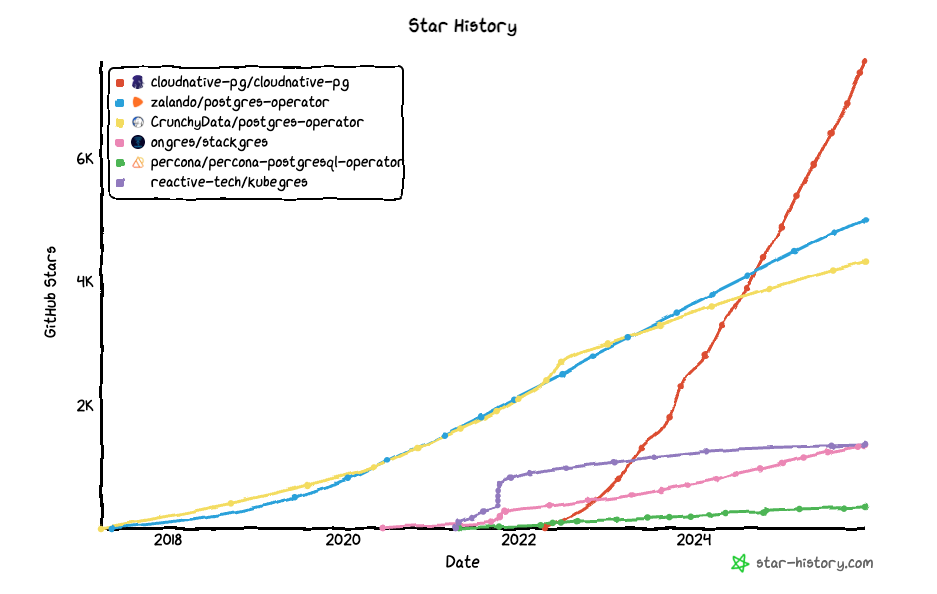
Star History Chart
関連する欠落エントリをPRとしてご自由に報告してください。
メンテナーの一部を含むは、 Operator Feature Matrix と呼ばれるオペレーターをリストする独立したベンダー中立プロジェクトに取り組んでいます。
CloudNativePGは完全な宣言的演算子であると言います。それはどういう意味ですか?
最も簡単な方法は、命令的構成との違いを強調する例を介して宣言的構成を説明することです。命令的コンテキストでは、状態は順番に実行される一連のタスクとして定義されます。したがって、最初のインスタンスを作成し、レプリケーションの構成、2番目のインスタンス、3番目のインスタンスのクローンを作成することにより、3ノードのPostgreSQLクラスターを取得できます。
宣言的アプローチでは、システムの状態は構成を使用して定義されます。つまり、2つのレプリカを持つPostgreSQL 13クラスターがあります。このアプローチは、変更管理操作を非常に簡素化し、これらがGitのようなソース制御システムに保存されると、Infrascriptor as Code機能が有効になります。そして、Kubernetesは、私たちの要求が常に満たされることを保証するため、展開よりもさらに進んでいます。
KubernetesでPostgreSQLを実行するために必要なスキルは何ですか?
KubernetesでPostgreSQLを実行するには、DevOpsチームにPostgreSQLとKubernetesの両方のスキルが必要です。最高のエクスペリエンスは、データベース管理者がKubernetesのコア概念を理解し、Kubernetes管理者と対話できる場合です。
私たちのアドバイスは、クラウドネイティブPostgreSQLを完全に活用して、CNCF認定プログラムから「Certified Kubernetes AdministratorCKA」ステータスを取得したいと考えているすべての人を対象としています。
CloudNativePGはステートフルセットを使用しないのはなぜですか?
CloudNativePGはStatefulSet
リソースに依存せず、代わりに、動的プロビジョニング用に選択されたストレージクラスを活用して、基になるPVCを直接管理します。この決定の背後にある理由と詳細については、
Custom Pod Controller セクションを参照してください。
高可用性
オペレーターポッドが停止するか、特定の時間使用できない場合、PostgreSQLクラスターはどうなりますか?
CloudNativePGオペレーターは、特に、自己修復機能を担当します。そのため、オペレーターの停止中は利用できない場合があります。
ただし、停止がPostgreSQLクラスターが実行されているノードに影響を与えないと仮定すると、データベースは、関連するKubernetesサービスを介して通常の操作を提供し続けます。さらに、各PostgreSQLポッド内で実行される インスタンスマネージャーのインプレース更新 は引き続き動作し、ロギング、メトリックのエクスポート、WALファイルの継続的アーカイブなどのアクセサリサービスを含む、データベースサーバーがアップしていることを確認します。
要約すると
オペレーターの停止は、必ずしもPostgreSQLデータベースの停止を意味するわけではありません。それは、 DBAまたはシステム管理者なしでデータベースを実行するようなものです。
CloudNativePGがPatroni、repmgr、Stolonのようなフェールオーバー管理ツールに依存しない理由は何ですか?
CloudNativePGを開発するチームの一部は、過去にrepmgrに深く関わっていましたが、私たちは別のアプローチを取ってKubernetesコントローラを直接拡張し、Kubernetes APIサーバーに依存してPostgresクラスターのステータスを保持し、使用することにしました。以下の真実の唯一の情報源として
主に自動フェイルオーバーとスイッチオーバーを介してPostgresクラスターの高可用性を制御し、 インスタンスマネージャーのインプレース更新 と調整します
Kubernetesサービス、つまりアプリケーションのエントリポイントを制御します
フェールオーバーに続いて、元のプライマリを新しいプライマリと手動で再同期する必要がありますか?
いいえ。オペレーターはそれを自動的に行い、 pg_rewind
に依存して元のプライマリと新しいプライマリを同期します。