Importing Postgres databases
このセクションでは、新しいCloudNativePGクラスター内に1つ以上の既存のPostgreSQLデータベースをインポートする方法について説明します。
インポート操作は、PostgreSQLのオンライン論理バックアップの概念に基づいており、オリジンホストへのネットワーク接続を介してpg_dump
、およびpg_restore
に依存します。ネイティブのマルチバージョン同時実行制御MVCCとスナップショットのおかげで、PostgreSQLでは、書き込みアクティビティを停止せずに、ネットワークを介して同時実行の方法で、一貫したバックアップを取得できます。
論理バックアップは、PostgreSQLバージョンのメジャーアップグレードを実行するための最も一般的な柔軟で信頼性の高い技術でもあります。
その結果、このセクションの手順は両方の場合に適しています。
Kubernetesの外部でも、既存のPostgreSQLインスタンスから1つ以上のデータベースをインポート
PostgreSQLバージョンから同じまたは新しいバージョンにデータベースをインポートし、PostgreSQLの メジャーアップグレード を有効にしますバージョン13.xからバージョン17.xなど
警告
PostgreSQLのメジャーアップグレードを実行するときは、アプリケーションが新しいバージョンと互換性があり、データベース拡張機能を含むオブジェクトのアップグレードパスが実行可能であることを確認する責任があります。
どちらの場合も、操作は元のデータベースの一貫した スナップショット で実行されます。
注釈
このため、バックアップの開始後にソースデータベースに行われた変更は宛先クラスタにないため、 Cluster リソースの最終インポートの前にソースの書き込み操作を停止することをお勧めします。したがって、この機能が参照される理由「オフラインインポート」または「オフラインメジャーアップグレード」として。
その仕組み
概念的には、インポートには、 空のクラスターをブートストラップする `initdb <空のクラスターをブートストラップする initdb>` を使用して新しいクラスター
宛先クラスター を作成し、 initdb.import
サブセクションを完了して、既存のPostgresクラスター ソースクラスター
からオブジェクトをインポートする必要があります。
PostgreSQLの推奨事項に従って、 宛先クラスター
のPostgreSQLメジャーバージョンが ソースクラスター
のバージョン以上であることをお勧めします。
CloudNativePGは、ソースクラスターから宛先クラスターにオブジェクトをインポートする2つの主な方法を提供します。
マイクロサービスアプローチ 宛先クラスターは、CloudNativePGプロジェクトで推奨されているように、指定されたアプリケーションユーザーが所有する単一のアプリケーションデータベースをホストするように設計されています
モノリスアプローチ 宛先クラスターは、ソースクラスターからインポートされた複数のデータベースとさまざまなユーザーをホストするように設計されています。
最初のインポート方法はmicroservice
タイプを介して使用でき、2番目はmonolith
タイプを介して使用できます。
警告
宛先クラスターが、スーパーユーザーまたは`pg_dump` で論理バックアップを取るための十分な特権を持つユーザーでソースクラスターにアクセスできることを確認するのはあなたの責任です。 PostgreSQL documentation on `pg_dump <https://www.postgresql.org/docs/current/app-pgdump.html>`_ を参照してください。
詳細については、
microservice タイプ
マイクロサービスアプローチでは、ソースクラスターから宛先クラスターにインポートする単一のデータベースを指定できます。操作は4つのステップで実行されます。
新しいクラスターの
initdbブートストラップpg_dump -Fdを使用した選択したデータベースinitdb.import.databases内のエクスポートinitdb.ownerユーザーが所有するinitdb.databaseアプリケーションデータベースへのpg_restore --no-acl --no-ownerを使用したデータベースのインポートデータベースダンプファイルのクリーンアップ
postImportApplicationSQLパラメーターを介してアプリケーションデータベースでのユーザー定義のSQLクエリーのオプションの実行インポートされたデータベースでの
ANALYZE VERBOSEの実行
次の図では、 N データベースを含む単一のPostgreSQLクラスターが別のCloudNativePGクラスターにインポートされ、各クラスターが N ソースデータベースのいずれかに対するマイクロサービスインポートを使用します。
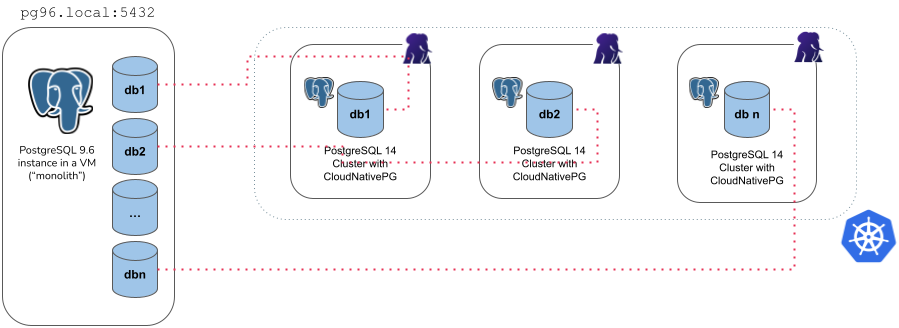
Example of microservice import type
たとえば、以下のYAMLは、 postgres
に接続することにより、cluster-pg96
クラスターサポートされていないPostgreSQL 9.6からangus
データベースをインポートするcluster-microservice
と呼ばれる新しい3インスタンスのPostgreSQLクラスターオペレーターがリリースされた時点での利用可能な最新のメジャーバージョンを作成しますcluster-pg96-superuser
シークレットに保存されたパスワードを介して、 postgres
ユーザーを使用してデータベースにアクセスします。
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: cluster-microservice
spec:
instances: 3
bootstrap:
initdb:
import:
type: microservice
databases:
- angus
source:
externalCluster: cluster-pg96
#postImportApplicationSQL:
#- |
# INSERT YOUR SQL QUERIES HERE
storage:
size: 1Gi
externalClusters:
- name: cluster-pg96
connectionParameters:
# Use the correct IP or host name for the source database
host: pg96.local
user: postgres
dbname: postgres
password:
name: cluster-pg96-superuser
key: password
警告
上記の例では、コミュニティ、したがってCloudNativePGでサポートされていないバージョンのPostgreSQLを実行しているソースデータベースを意図的に使用しています。ソースインスタンスからのデータのエクスポートは、宛先クラスターの`pg_dump` のバージョンを使用して実行されます。これは、サポートされているものであり、ソースのものと同等以上である必要があります。私たちの経験に基づいて、データをエクスポートするこの方法はPostgresの古いバージョンのサポートされていないバージョンでも動作するため、古いデータをKubernetes内のより良いシステムに移動する機会が得られます。これが、このセクションの例で9.6を使用した主な理由です。この領域で問題が発生した場合は、ご連絡をお待ちしております。
microservice
タイプを使用するときは、いくつか注意する必要があります。
インポートするデータを含む既存のPostgreSQLインスタンスをポイントする
externalClusterが必要です。詳細については、 :ref:``externalClusters` セクション <externalClusters セクション>` を参照してください。オペレーション中にKubernetesクラスターと
externalClusterの間でトラフィックを許可する必要があるソースデータベースへの接続は、
pg_dumpを実行し、ロール情報を読み取る必要がある指定されたユーザーで付与される必要があります スーパーユーザー はOKです現在、
pg_dump -Fd結果はPGDATAボリュームのdumpsフォルダー内に一時的に保存されます。そのため、割り当てられたノードにダンプ結果、復元されたデータとインデックスを一時的に含むための十分な利用可能な領域が必要です。インポート操作が完了すると、このフォルダーはオペレーターによって自動的に削除されます。initdb.import.databases配列内で指定できるデータベースは1つだけですロールはインポートされません - そのため、
initdb.import.roles内で指定できません
Tip
マイクロサービスアプローチは、宛先クラスターのCloudNativePG規約とデフォルトに従います。宛先クラスターに`initdb.database` または`initdb.owner` を設定しない場合、両方のパラメーターはデフォルトの`app` になります。
monolith タイプ
モノリスアプローチでは、ソースクラスターから宛先クラスターにインポートするロールとデータベースのセットを指定できます。操作は次の手順で実行されます。
新しいクラスターの
initdbブートストラップ選択したロールのエクスポートとインポート
pg_dump -Fdを使用して、選択したデータベースinitdb.import.databases内を一度に1つずつエクスポート選択した各データベースを作成し、
pg_restoreを使用してデータをインポートしますインポートされた各データベースで
ANALYZEを実行しますデータベースダンプファイルのクリーンアップ
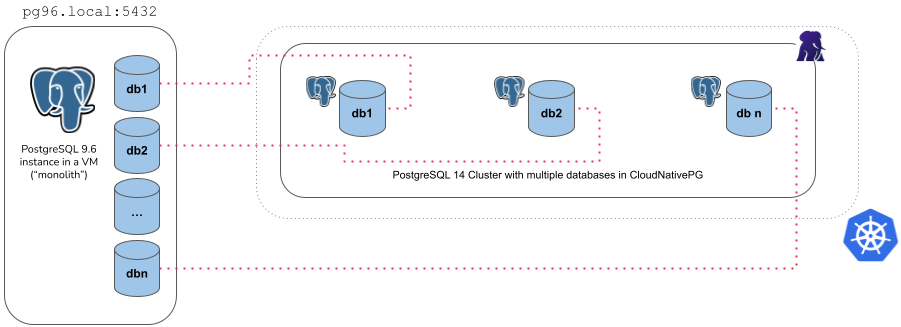
Example of monolith import type
たとえば、以下のYAMLは、 cluster-monolith
と呼ばれる新しい3インスタンスのPostgreSQLクラスターオペレーターがリリースされた時点での利用可能な最新のメジャーバージョンを作成します。
postgres ユーザーを使用してpostgres
データベースに接続し、cluster-pg96-superuser
シークレットに保存されているパスワードを介してpostgres
データベースに接続します。
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: cluster-monolith
spec:
instances: 3
bootstrap:
initdb:
import:
type: monolith
databases:
- accounting
- banking
- resort
roles:
- accountant
- bank_user
source:
externalCluster: cluster-pg96
storage:
size: 1Gi
externalClusters:
- name: cluster-pg96
connectionParameters:
# Use the correct IP or host name for the source database
host: pg96.local
user: postgres
dbname: postgres
sslmode: require
password:
name: cluster-pg96-superuser
key: password
monolith タイプを使用するときは、いくつか注意する必要があります。
インポートするデータを含む既存のPostgreSQLインスタンスをポイントする
externalClusterが必要です。詳細については、 :ref:``externalClusters` セクション <externalClusters セクション>` を参照してください。オペレーション中にKubernetesクラスターと
externalClusterの間でトラフィックを許可する必要があるソースデータベースへの接続は、
pg_dumpを実行し、ロール情報を取得する必要がある指定されたユーザーで付与される必要があります スーパーユーザー はOKです現在、
pg_dump -Fd結果は、宛先クラスターのインスタンスのPGDATAボリュームのdumpsフォルダー内に一時的に保存されます。そのため、割り当てられたノードにダンプ結果、復元されたデータとインデックスを一時的に含むための十分な利用可能な領域が必要です。インポート操作が完了すると、このフォルダーはオペレーターによって自動的に削除されます。initdb.import.databases配列で指定される少なくとも1つのデータベースインポートされたデータベースに必要なロールは、
initdb.import.roles内で指定する必要があります。以下の制限があります。次のロールが存在する場合、インポートされません。
postgres、streaming_replica、cnpg_pooler_pgbouncerSUPERUSERオプションは、インポートされたロールから削除されます
ワイルドカード
"*"は、databasesおよび/またはroles配列の唯一の要素として使用して、その種類のすべてのオブジェクトをインポートできます。データベースを照合する場合、ワイルドカードはpostgresデータベース、テンプレートデータベース、および接続を許可しないデータベースを無視しますクローンプロシージャが完了した後、すべてのデータベースに対して
ANALYZE VERBOSEが実行されます。postImportApplicationSQLフィールドはサポートされていません
Tip
データベースとその所有者は、ソースクラスターに存在するものとまったく同じように保持されます。インポート中に`app` データベースもユーザーも作成されません。 bootstrap.initdb スタンザが、インポートされるデータベースまたはユーザーと一致しないカスタム`database` および`owner` 値を指定している場合、インスタンスマネージャーは、インポートされたデータベースと所有者を変更しないまま、これらの指定された名前で新しい空のアプリケーションデータベースと所有者ロールを作成します。
実際の例
monolith
アプローチを使用して単一のデータベースをインポートすることを妨げるものはありません。そうした場合の結果がmicroservice
アプローチを使用した場合とどのように異なるかを見るのは興味深いです。
ロールme が所有するmydb
という名前のデータベースを使用するソースクラスター、たとえば、
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: cluster-example
spec:
instances: 1
postgresql:
pg_hba:
- host all all all trust
storage:
size: 1Gi
bootstrap:
initdb:
database: mydb
owner: me
microservice を介してインポートできます。
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: cluster-example-microservice
spec:
instances: 1
storage:
size: 1Gi
bootstrap:
initdb:
import:
type: microservice
databases:
- mydb
source:
externalCluster: cluster-example
externalClusters:
- name: cluster-example
connectionParameters:
host: cluster-example-rw
dbname: postgres
モノリス経由と同様に
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: cluster-example-monolith
spec:
instances: 1
storage:
size: 1Gi
bootstrap:
initdb:
import:
type: monolith
databases:
- mydb
roles:
- me
source:
externalCluster: cluster-example
externalClusters:
- name: cluster-example
connectionParameters:
host: cluster-example-rw
dbname: postgres
どちらの場合も、データベースの内容はインポートされますが、
マイクロサービスの場合、インポートされたデータベースの名前と所有者は両方とも
app、またはフィールドの構成のいずれかになりますdatabaseおよびownerがbootstrap.initdbスタンザで設定されています。モノリスの場合、データベースと所有者はソースクラスター、つまりそれぞれ
mydbおよびmeとまったく同じように保持されます。appデータベースもユーザーも作成されません。インポートするソースデータベース/所有者と一致しないbootstrap.initdbスタンザのdatabaseおよびownerのカスタム設定がある場合、インスタンスマネージャーは新しい空のアプリケーションデータベースと所有者ロールを作成しますが、インポートされたデータベース/所有者はそのまま残します。
インポートの最適化
データベースの論理インポート中に、CloudNativePGは、以下を強制することにより、速度とデータの耐久性を優先するためにPostgreSQLの構成を最適化します。
archive_mode〜offfsync〜offfull_page_writes〜offmax_wal_senders〜0wal_level〜minimal
インポートジョブを完了する前に、CloudNativePGは予想される構成を復元し、initdb --sync-only
を実行してデータがディスクに永続的に書き込まれるようにします。
注釈
WALアーカイブ要求された場合、およびデータベースのインポート処理が完了した後にWALレベルが受け入れられます。同様に、レプリカはブートストラップフェーズの後に、実際のクラスターリソースが開始されるときにクローン作成されます。
インポートフェーズ中に実行できる最適化は他にもあります。このトピックはCloudNativePGの範囲を超えていますが、
Cluster 構成でshared_buffers 、max_wal_size
、checkpoint_timeout などのPostgres
GUCを直接調整することにより、チェックポイント領域への不要な書き込みを削減することをお勧めします。
pg_dump およびpg_restore 動作のカスタマイズ
pgDumpExtraOptions およびpgRestoreExtraOptions
パラメーターを使用して追加オプションを指定することにより、pg_dump
およびpg_restore
の動作をカスタマイズできます。これは、パフォーマンスの向上またはインポート/エクスポートの複雑さの管理に特に役立ちます。
たとえば、並列ジョブを有効にすると、データ転送が大幅に高速化されます。
bootstrap:
initdb:
import:
type: microservice
databases:
- app
source:
externalCluster: cluster-example
pgDumpExtraOptions:
- --jobs=2
pgRestoreExtraOptions:
- --jobs=2
ステージ固有のpg_restore オプション
インポートプロセスをより詳細に制御するために、CloudNativePGは次のフェーズでステージ固有のpg_restore
オプションをサポートしています。
pre-data– 例、スキーマ定義data– 例、テーブルの内容post-data– 例、インデックス、コンストレイン、トリガー
フェーズごとにオプションを指定することにより、並列処理を最適化し、復元するオブジェクトの性質に合わせて調整したフラグを適用できます。
bootstrap:
initdb:
import:
type: microservice
schemaOnly: false
databases:
- mynewdb
source:
externalCluster: sourcedb-external
pgRestorePredataOptions:
- --jobs=1
pgRestoreDataOptions:
- --jobs=4
pgRestorePostdataOptions:
- --jobs=2
上記の例では
--jobs=1はpre-dataステージに適用されて、スキーマ作成の順序を保持します。--jobs=4は、dataステージでの並列処理を増加させ、大規模なデータのインポートを高速化します。--jobs=2は、post-dataステージでのパフォーマンスと依存関係の処理のバランスをとります。
これらのステージ固有の設定は、同時実行の調整によってパフォーマンスが大幅に向上する可能性がある大規模なデータベースまたはリソース依存度の環境で特に役立ちます。
注釈
提供される場合、ステージ固有のオプションは一般的な`pgRestoreExtraOptions` より優先されます。
警告
pgDumpExtraOptions 、pgRestoreExtraOptions 、およびすべてのステージ固有のリストアオプション`pgRestorePredataOptions` 、pgRestoreDataOptions 、pgRestorePostdataOptions は、オペレーターによる検証なしで基になるPostgreSQLツールに直接渡されます。特定のフラグは、オペレーターの意図した機能またはデザインと競合する場合があります。これらのオプションは注意して使用し、運用に適用する前に、安全で制御された環境で常に徹底的にテストします。
オンラインインポートとアップグレード
論理レプリケーションは、次のアプローチを使用して、ネットワーク経由でアクセス可能なPostgreSQLデータベースをインポートする強力な方法を提供します。
スキーマのみのオプションを使用したブートストラップのインポート レプリケーションを開始する前に、ターゲットデータベースのスキーマを初期化します。
``Subscription`` リソース 連続レプリケーションを設定してデータ変更を同期します。
この手法は、最小限のダウンタイムでメジャーPostgreSQLのアップグレードを実行するために活用できるため、シームレスな移行とシステムのアップグレードに最適です。
制限やベストプラクティスを含む詳細については、ドキュメントの ロジカルレプリケーションのパブリケーション セクションを参照してください。